Introduccin a la Programacin Paralela Memoria Compartida Casiano
 Casiano Rodríguez León casiano@ull. es Departamento de")










![for(i=0; i<n; i++) for(j=0; j<n; j++) a[j][i] = 0; for(i=0; i<n; i++) for(j=0; j<n;](https://slidetodoc.com/presentation_image_h/e9b7a0e29e68cb6b6d35789428fa80e8/image-12.jpg "for(i=0; i<n; i++) for(j=0; j<n; j++) a[j][i] = 0; for(i=0; i<n; i++) for(j=0; j<n;")


 Each processor has")



 { Task = Get.")
 { Task = Get.")
 • Consists of N processors and a global address space")


 register primary cache secondary cache local main")

 {")
 { p = omp_get_num_threads(); id")
 { p = omp_get_num_threads(); id")
 Search for x= 100 {")
 { p = 0 double local, pi=0. 0, w; long")





 { #pragma omp taskq { #pragma task")




 { FAST int i,")
 { int i, j; if (first <")
 { int i, j; if (first <")
 { int i, j; if (first <")

 { int")
 if (ll_NUMPROCESSORS >")
 void ll_barrier() { 0 0 MASTER { int i, all_arrived;")
 { int ll_group; double ll_first; double ll_last; ll_group = (int)floor(((double)(ngroups*ll_NAME))/((double)ll_NUMPROCESSORS)); ll_first")
 { void **q; MASTER { *ll_FIRST_PRIVATE")

")
 {. . . if")
 { Workers")






 w 1=20, w 2=10 11,")
![1 forall(i=1; i<=3) result(ri+i, si[i]) { 2. . . 3 forall(j=0; j<=i) result(rj+j, sj[j])](https://slidetodoc.com/presentation_image_h/e9b7a0e29e68cb6b6d35789428fa80e8/image-66.jpg "1 forall(i=1; i<=3) result(ri+i, si[i]) { 2. . . 3 forall(j=0; j<=i) result(rj+j, sj[j])")
 • Is Open. MP here to stay? •")
- Slides: 67
Introducción a la Programación Paralela (Memoria Compartida) Casiano Rodríguez León casiano@ull. es Departamento de Estadística, Investigación Operativa y Computación.
Introduction
What is parallel computing? • Parallel computing: the use of multiple computers or processors working together on a common task. – Each processor works on its section of the problem – Processors are allowed to exchange information with other processors Grid of Problem to be solved y CPU #1 works on this area exchange CPU #2 works on this area of the problem CPU #3 works on this area of the problem exchange x CPU #4 works on this area of the problem
Why do parallel computing? • Limits of single CPU computing – Available memory – Performance • Parallel computing allows: – Solve problems that don’t fit on a single CPU – Solve problems that can’t be solved in a reasonable time • We can run… – Larger problems – Faster – More cases
Performance Considerations
SPEEDUP = TIME OF THE FASTEST SEQUENTIAL ALGORITHM TIME OF THE PARALLEL ALGORITHM SPEEDUP NUMBER OF PROCESSORS • Consider a parallel algorithm that runs in T steps on P processors • It is a simple fact that the parallel algorithm can be simulated by a sequential machine in Tx. P steps • The best sequential algorithm runs in Tbest seq Tx. P
Amdahl’s Law • Amdahl’s Law places a strict limit on the speedup that can be realized by using multiple processors. – Effect of multiple processors on run time tn = (f p / P + fs ) t 1 – Effect of multiple processors on speed up 1 = S fs + f p / P – Where • fs = serial fraction of code • fp = parallel fraction of code • P = number of processors
Illustration of Amdahl's Law It takes only a small fraction of serial content in a code to degrade the parallel performance. It is essential to determine the scaling behavior of your code before doing production runs using large numbers of processors 250 fp = 1. 000 fp = 0. 999 fp = 0. 990 fp = 0. 900 200 150 100 50 0 0 50 100 150 Number of processors 200 250
Amdahl’s Law Vs. Reality Amdahl’s Law provides a theoretical upper limit on parallel speedup assuming that there are no costs for communications. In reality, communications will result in a further degradation of performance 80 fp = 0. 99 70 60 50 Amdahl's Law Reality 40 30 20 10 0 0 50 100 150 Number of processors 200 250
Memory/Cache CPU Cache MAIN MEMORY
Locality and Caches Processor L 1 Data Cache L 1 Instruction Cache L 2 Data Cache L 2 Instruction Cache Data Memory Instruction Memory a [i ] = b[ i ]+c[ i] • On uniprocessors systems from a correctness point of view, memory is monolithic, from a performance point of view is not. • It might take more time to bring a(i) from memory than to bring b(i), • Bringing in a(i) at one point in time maight take longer than bringing it in at a later point in time.
for(i=0; i<n; i++) for(j=0; j<n; j++) a[j][i] = 0; for(i=0; i<n; i++) for(j=0; j<n; j++) a[i][j] = 0; a[j][i] and a[j+1][i] have stride n, being n the dimension of a. There is an stride 1 access to a[j][i+1] that occurs n iterations after the reference to a[j][i]. Spatial locality is enhanced if the loops are exchanged Spatial Locality When an element is referenced its neighbors will be referenced too Temporal Locality When an element is referenced, it might be referenced again soon
Shared Memory Machines
Shared and Distributed memory P P P M M M P P P BUS M e m o ry Network Distributed memory - each processor has it’s own local memory. Must do message passing to exchange data between processors. Shared memory - single address space. All processors have access to a pool of shared memory. Methods of memory access : - Bus - Crossbar
Styles of Shared memory: UMA and NUMA Uniform memory access (UMA) Each processor has uniform access to memory - Also known as symmetric multiprocessors (SMPs) Non-uniform memory access (NUMA) Time for memory access depends on location of data. Local access is faster than non-local access. Easier to scale than SMPs
UMA: Memory Access Problems • Conventional wisdom is that systems do not scale well – Bus based systems can become saturated – Fast large crossbars are expensive • Cache coherence problem – Copies of a variable can be present in multiple caches – A write by one processor my not become visible to others – They'll keep accessing stale value in their caches – Need to take actions to ensure visibility or cache coherence
Cache coherence problem P 2 P 1 u=? $ u: 5 P 3 u=? 4 $ 1 u: 5 5 u=7 $ u: 5 2 3 I/O devices Memory • Processors see different values for u after event 3 • With write back caches, value written back to memory depends on circumstance of which cache flushes or writes back value when • Processes accessing main memory may see the old value
Snooping-based coherence • Basic idea: – Transactions on memory are visible to all processors – Processor or their representatives can snoop (monitor) bus and take action on relevant events • Implementation – When a processor writes a value a signal is sent over the bus – Signal is either • Write invalidate tell others cached value is invalid • Write broadcast - tell others the new value
Memory Consistency Models P 0 While (there are more tasks) { Task = Get. From. Free. List(); Task ->data =. . ; insert Task in task queue; } Head = head of task queue; What value is read here? P 1 , P 2 , P 3. . . Pn-1 While (My. Task == NULL) { Begin Critical Section; if (Head != NULL) { My. Task = Head; Head = Head ->Next; } End Critical Section; }. . = My. Task->data;
Memory Consistency Models P 0 While (there are more tasks) { Task = Get. From. Free. List(); Task ->data =. . ; insert Task in task queue; } Head = head of task queue; P 1 , P 2 , P 3. . . Pn-1 While (My. Task == NULL) { Begin Critical Section; if (Head != NULL) { My. Task = Head; Head = Head ->Next; } End Critical Section; }. . = My. Task->data; In some commercial shared memory systems it is possible to observe the old value of My. Task->data!!
Distributed shared memory (NUMA) • Consists of N processors and a global address space – All processors can see all memory – Each processor has some amount of local memory – Access to the memory of other processors is slower • Non. Uniform Memory Access
SGI Origin 2000
Open. MP Programming
Origin 2000 memory hierarchy Level Latency (cycles) register primary cache secondary cache local main memory & TLB hit remote main memory & TLB hit main memory & TLB miss page fault 0 2. . 3 8. . 10 75 250 2000 10^6
Open. MP C and C++ Application Program Interface DRAFT Version 2. 0 November 2001 DRAFT 11. 05 OPENMP ARCHITECTURE REVIEW BOARD • http: //www. openmp. org/ • http: //www. compunity. org/ • http: //www. openmp. org/specs/ • http: //www. it. kth. se/labs/cs/odinmp/ • http: //phase. etl. go. jp/Omni/
Hello World in Open. MP #include <omp. h> parallel region directive int main() { with data scoping clause int iam =0, np = 1; #pragma omp parallel private(iam, np) { #if defined (_OPENMP) np = omp_get_num_threads(); iam = omp_get_thread_num(); #endif printf(“Hello from thread %d out of %d n”, iam, np); } }
#pragma omp parallel private(i, id, p, load, begin, end) { p = omp_get_num_threads(); id = omp_get_thread_num(); load = N/p; begin = id*load; end = begin+load; for (i = begin; ((i<end) && keepon); i++) { if (a[i] == x) { Defines a parallel region, keepon = 0; position = i; be executed by all the } #pragma omp flush(keepon) threads in parallel } } load x? a begin end to
#pragma omp parallel private(i, id, p, load, begin, end) { p = omp_get_num_threads(); id = omp_get_thread_num(); load = N/p; begin = id*load; end = begin+load; for (i = begin; ((i<end) && keepon); i++) { if (a[i] == x) { Defines a parallel region, keepon = 0; position = i; be executed by all the } #pragma omp flush(keepon) threads in parallel } } to
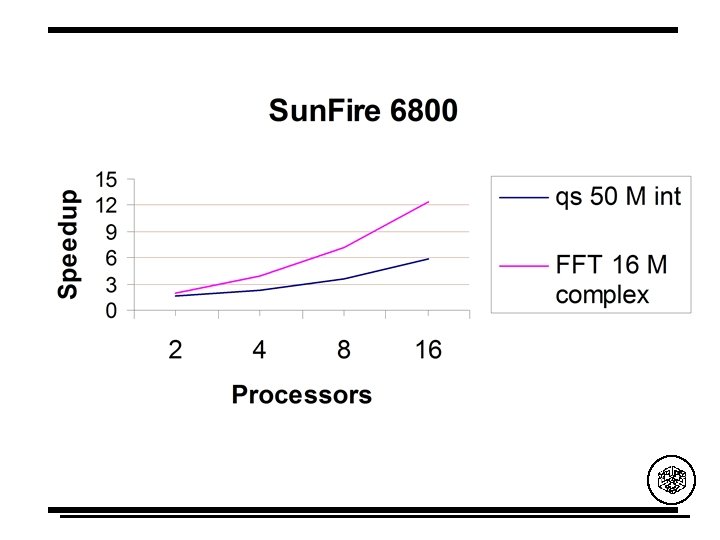
#pragma omp parallel private(i, id, p, load, begin, end) Search for x= 100 { p = omp_get_num_threads(); id = omp_get_thread_num(); load = N/p; begin = id*load; end = begin+load; for (i = begin; ((i<end) && keepon); i++) { P = 10 processors if (a[i] == x) { keepon = 0; position = i; } #pragma omp flush(keepon) } A = (1000, . . . , 901, 900, . . . , 801, . . . , 100, . . . , 1) } The sequential algorithm traverses 900 elements A = (1000, . . . , 901, 900, . . . , 801, . . . , 100. . . , 1) P 0 P 1 P 8 P 9 Processor 9 finds x = 10 in the first step Speedup 900/1 > 10 = P
1 =0<i<N S main() { p = 0 double local, pi=0. 0, w; long i; 4 dx (1+x 2) 4 N(1+((i+0. 5)/N)2) w = 1. 0 / N; #pragma omp parallel private(i, local) { A WS construct #pragma omp single distributes the execution pi = 0. 0; of the statement among #pragma omp for reduction (+: pi) the members of the team for (i = 0; i < N; i++) { local = (i + 0. 5)*w; pi = pi + 4. 0/(1. 0 + local*local); } }
Nested Parallelism
The expression of Nested Parallelism in Open. MP has to conform to these two rules: • A parallel directive dynamically inside another parallel establishes a new team, which is composed of only the current thread unless nested parallelism is enabled. • for, sections and single directives that bind to the same parallel are not allowed to be nested inside each other.
http: //www. openmp. org/index. cgi? faq Q 6: What about nested parallelism? A 6: Nested parallelism is permitted by the Open. MP specification. Supporting nested parallelism effectively can be difficult, and we expect most vendors will start out by executing nested parallel constructs on a single thread. Open. MP encourages vendors to experiment with nested parallelism to help us and the users of Open. MP understand the best model and API to include in our specification. We will include the necessary functionality when we understand the issues better.
A parallel directive dynamically inside another parallel establishes a new team, which is composed of only the current thread unless nested parallelism is enabled. NANOS Ayguade E. , Martorell X. , Labarta J. , Gonzalez M. and Navarro N. Exploiting Multiple Levels of Parallelism in Open. MP: A Case Study Proc. of the 1999 International Conference on Parallel Processing, Aizu (Japan), September 1999. http: //www. ac. upc. es/nanos/
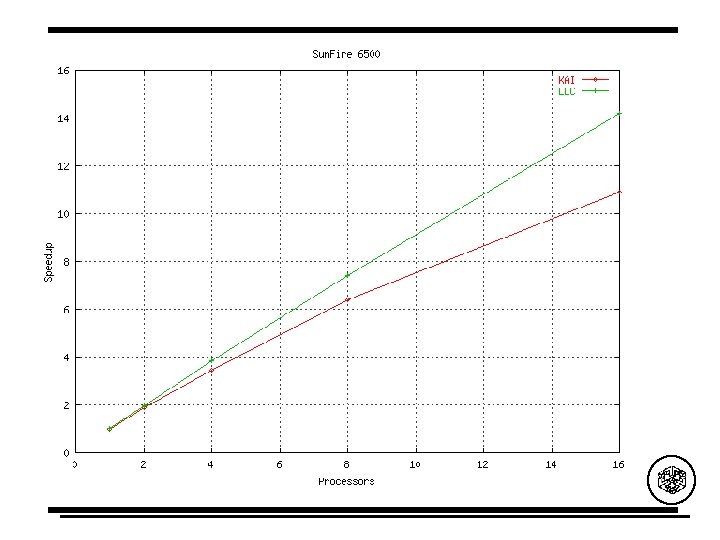
KAI Shah S, Haab G, Petersen P, Throop J. Flexible control structures for parallelism in Open. MP. 1 st European Workshop on Open. MP, Lund, Sweden, September 1999. http: //developer. intel. com/software/products/trans/kai/ Nodeptr list; . . . #pragma omp taskq for ( nodeptr p = list; p != NULL; p = p-< next) { #pragma omp task process(p->data); }
The Workqueuing Model void traverse(Node & node) { #pragma omp taskq { #pragma task process(node. data); if (node. has_left) traverse(node. left); if (node. has_right) traverse(node. right); } } Robert D. Blumofe, Christopher F. Joerg, Bradley C. Kuszmaul, Charles E. Leiserson, Keith H. Randall, Yuli Zhou: Cilk: An Efficient Multithreaded Runtime System. Journal of Parallel and Distributed Computing 37(1): 55 -69 (1996). http: //supertech. lcs. mit. edu/cilk/
A parallel directive dynamically inside another parallel establishes a new team, which is composed of only the current thread unless nested parallelism is enabled. OMNI Yoshizumi Tanaka, Kenjiro Taura, Mitsuhisa Sato, and Akinori Yonezawa Performance Evaluation of Open. MP Applications with Nested Parallelism Languages, Compilers, and Run-Time Systems for Scalable Computers pp. 100 -112, 2000 http: //pdplab. trc. rwcp. or. jp/Omni/
for, sections and single directives that bind to the same parallel are not allowed to be nested inside each other. What were the reasons that led the designers to the constraints implied by the second rule? Simplicity!!
for, sections and single directives that bind to the same parallel are not allowed to be nested inside each other. Chandra R. , Menon R. , Dagum L. , Kohr D. , Maydan D. and Mc. Donald J. Morgan Kaufmann Publishers. Academic press. 2001.
for, sections and single directives that bind to the same parallel are not allowed to be nested inside each other. Page 122: “A work-sharing construct divides a piece of work among a team of parallel threads. However, once a thread is executing within a work-sharing construct, it is the only thread executing that code; there is no team of threads executing that specific piece of code anymore, so, it is nonsensical to attempt to further divide a portion of work using a work-sharing construct. ’’ Nesting of work-sharing constructs is therefore illegal in Open. MP.
Divide and Conquer void qs(int *v, int first, int last) { FAST int i, j; if (first < last) { #pragma ll MASTER partition(v, &i, &j first, last); #pragma ll sections firstprivate(i, j) { #pragma ll section qs(v, first, j); #pragma ll section P 1 qs(v, i, last); } } FOURIER TRANSFORM . . . P 3 QUICK HULL P 2
void qs(int *v, int first, int last) { int i, j; if (first < last) { #pragma ll MASTER partition(v, &i, &j first, last); #pragma ll sections firstprivate(i, j) { #pragma ll section qs(v, first, j); #pragma ll section qs(v, i, last); } } qs(v, first, last) 0 1 2 3 4 qs(v, first, j) 2 0 1 qs(v, first, j) 0 3 4 0 1 2 1 qs(v, i, last) 3 4 . .
void qs(int *v, int first, int last) { int i, j; if (first < last) { #pragma ll MASTER partition(v, &i, &j first, last); #pragma ll sections firstprivate(i, j) { #pragma ll section qs(v, first, j); #pragma ll section qs(v, i, last); } } 0 1 qs(v, first, last) 0 1 2 3 4 0 1 2 qs(v, first, j) 2 qs(v, i, last) 3 4 . .
void qs(int *v, int first, int last) { int i, j; if (first < last) { #pragma ll MASTER partition(v, &i, &j first, last); #pragma ll sections firstprivate(i, j) { #pragma ll section qs(v, first, j); #pragma ll section qs(v, i, last); } } qs(v, first, last) 0 1 2 3 4 . .
Open. MP Architecture Review Board: Open. MP C and C++ application program interface v. 1. 0 - October. (1998). http: //www. openmp. org/specs/mp-documents/cspec 10. ps void qs(int *v, int first, int last) { int i, j; if (first < last) { #pragma ll MASTER partition(v, &i, &j first, last); #pragma ll sections firstprivate(i, j) { #pragma ll section qs(v, first, j); #pragma ll section qs(v, i, last); } } page 14: “The sections directive identifies a non iterative work-sharing construct that specifies a set of constructs that are to be divided among threads in a team. Each section is executed once by a thread in the team. ’’
NWS: The Run Time Library void qs(int *v, int first, int last) { int i, j; void qs(int *v, int first, int last) { if (first < last) { int i, j; #pragma ll MASTER if (first < last) { partition(v, &i, &j first, last); MASTER partition(v, &i, &j, first, last); #pragma ll sections firstprivate(i, j) ll_2_sections( { ll_2_first_private(i, j), #pragma ll section qs(v, first, j), qs(v, first, j); qs(v, i, last) ); #pragma ll section } qs(v, i, last); } } }
NWS: The Run Time Library #define ll_2_sections(decl, f 1, f 2) if (ll_NUMPROCESSORS > 1) { decl; ll_barrier(); { int ll_oldname = ll_NAME, ll_oldnp = ll_NUMPROCESSORS; if (ll_DIVIDE(2)) {f 2; } else { f 1; } ll_REJOIN(ll_oldname, ll_oldnp); } } else { f 1; f 2; }
GROUP BARRIER (ORIGIN STYLE) void ll_barrier() { 0 0 MASTER { int i, all_arrived; 0 1 2 3 do { all_arrived = 1; for (i = 1; i < ll_NUMPROCESSORS; i++) if (!(ll_ARRIVED[i])) all_arrived = 0; } while (!all_arrived); for (i = 1; i < ll_NUMPROCESSORS; i++) ll_ARRIVED[i] = 0; 1 1 } 0 1 2 3 SLAVE { *ll_ARRIVED = 1; while (*ll_ARRIVED) 0 0 ; } 0 1 2 3 }
int ll_DIVIDE(int ngroups) { int ll_group; double ll_first; double ll_last; ll_group = (int)floor(((double)(ngroups*ll_NAME))/((double)ll_NUMPROCESSORS)); ll_first = (int)ceil(((double)(ll_NUMPROCESSORS*ll_group))/((double)ngroups)); ll_last=(int)ceil((((double)(ll_NUMPROCESSORS*(ll_group+1)))/((double)ngroups))-1); ll_NUMPROCESSORS = ll_last - ll_first + 1; ll_NAME = ll_NAME - ll_first; return ll_group; } void ll_REJOIN(int old_name, int old_np) { ll_NAME = old_name; ll_NUMPROCESSORS = old_np; } (A bit) more overhead if weights are provided!
#define ll_2_first_private(ll_var 1, ll_var 2) { void **q; MASTER { *ll_FIRST_PRIVATE = (void *) malloc(2*sizeof(void *)); q = *ll_FIRST_PRIVATE; &ll_var 2 *q = (void *) &(ll_var 1); q ++; &ll_var 1 *q = (void *) &(ll_var 2); *ll_FIRST_PRIVATE } ll_barrier(); SLAVE { ll_FIRST_PRIVATE q = *(ll_FIRST_PRIVATE-ll_NAME); 0 1 memcpy((void *) &(ll_var 1), *q, sizeof(ll_var 1)); q ++; memcpy((void *) &(ll_var 2), *q, sizeof(ll_var 2)); } ll_barrier(); MASTER free(*ll_FIRST_PRIVATE); } 2 3
FAST FOURIER TRANSFORM
void llc. FFT(Complex *A, Complex *a, Complex *W, unsigned N, unsigned stride, Complex *D) { Complex *B, *C; Complex Aux, *p. W; unsigned i, n; if (N == 1) #pragma ll MASTER { A[0]. re = a[0]. re; A[0]. im = a[0]. im; } else { n = (N>>1); #pragma ll sections { #pragma ll section llc. FFT(D, a, W, n, stride<<1, A); #pragma ll section llc. FFT(D+n, a+stride, W, n, stride<<1, A+n)); } B = D; C = D + n; p. W = W; #pragma ll for private(i) for(i=0; i<n; i++) { Aux. re = p. W->re * C[i]. re - p. W->im * C[i]. im; Aux. im = p. W->re * C[i]. im + p. W->im * C[i]. re; A[i]. re = B[i]. re + Aux. re; A[i]. im = B[i]. im + Aux. im; A[i+n]. re = B[i]. re - Aux. re; A[i+n]. im = B[i]. im - Aux. im; p. W += stride; } } }
void kai. FFTdp(Complex *A, . . . , int level) {. . . if (level >= CRITICAL_LEVEL) seq. Dand. CFFT(A, a, W, N, stride, D); else if(N == 1) { A[0]. re = a[0]. re; A[0]. im = a[0]. im; } else { n = (N >> 1); B = D; C = D + n; # pragma omp taskq { # pragma omp task kai. FFTdp(B, a, W, n, stride<<1, A, level+1); # pragma omp task kai. FFTdp(C, a+stride, W, n, stride<<1, A+n, level+1); }
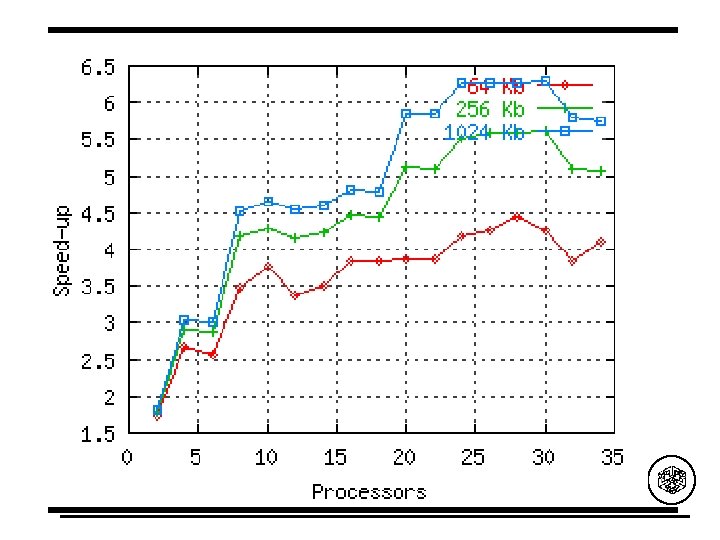
# } pragma omp taskq private(i, Aux, p. W, j, start, end) { Workers = omp_get_num_threads(); CHUNK_SIZE = n / Workers + ((n % Workers) > 0); for(j = 0; j < n; j += CHUNK_SIZE) { start = j * CHUNK_SIZE; end = min(start + CHUNK_SIZE, n); p. W = W + start * stride; # pragma omp task { for(i = start; i < end; i++) {. . . } } /* task */ } } /* taskq */ }
Open. MP: Distributed Memory
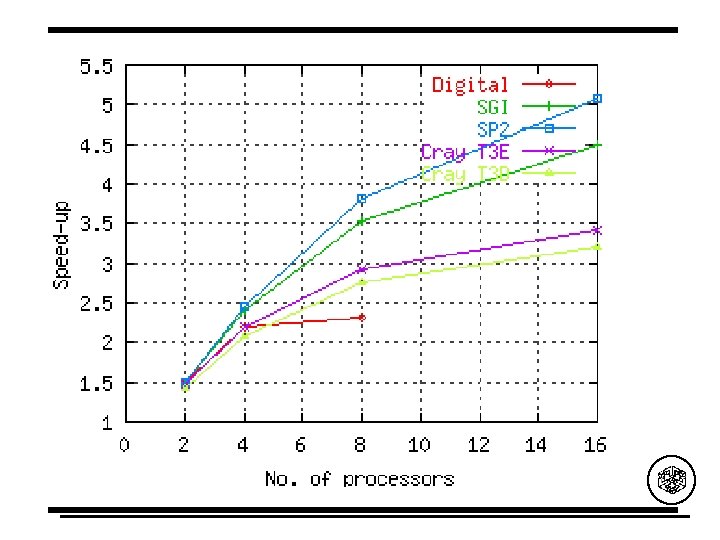
Open. MP: Distributed Memory Barbara Chapman, Piyush Mehortra and Hans Zima Enhacing Open. MP With Features for Locality Control Technical report TR 99 -02, Inst. for Software Technology and Parallel Systems, U. Vienna, Feb. 1999. • http: //www. par. univie. ac. at. C. Amza, A. L. Cox , S. Dwarkadas , P. Keleher , H. Lu , R. Rajamony , W. Yu , W. Zwaenepoel Tread. Marks: Shared Memory Computing on Networks of Workstations IEEE Computer, 29(2), pp. 18 -28, February 1996. • http: //www. cs. rice. edu/~willy/Tread. Marks/overview. html
1 2 3 4 5 6 7 4 6 7 8 #pragma ll parallel for #pragma ll result(ri+i, si[i]) for(i=1; i <= 3; i++){. . . #pragma ll for #pragma ll result (rj+j, sj[j]) for(j=0; j<=i; j++) { rj[j] = function_j(i, j, &sj[j], . . ); } ri[i] = function_i(i, &si[i], . . ); } 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23. . . 0 3 6 9 12 15. . . i=1 1 4 7 10 13 16. . . i=2 2 5 8 11 14 17 20 23. . . i=3
1 2 3 4 5 6 7 4 6 7 8 #pragma ll parallel for #pragma ll result(ri+i, si[i]) for(i=1; i <= 3; i++){. . . #pragma ll for #pragma ll result (rj+j, sj[j]) for(j=0; j<=i; j++) { rj[j] = function_j(i, j, &sj[j], . . ); } ri[i] = function_i(i, &si[i], . . ); } 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23. . . 0 3 6 9 12 15. . . i=1 1 4 i=2 7 10 13 16. . . 2 5 8 11 14 17 20 23. . . i=3 0 6 12. . . 3 9 15. . . 1 10. . . 4 13. . . 7 16. . . 2 14. . . 5 17. . . 8 20. . . 11 23. . . i=1, j=0 i=1, j=1
6 4 7 worker 3 worker 0 1 2 3 4 5 6 7 5 2 0 2 4 0 6 1 3 5 7 1 worker 0 4 2 6 1 3 1 5 7 3 5 7
1 2 3 5 6 7 4 6 7 8 #pragma ll parallel for #pragma ll result(rx+x, sx[x]) for(x=3; x <= 5; x++){ #pragma ll for #pragma ll result (ry+y, sy[y]) for(y =x; y<=x+1; y++) { ry[y] =. . . ; } rx[x] =. . . ; } x=5 x=3 5 y=6 y=5 2 y=4 3 y=3 0 1 y=4 4 x=4 y=5
One Thread is One Set of Processors Model (OTOSP) w 1=20, w 2=10 11, 9 0 1 6, 5 im st d r i F 3 2 4 6, 4 0 5 4 1 5 5, 4 Second division 2 Second dimension First division on i s en 3 sion imen d d n ion a ivis d Third • Each Subset of Processors correspond to one and only one Thread. • A Group is a Family of Subsets. • A Team is a Family of Groups.
1 forall(i=1; i<=3) result(ri+i, si[i]) { 2. . . 3 forall(j=0; j<=i) result(rj+j, sj[j]) { 4 int a, b; 5. . . 6 if (i % 2 == 1) 7 if (j % 2 == 0) 8 send(“j”, j+1, a, sizeof(int)); 9 else receive(“j”, j-1, b, sizeof(int)); 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23. . . 0 3 6 9 12 15. . . i=1 0 6 12. . . 3 9 15. . . i=1, j=0 i=1, j=1 1 4 2 7 10 13 16. . . i=2 5 8 11 14 17 20 23. . . i=3 1 10. . . 4 13. . . 7 16. . . 2 14. . . 5 17. . . 8 20. . . 11 23. . . j=0 j=1 j=2 j=3
Conclusions and Open Questions (Shared Memory) • Is Open. MP here to stay? • Scalability of Shared Memory Machines? • Performance Prediction Tools and Models? • Open. MP for Distributed Memory Machines? • The Work Queuing Model? Pointer • http: //nereida. deioc. ull. es/html/openmp. html