IntraSocket and InterSocket Communication in Multicore Systems Roshan








 is the Intel SIMD instruction.")












- Slides: 31
Intra-Socket and Inter-Socket Communication in Multi-core Systems Roshan N. P S 7 CSB Roll no: 29
Introduction The increasing computational and communication demands of the scientific and industrial communities require a clear understanding of the performance trade-offs involved in multi-core computing platforms. analysis can help application and toolkit developers In designing better, topology aware, communication primitives intended to suit the needs of various high end computing applications. we take on the challenge of designing and implementing a portable intra-core communication framework for streaming computing and evaluate its performance on some popular multi-core architectures developed by
Analysis shows that a single communication method cannot achieve the best performance for all message Sizes The basic memory-based copy method gives good performance for small messages. vector loads and stores provide better performance for medium sized messages. Kernel based approach can achieve better performance for larger messages.
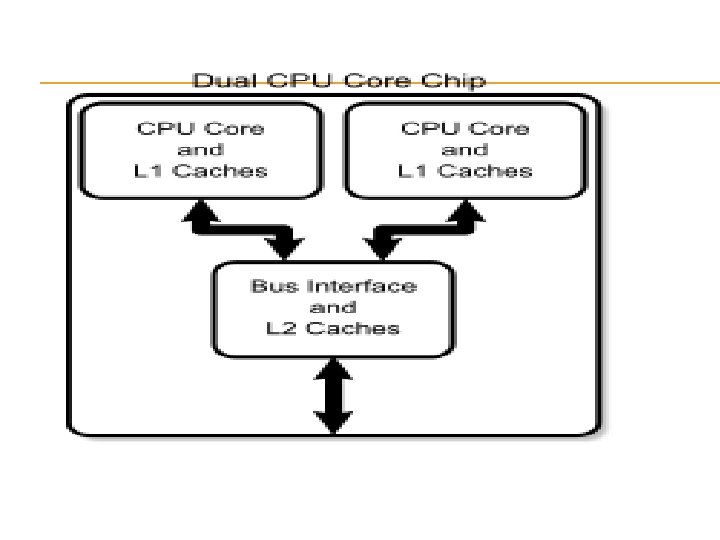
Multi-core Systems A multi-core processor is a processing system Composed of two or more independent cores. As number cores increase the performance also increase. A many-core processor is one in which the number of cores is large enough that traditional multi-processor techniques are no longer efficient
Now days multi-core processors are used incase of high performance computing. When more and more users attempting to use their distributed workload within a single node or a small set of nodes and it causes a little communication delay , it decrease performances. The hardware support for accelerating it, have become critical to obtain optimal application performance. Because It cause a little communication delay.
The early communication method The inter-node data exchange method such as Myrinet , or Infini. Band. Myrinet : It has less overhead protocols than Ethernet. So it provide better performance , less interface and low latency. It uses two optical fiber. One used for Upstream and other used for Downstream and connected with node with switch It has latency of 5. 5 microsecond and software and
Infiband : It is a high speed interface for server and peripherals. It deal with connection between server to server and peripherals such as storage switches etc. The main disadvantage is software overhead.
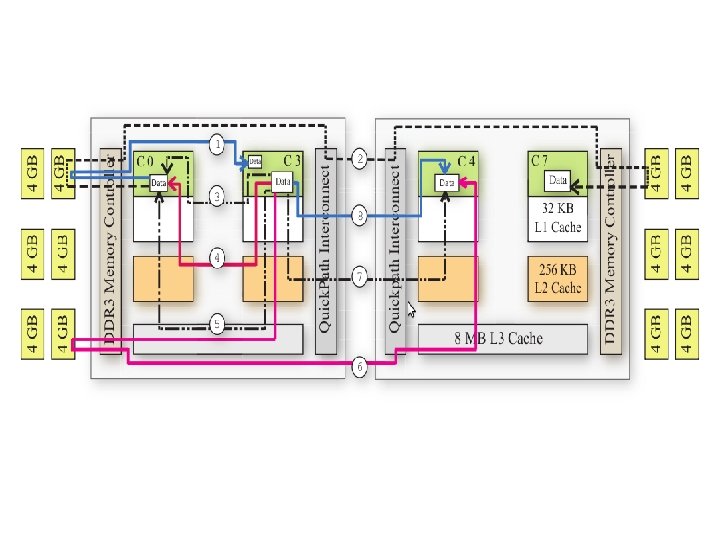
Methodology Here we deals with the approach used to evaluate the communication mechanisms of various multicore architectures. Basic Memory Based Copy We use the basic memcpy function to copy data from the user buffer to the shared communication buffer and back to the user buffer on the receiving side. This form of data transfer would take paths 3 to 8
Vector Instructions The Intel SIMD Extensions 2 (SSE 2) is the Intel SIMD instruction. (ie) Single instruction for multiple data. These instruction are used in case of multiprocessing system. Multiprocessing unit perform same operation on Set on different data.
SSE 2 includes two Vector instruction set one is movdqua and other is movdqu. This instruction transfer 16 Bytes data from source buffer to destination buffer. Movdqua : This instruction requires 16 bytes aligned memory location. Movdqu : This can be either aligned or unaligned. These are shown in 3 to 8 path.
Streaming Instructions SSE 2 includes a set of streaming instructions that do not pollute the cache hierarchy. The streaming instructions would follow paths 1 and 2, There are two streaming instructions available in the SSE 2 instruction set. Movntdt : This is a non-temporal store which copies the data from the source address to the destination address without polluting the cache lines. If data are already in cache, then the cache lines are updated. This instruction is capable of copying 16 bytes
Movnti : This is a non-temporal instruction similar to movntdq except that we only copy 4 bytes Kernel-level Direct Copy The standard memory copy approaches involve two copies to transfer data from the source to the destination buffer. For large messages we opt for a single copy approach with kernel-level memory copies using the Li. MIC 2 library The library abstracts out the memory transfers into a few user level functions.
The kernel-level approach has some costs associated with it as well, like the context switches between the user and kernel space. So this method is not ideal to transfer small or medium sized messages as the overhead caused by the context switches will offset the benefits obtained from reducing one memory copy.
EXPERIMENTAL RESULTS The experimental setup consists of three different platforms. Intel-Nehalem : An Intel Nehalem system with two quad-core sockets operating at 2. 93 GHz with 48 GB RAM and a PCIe 2. 0 interface, running Red Hat Enterprise Linux Server release 5. 2 with Linux 2. 6. 28. AMD-Opteron: A four-socket, quad-core AMD Opteron board operating at 1. 95 GHz with 16 GB RAM and a PCIe 1. 0 interface, running Red Hat Enterprise Linux Server release 5. 4 with Linux 2. 6. 18.
Sun-Niagara: A Sun Ultra. SPARC-T 2 processor with 8 cores on chip. Each core operates at 1. 2 GHz, and supports 8 hardware threads to hide memory latency. In evaluation we use Memcpy, Stream, Vector and, Li. MIC and compiler used GCC or ICC. GCC version 4. 4. 0 and ICC Compiler version 11. 0 were used in the experimental evaluation
GCC compiler The GNU Compiler Collection includes front ends for C, C++, Objective-C, Fortran, Java, GCC was originally written as the compiler for the GNU operating system. The GNU system was developed to be 100% free software, free in the sense that it respects the user's freedom
ICC Compiler Intel C++ Compiler describes a group of C/C++ compilers from Intel. Compilers are available for Linux, Microsoft Windows, and Mac OS X. License : Proprietary Intel supports compilation for its IA-32, Intel 64, Itanium 2, processors and it does not support non-Intel but compatible processors certain AMD processors
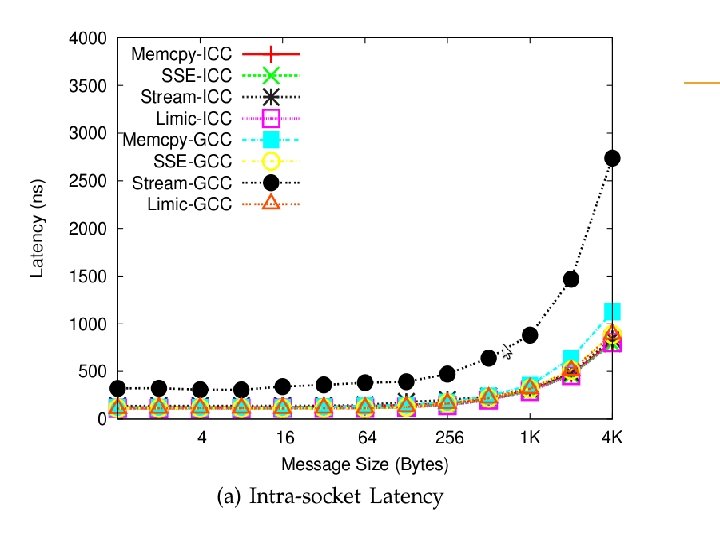
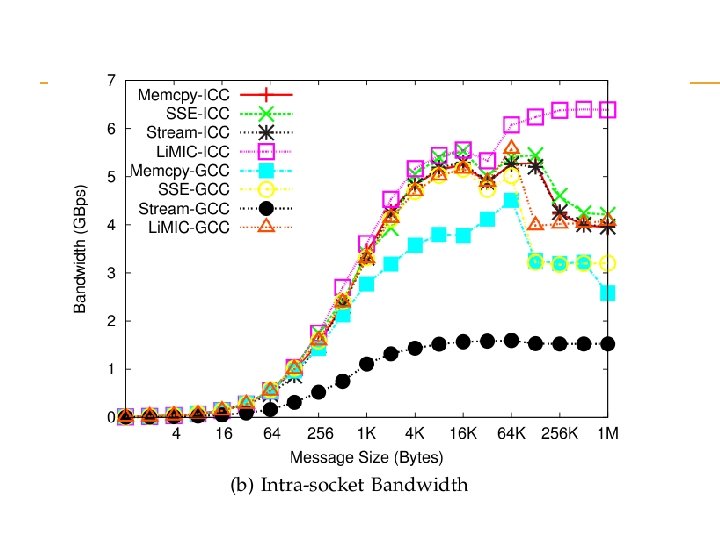
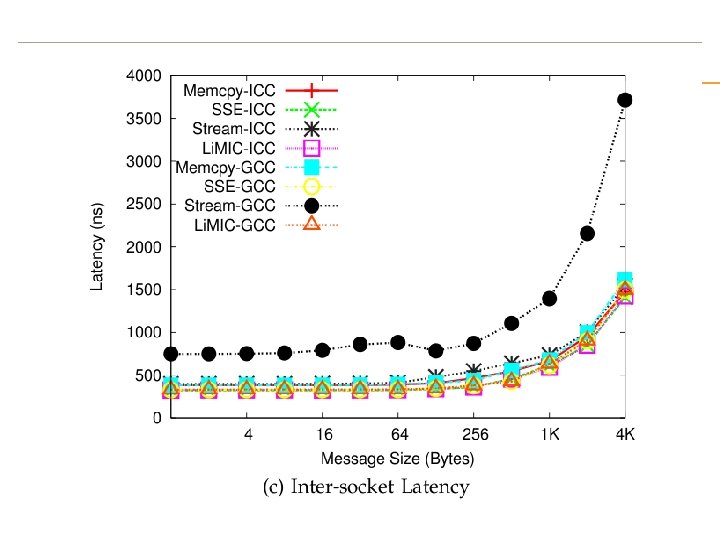
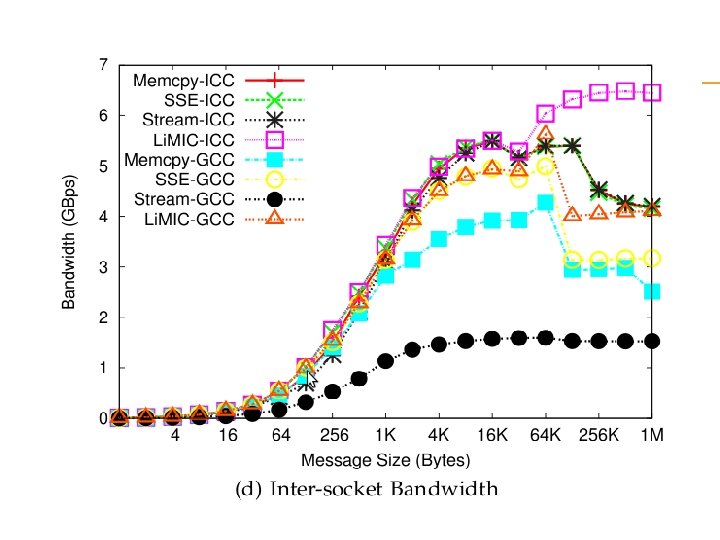
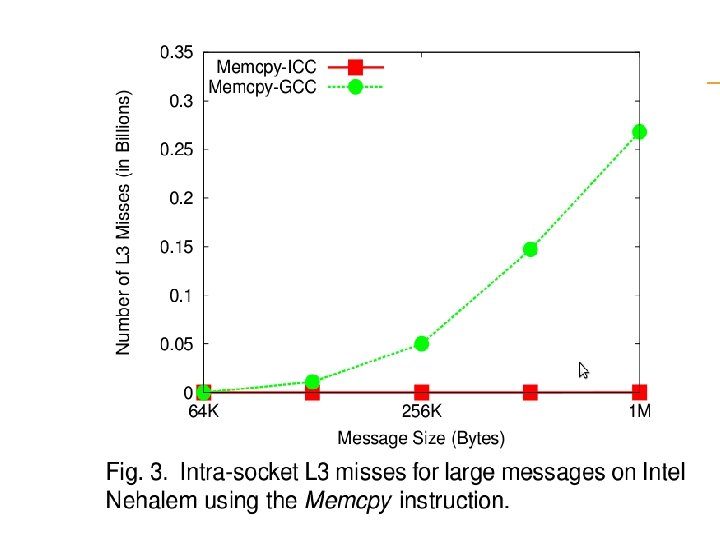
observation memcpy based approaches give best performance for very small messages SSE 2 based approaches give the best performance for small to medium sized messages the kernel based copy approach using Li. MIC gives the best performance for large messages.
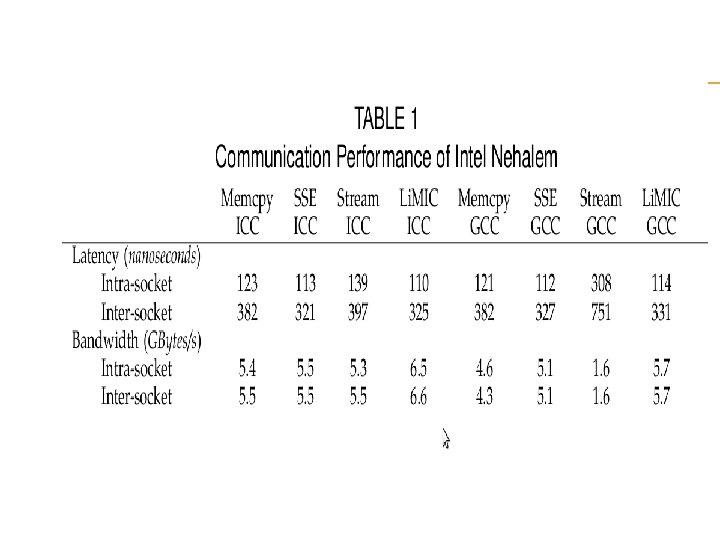
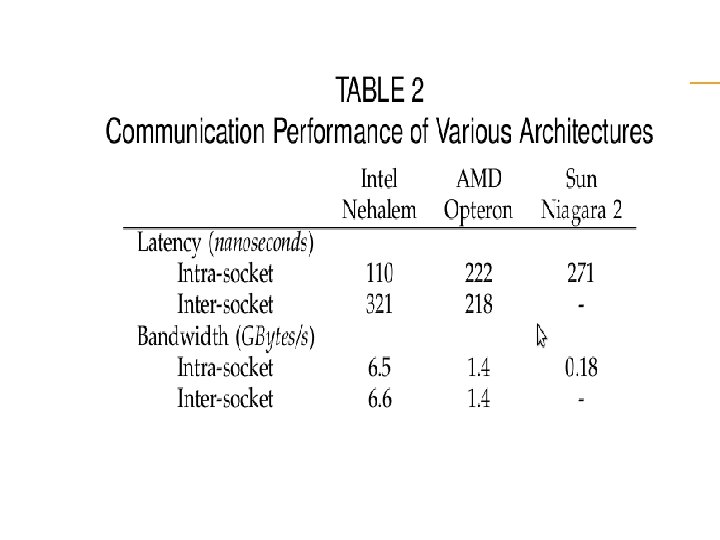
Observation Memcpy-GCC to compare all the architectures as GCC was the only common compiler and memcpy the only instruction available on all the machines used for our experiments, with the exception of the Intel Nehalem where we use Li. MIC 2 with large messages We see that for intra-socket communication, the Intel Nehalem gives the best performance followed by AMD Opteron. Due to technical difficulties, we were not able to gather the inter-socket numbers on the Sun-Niagara.
Conclusion We have also found out that the intra node communication performance is highly dependent on the memory and cache Architecture as we saw from the performance analysis of the basic memory based copy as well as SSE 2 vector instructions. we can achieve an intra-socket small message latency of 120, 222 and 371 nanoseconds on Intel Nehalem, AMD Opteron and Sun Niagara 2, respectively. The inter-socket small message latency for Intel Nehalem and AMD Opteron are 320 and 218 nanoseconds
The maximum intra-socket communication bandwidth obtained were 6. 5, 1. 37 and 0. 179 Gbytes/second for Intel Nehalem, AMD Opteron and Sun Niagara 2. We were also able to obtain an inter-socket communication performance of 1. 2 and 6. 6 Gbytes/second for the AMD Opteron and Intel Nehalem.