Intel Threading Building Blocks Parallel STL Optimization Notice


Содержание • Введение • Intel® Threading Building Blocks • Parallel STL Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Введение Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

C++11/14 std: : async, std: : future std: : thread + manual sync No Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. C++17 std: : async, std: : future Parallel STL (par) Parallel STL (par_unseq) C++2 x Другие решения resumable functions MPI*, Microsoft AAL* Intel® TBB flow graph, Qualcomm Symphony*, etc Task Block for_loop Open. MP*, Intel® TBB, Nvidia Thrust, Microsoft PPL*, Open. CL*, etc Parallel STL (unseq, vec) intrinsics, autovectrorization, Parallel STL by Intel®, Open. MP* 4, etc

Intel® Threading Building Blocks Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks Dreamworks Fur Shader used Intel® TBB which produced an average of 5 x speedup on fur generation loop “Using Intel TBB’s new flow graph feature, we accomplished what was previously not possible, parallelize a very sizable task graph with thousands of interrelationships – all in about a week. - Robert Link GCAM Project Scientist, Pacific Northwest National Laboratory https: //github. com/01 org/tbb Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. CAD Exchanger


Intel® Threading Building Blocks Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
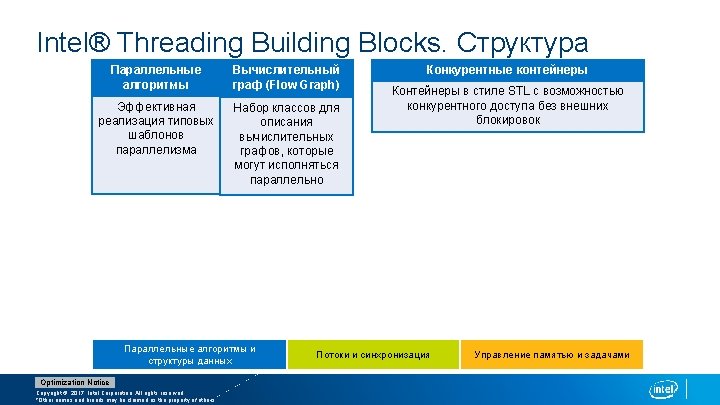
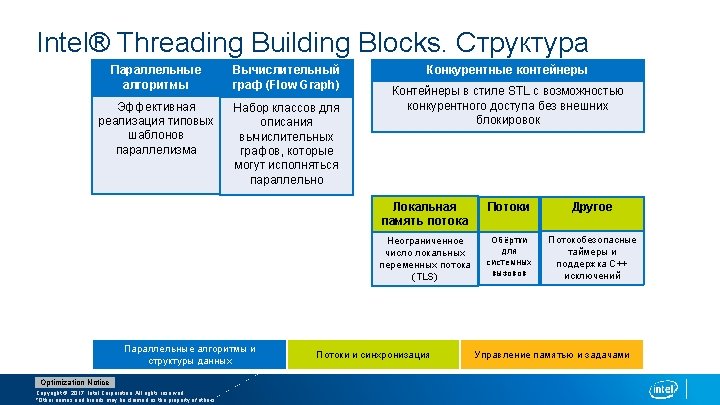
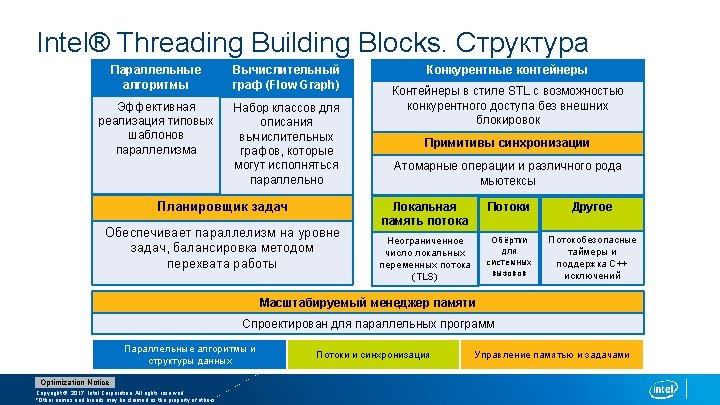

Intel® Threading Building Blocks. Шаблоны параллельных Алгоритмов Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks. Шаблоны параллельных Алгоритмов Loop parallelization Streaming parallel_for parallel_reduce parallel_scan Parallel sorting parallel_sort Parallel function invocation parallel_invoke Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. flow graph parallel_do parallel_for_each pipeline / parallel_pipeline

Intel® Threading Building Blocks. функциональная декомпозиция и Вложенный параллелизм Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks. Шаблон Fork. Для небольшого предопределённого количества Join задач parallel_invoke( func 1, func 2, . . . ); Когда количество задач велико или заранее неизвестно task_group g; . . . g. run( func 1 ); . . . g. run( func 2 ); . . . g. wait(); Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks. Шаблон Reduce При помощи функции parallel_reduce T sum = parallel_reduce( blocked_range<int>(0, n), 0. f, [&](blocked_range<int> r, T s) -> T { for( int i=r. begin(); i!=r. end(); ++i ) s += a[i]; return s; }, std: : plus<T>() ); При помощи класса enumerable_thread_specific<T> sum; parallel_for( 0, n, [&]( int i ) { sum. local() += a[i]; }); T total = s. combine(std: : plus<T>()); Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks. Шаблон Reduce. Начальное значение Способ с parallel_reduce для свёртки string concat = parallel_reduce( blocked_range<int>(0, n), Нейтральный элемент string(), [&](blocked_range<int> r, string s)->string { for( int i=r. begin(); i!=r. end(); ++i ) Свёртка поддиапазона s += a[i]; return s; }, std: : plus<string>() ); Свёртка частичных результатов Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks. шаблон Reduce. Способ с Enumerable_thread_specific Контейнер для thread-local представлений Обращение к локальной копии enumerable_thread_specific<T> sum; . . . parallel_for( 0, n, [&]( int i ) { sum. local() += a[i]; }); T total = sum. combine(std: : plus<T>()); Применение указанной операций для свёртки локальных копий Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 ко всем i [lower, upper) parallel_for(")
Intel® Threading Building Blocks. Шаблон Map Применить functor(i) ко всем i [lower, upper) parallel_for( lower, upper, func ); Применить functor(i), изменяя i с заданным шагом parallel_for( lower, upper, stride, func ); Применить functor(subrange) для набора subrange из range parallel_for( range, func ); Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
![Intel® Threading Building Blocks. Parallel_for. пример void saxpy( float a, float x[], float (&y)[],](http://slidetodoc.com/presentation_image/569e26248beb1bce5ef2394cb15403f9/image-20.jpg "Intel® Threading Building Blocks. Parallel_for. пример void saxpy( float a, float x[], float (&y)[],")
Intel® Threading Building Blocks. Parallel_for. пример void saxpy( float a, float x[], float (&y)[], size_t n ) { tbb: : parallel_for( size_t(0), n, [&]( size_t i ) { y[i] += a * x[i]; }); } void saxpy( float a, float x[], float (&y)[], size_t n ) { size_t grain_size = 1000; tbb: : parallel_for( tbb: : blocked_range<size_t>(0, n, grain_size), [&]( tbb: : blocked_range<size_t> r ) { for( size_t i = r. begin(); i != r. end(); ++i ) y[i] += a * x[i]; } ); } Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks. Parallel_for. 2 -d Пример // serial for( int i=0; i<m; ++i ) for( int j=0; j<n; ++j ) a[i][j] = f(b[i][j]); Декомпозиция «плиткой» - в 2 D - может приводить к лучшей локальности данных, чем вложенные параллельные циклы в 1 D. tbb: : parallel_for( tbb: : blocked_range 2 d<int>(0, m, 0, n), [&](tbb: : blocked_range 2 d<int> r ) { int i, j; for(i = r. rows(). begin(); i != r. rows(). end(); ++i) for(j = r. rows(). begin(); j != r. cols(). end(); ++j ) a[i][j] = f(b[i][j]); } ); Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Intel® Threading Building Blocks. Элементы балансировки нагрузки Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 [Data, Data+N/2)")
Intel® Threading Building Blocks. Элементы балансировки нагрузки Рекурсивная декомпозиция задач [Data, Data+N) [Data, Data+N/2) [Data, Data+N/k) [Data, Data+Grain. Size) Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. [Data+N/2, Data+N) Доступные для перехвата задачи
 [Data, Data+N/2) [Data+N/2,")
Intel® Threading Building Blocks. Элементы балансировки нагрузки Рекурсивная декомпозиция задач[Data, Data+N) [Data, Data+N/2) [Data+N/2, Data+N) [Data, Data+N/k) [Data, Data+Grain. Size) Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Поток сначала исполняет задачи «в глубину» , таким образом, пользуясь локальностью данных.
 [Data, Data+N/2) [Data,")
Intel® Threading Building Blocks. Элементы балансировки нагрузки Рекурсивная декомпозиция задач[Data, Data+N) [Data, Data+N/2) [Data, Data+N/k) [Data, Data+Grain. Size) Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. [Data+N/2, Data+N)
 [Data, Data+N/2) [Data,")
Intel® Threading Building Blocks. Элементы балансировки нагрузки Рекурсивная декомпозиция задач[Data, Data+N) [Data, Data+N/2) [Data, Data+N/k) [Data, Data+Grain. Size) Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. [Data+N/2, Data+N)

Parallel stl Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Parallel stl. введение Container Iterator Algorithm std: : vector<float> float* transform #include <algorithm> Parallel STL (С++17) void increment( float *in, float *out, int N ) { using namespace std; transform( in, in + N, out, []( float f ) { return f+1; }); } Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Parallel stl. введение C++11/14 CLP TLP std: : async, std: : future std: : thread + manual sync DLP No Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. C++17 std: : async, std: : future Parallel STL (par) Parallel STL (par_unseq) C++2 x Другие решения resumable functions MPI*, Microsoft AAL* Intel® TBB flow graph, Qualcomm Symphony*, etc Task Block for_loop Open. MP*, Intel® TBB, Nvidia Thrust, Microsoft PPL*, Open. CL*, etc Parallel STL (unseq, vec) intrinsics, autovectrorization, Parallel STL by Intel®, Open. MP* 4, etc
,")
Parallel stl. введение Parallelism TS v 2 C++17 par_unseq SIMD std: : sort(v. begin(), v. end()); threaded unseq par vec seq Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Preserve Fwd. Dep. std: : sort(<execution_policy>, v. begin(), v. end());
, v. end()); // explicitly sequential sort(execution:")
Parallel stl. введение // standard sequential sort(v. begin(), v. end()); // explicitly sequential sort(execution: : seq, v. begin(), v. end()); // permitting parallel execution sort(execution: : par, v. begin(), v. end()); // permitting parallel execution and vectorization as well sort(execution: : par_unseq, v. begin(), v. end()); // Parallelism TS v 2 // permitting vectorization only (no parallel execution) sort(execution: : unseq, v. begin(), v. end()); Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Parallel stl. пример #include <algorithm> #include <execution> void increment( float *in, float *out, int N ) { using namespace std; using namespace std: : execution; transform( par, in + N, out, []( float f ) { return f+1; }); } template <class Execution. Policy, class Input. It, class Output. It, class Unary. Op> Output. It transform(Execution. Policy&& exec, …); Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Parallel stl. Getting started § Установить Intel® C++ compiler или Intel® Threading Building Blocks § Скомпилировать код (C++11 и выше) с опцией векторизации через Open. MP (4. 0 и выше) – Для Intel® C++ compiler достаточно добавить флаг -qopenmp-simd для Linux (/Qopenmp-simd для Windows*). § Указать target-платформу (необязательно) – Для Intel® C++ compiler можно воспользоваться опциями -x. HOST, -x. CORE-AVX 2, -x. MIC-AVX 512 для Linux (/Qx. HOST, /Qx. CORE-AVX 2, /Qx. MIC-AVX 512 для Windows. ) § Слинковать с TBB – Линкуйте с Intel TBB. На Windows это произойдет автоматически; на других платформах добавьте “-ltbb” к опциям компоновщика. Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Parallel stl. Getting started § В коде вашего приложения добавить необходимые заголовочные файлы: #include “pstl/execution” #include “pstl/algorithm” #include “pstl/numeric” #include “pstl/memory” Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.


Gamma correction example Gamma = 0. 7 Gamma = 1. 0 Gamma = 1. 5 void Image: : Apply. Gamma( float g ) { using namespace std; for_each( rows. begin(), rows. end(), [g]( Row &r ) { transform( r. cbegin(), r. cend(), r. begin(), [g]( float v ) { return pow( v, g ); } ); } Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Gamma correction example Using inner parallelization and vectorization void Image: : Apply. Gamma( float g ) { using namespace std; using namespace std: : execution; for_each( rows. begin(), rows. end(), [g]( Row &r ) { transform( par_unseq, r. cbegin(), r. cend(), r. begin(), [g]( float v ) { return pow( v, g ); } ); } Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 performance")
Gamma correction example Using inner parallelization and vectorization Gamma Correction example (Parallel STL) performance on Intel(R) Xeon(R) CPU E 3 -1240 v 5 @ 3. 50 GHz (4 C/8 T) Speed up (higher is better) void Image: : Apply. Gamma( float g ) { One picture of 800 x 600 size using namespace std; using namespace std: : execution; for_each( image. begin(), image. end(), [g]( Row &r ) { transform( par_unseq, r. cbegin(), r. cend(), r. begin(), [g]( float v ) { return pow( v, g ); } ); seq | seq* seq | par_unseq } *Intel(R) Compiler auto vectorization functionality was disabled This is pre-release data and not indicative of final performance numbers Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

General recommendation for using Parallel STL One of general rules: Serial execution time be at least two times more than the overheads on each parallelization level. § Make sure the algorithm is cache-efficient § Vectorize at the innermost level § Parallelize at the outermost level, seek the maximum amount of work to execute in parallel. § Consider parallelizing additional levels if overheads are acceptable Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
")
Gamma correction example Using outer parallelization and inner vectorization Gamma Correction example (Parallel STL) performance on Intel(R) Xeon(R) CPU E 3 -1240 v 5 @ 3. 50 GHz (4 C/8 T) One picture of 800 x 600 size Speed up (higher is better) void Image: : Apply. Gamma( float g ) { using namespace std; using namespace std: : execution; for_each( par, image. begin(), image. end(), [g]( Row &r ) { transform( unseq, r. cbegin(), r. cend(), r. begin(), [g]( float v ) { return pow( v, g ); seq|seq* par|unseq } ); *Intel(R) Compiler auto vectorization functionality was disabled } This is pre-release data and not indicative of final performance numbers Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
,")
Auto-vectorization compiler option // standard sequential, m. b. auto-vectorized w/o side effects for_each(v. begin(), v. end(), functor); // explicitly sequential, m. b. auto-vectorized w/o side effects for_each(execution: : seq, v. begin(), v. end(), functor); // permitting vectorization, m. b. vectorized, m. b. side effects for_each(execution: : unseq, v. begin(), v. end(), functor); A conclusion § You should not be surprised if you have got the same performance with the calls above if functor has simple code § But in the more complicated cases you may have got significant speedup with unseq policy Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Composability idea The application may need to process multiple pictures – Batch – Pipeline – Graph Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 { Image img 1, img 2; //")
Composability idea #include "tbb/parallel_invoke. h" void Function() { Image img 1, img 2; // Prepare img 1 // Prepare img 2 tbb: : parallel_invoke( [&img 1] { img 1. Apply. Gamma( gamma 1 ); }, [&img 2] { img 2. Apply. Gamma( gamma 2 ); } Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 performance on Intel(R) Xeon(R) CPU E 3")
Composability idea Gamma Correction example (Parallel STL) performance on Intel(R) Xeon(R) CPU E 3 -1240 v 5 @ 3. 50 GHz (4 C/8 T) Two pictures of 400 x 300 size each #include "tbb/parallel_invoke. h" Speed up (higher is better) void Function() { Image img 1, img 2; // Prepare img 1 // Prepare img 2 tbb: : parallel_invoke( [&img 1] { img 1. Apply. Gamma( gamma 1 ); }, [&img 2] { img 2. Apply. Gamma( gamma 2 ); } Processed one by ); one } This is pre-release data and not indicative of final performance numbers Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Processed in parallel
](http://slidetodoc.com/presentation_image/569e26248beb1bce5ef2394cb15403f9/image-45.jpg "// Outermost parallelism provided by TBB tbb: : parallel_for(images. begin(), images. end(), [](image* img)")
// Outermost parallelism provided by TBB tbb: : parallel_for(images. begin(), images. end(), [](image* img) { apply. Gamma(img->rows(), 1. 1); } ); Speed up (higher is better) Composability idea Gamma Correction example (Parallel STL) perfomance on Intel(R) Xeon(R) CPU E 5 -4657 L v 2 @ 2. 40 GHz 10000 pictures of 400 x 300 size each simple for par|unseq parallel_for seq|unseq par|unseq This is pre-release data and not indicative of final performance numbers Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.

Summary § Parallel STL is a significant step in the evolution of C++ toward parallelism § Parallel STL lets developers focus on expressing the parallelism in their applications without worrying about the low-level details of managing that parallelism § Our implementation works well together with Intel Threading Building Blocks parallel patterns § Parallel STL is not a silver bullet. It must be used wisely. To achieve great performance, follow best known practices when modernizing your code Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.




Intel® Threading Building Blocks. Управление Рекурсивное деление на максимально возможную глубину распределением работы parallel_for( range, func, simple_partitioner() ); Глубина деления подбирается динамически parallel_for( range, func, auto_partitioner() ); Деление запоминается и по возможности воспроизводится affinity_partitioner affp; parallel_for( range, func, affp ); Равномерное распределение работы parallel_for( range, func, static_partitioner() ); Optimization Notice Copyright © 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
- Slides: 50