INSTRUCTION SET DESIGN JehanFranois Pris jparisuh edu Chapter










 • Amdahl could undersell IBM by focusing on")
 • IBM 360 series was first series of")




 • Developed in the 60’s but kept almost unchanged for")
 • Instruction set included – 32 -bit operations for scientific")
 • Had multiple instructions formats all with – Mostly")
 • RX (register to/from indexed storage) – 32 bits")
 • SI ( storage and immediate) – 32 bits")
 • SS ( storage to storage) – 48 bits")
 • S ( storage ) – 32 bits with")
 • Flexible and compact – Multiple instruction sizes • Must decode current")
 • RX format: – Memory address is indexed by base register and")
 • Why such a complex addressing format? – Index register was used")

 • Originally stood for Microprocessor without Interlocked Pipeline Stages • First RISC")
 • Owned by SGI from 1992 to 1998 – Until SGI switched")
 –")

 • MIPS uses two’s complement representation for negative numbers: – 00….")


 Unsigne d 0 1 2 3 4")
 U and S 0 1 2 3")
 • Can create problems when we fetch a byte or half-word")



 • Arithmetic instructions – add $sa, $sb, $sc – sub")

 • More arithmetic instructions – addu $s 1, $s 2,")
 • Shift instructions – sll $s 1, $s 0, n")
 • A right shift followed by a logical and can be used")
 • Want to extract bits XY in positions 14 and 15 ?")
 • Register comparison instructions – slt $t 0, $s 3,")
 for big jumps • Jump instructions – jr $s 0")



 •")
 – lw $s 1, a($s 2)")
 •")
 Wait for – sc $t 1,")


 • lui $s 0, n – load upper immediate")
 • Works in combination with ori lui $s 0,")


 • All immediate jump and branch instructions use a very")
 – Immediate field contains a signed number • Can jump")

 – Works well because • PC value is a multiple")
 • beq $s 0, $1 a – Branch on equal")
 opcode rs rt address • Sole operand is a 26")
 opcode rs rt address • Note that jal has an")






 • Before starting the new procedure, we must save the")
 • At call time – addi $sp, -32 # eight")
 • At return time – lw $s 0, 0($sp) #")
 • Procedures that call other procedures – Including themselves: recursive procedures")
 • All saved registers are restored when the procedure returns and")
 • Helps the programmer with – Symbolic names • Arguments of")
 – Pseudo-instructions • To reserve memory locations for data • To")

 • Three explicit operands: – All R format instructions but jr and")
 • Two explicit operands: – All I format instructions involving a load")
 • One explicit operand: – Jump register instruction (jr) – Both J")

 • ARM stands for Advanced RISC Machine • Originally")
 • Used in cell phones, embedded systems, … •")

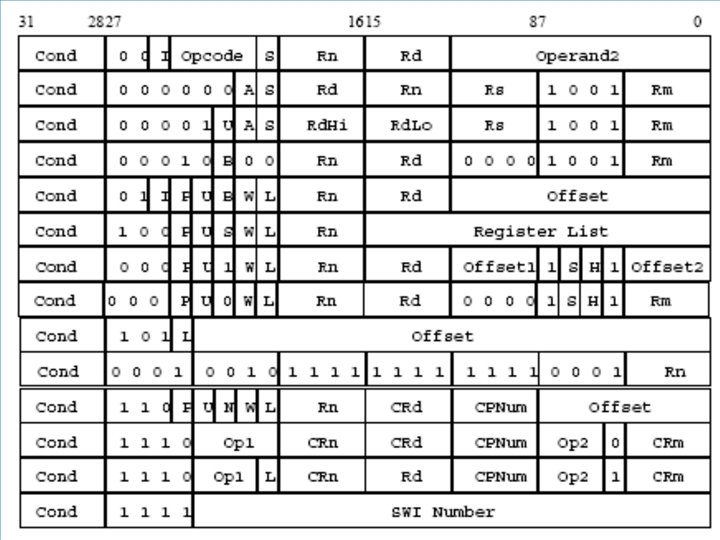
 • Not the result of a well-thought design")
 • New instructions were added over the years,")
 • AMD extended the x 86 architecture to")
 • The result is a huge instruction set")

 • A rarity in microprocessor architecture – Bad solution • Used")
 • Compiled language Source code Compiler Machine code • Machine")
 • Interpreted language Source code Compiler Bytecode Interpreter Bytecode Results")
 • Named registers replaced by a stack of registers • Two")
 • Binary arithmetic and logical operations – Have both operands on")


 • Simplicity favors regularity – As few instruction formats as")
 • We should make the common case faster – PC-relative")
 • Adding more powerful instructions will increase performance – IBM 360 has")
 • Writing programs in assembly language produces faster code than that generated")
 • Backward compatibility prevents instruction sets from evolving – Not true for")
- Slides: 107
INSTRUCTION SET DESIGN Jehan-François Pâris jparis@uh. edu
Chapter Organization • General Overview – Objectives – Realizations • The MIPS instruction set
Importance • The instruction set of a processor is its interface with the outside world – Defined by the hardware – Used by assemblers, compilers and interpreters • Remained very visible to the users up to the 80’s – Earlier PC programs were written in assembler
GENERAL OVERVIEW
Common features • A machine instruction normally consists of – An operation code – One, two or three operand addresses – Various flags • Some operands can be immediate – Address field contains the value of the operand instead of its address
Common features • One or more operands can be in highspeed registers – Dedicated registers: • Very old solution • Register address can be specified in the opcode – General purpose registers
Common features • Memory operand addresses are represented in a compact form – Base + displacement: • The address is specified by the contents of a base register plus a displacement –Saves space because displacement is generally small
Objectives • IS should be – Expressive: • Powerful instructions – Designed for speed: • Should be able to run fast and allow extensive prefetching – Compact: • Faster fetches from disk and from main memory
Objectives – User friendly: • Very important when people were expected to program is assembler –Manufacturers loved that because • Instruction sets were mostly proprietary: IBM 360/370 was the exception • Programs could not be ported
The story of Gene Amdahl • Raised on a farm without electricity until he went to high school • Ph. D from U Wisconsin-Madison • Became one of the top architects of the IBM/360 series • Had his next design rejected by IBM • Started his own company (Amdahl ) building big mainframes and selling them at a much lower cost than comparable IBM machines
How could they do that? (II) • Amdahl could undersell IBM by focusing on larger "mainframes" • Andahl's computers were air-cooled while IBM's water-cooled – "[D]ecreased installation costs by $50, 000 to $250, 000. " • http: //www. fundinguniverse. com/compan y-histories/amdahl-corporation-history/
How could they do that? (I) • IBM 360 series was first series of computers with – Very different capacities – Same instruction set • IBM pricing policy was keeping computer prices proportional to their capacity – Did not reflect proportionally lower manufacturing cost of high-end
The end of the story • Left Amdahl in 1979 to pursue unsuccessfully several ventures • Amdahl Computers is now part of Fujitsu and focuses on services
Inherent conflicts • Expressiveness vs. Speed – CISC instructions were powerful but microcoded • Compactness vs. Speed – Many instruction sets had instructions of different length – Cannot know start of next instruction before decoding the opcode of current one
What is microcode? • Some machine language below the instruction set – Invisible to the programmer/compiler – Each instruction corresponded to one or more microinstructions – Some architectures allowed the user to program new instructions or a whole new instruction set
AN EXAMPLE: IBM 360/370/…
The 360 architecture (I) • Developed in the 60’s but kept almost unchanged for 30+ years • Thirty-two bit words and 8 -bit bytes • Memory was byte-addressable – Had 24 -bit addresses restricting main memory size to 16 MB (enormous at that time!) – Later extended to 32 then 64 bits
The 360 architecture (II) • Instruction set included – 32 -bit operations for scientific and engineering computing (FORTRAN) – Byte-oriented operations for character processing and decimal arithmetic then judged essential for business applications • Name of series referred to wide range of applications that could run on the machine
IBM 360 instruction set (I) • Had multiple instructions formats all with – Mostly 8 -bit opcodes – 16 general purpose registers • RR (register to register) – 16 bits Opcode R 1 R 2
IBM 360 instruction set (II) • RX (register to/from indexed storage) – 32 bits – Address of memory operand was: contents of base and index registers plus 12 -bit displacement D D 2 Opcode R 1 X 2 B 2
IBM 360 instruction set (III) • SI ( storage and immediate) – 32 bits – Has an 8 -bit wide immediate field I – Address of memory operand was: contents of base register B plus 12 -bit displacement D Opcode I B D
IBM 360 instruction set (IV) • SS ( storage to storage) – 48 bits – Two memory operands • First addresses of fields of length L Opcode L B 1 D 1 B 2 D 2
IBM 360 instruction set (V) • S ( storage ) – 32 bits with a 16 -bit opcode – Mostly for privileged instructions Opcode B D
Discussion (I) • Flexible and compact – Multiple instruction sizes • Must decode current instruction to know start of the next one • Regular design • Many operations can be RR, RS, RX, SI and SS (character manipulation and decimal arithmetic)
Discussion (II) • RX format: – Memory address is indexed by base register and index register • a[i] can be decomposed into –Current base register –Offset of a[0] relative to base register –Index i multiplied by size of array element in index register
Discussion (III) • Why such a complex addressing format? – Index register was used to access arrays – Base register allowed for a much shorter address field • 4 bits for base register + 12 bits for displacement vs • 24 bits for a full address
THE MIPS INSTRUCTION SET
MIPS (I) • Originally stood for Microprocessor without Interlocked Pipeline Stages • First RISC microprocessor • Development started in 1981 under John Hennessy at Stanford University • Started a company: MIPS Computer Systems, Inc.
MIPS (II) • Owned by SGI from 1992 to 1998 – Until SGI switched to the Intel Itanium architecture • Used by used by DEC, NEC, Pyramid Technology, Siemens Nixdorf, Tandem and others during the late 80 s and 90 s – Until Intel Pentium took over • Now primarily used in embedded systems
Overview • Two versions – MIPS 32 with 32 -bit addresses (discussed here) – MIPS 64 with 64 -bit addresses • Both MIPS architectures have – Thirty-two registers (32 bits on MIPS 32) – A byte-addressable memory
Bit ordering • All examples assume that byte-ordering is little-endian: – Bits are numbered from right to left 31 0
Number representation (I) • MIPS uses two’s complement representation for negative numbers: – 00…. 0 represents 0 – 00…. 1 represents 1 – 01…. 1 represents 2 n– 1 – 10…. 0 represents – 2 n– 1 – 11…. 1 represents – 1
Two-complement representation • Assume n-bit integers – All positive integers have first bit equal to zero – All negative integers have first bit equal to one • To negate an integer, we compute its complement to 2 n in unsigned arithmetic
Example • Assume n = 4 – 0000, 0001, 0010, 0011, 0100, 0101, 0110 and 0111 represent integers 0 to 7 – To find the representation of -3, we do • 16 -3 = 13, that is, 1101 – More generally 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111 represent negative integers -8 to -1
Another way to look at it (I) Unsigne d 0 1 2 3 4 5 6 7 Unsigne d 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 8 9 10 11 12 13 14 15
Another way to look at it (II) U and S 0 1 2 3 4 Unsigne Signed d 0000 1000 8 = 16 - 8 0001 1001 9 = 16 - 7 0010 10 = 16 6 0011 11 = 16 5 0100 12 = 16 4 -8 -7 -6 -5 -4
Number representation (II) • Can create problems when we fetch a byte or half-word into a 32 bit register • If we fetch the 16 -bit half-word 100…… 101 • we have two possible outcomes all zeroes 100…… 101 (unsigned) all ones 100…… 101 (signed)
MIPS instruction set • Designed for speed and prefetching ease • All instructions are 32 -bit long – Five instruction formats • Three basic formats –R, I and J • Two floating point formats –FR and FJ
The R format opcode rs rt rd shamt funct • Six-bit opcode • R instructions have three operands • Five bits per register 32 registers – Shamt specifies a shift amount (5 bits) – Funct selects the specific variant of operation defined in opcode (6 bits) • Many R instructions have an all-zero opcode
Register naming conventions • $s 0, $s 1, …, $s 7 for saved registers – Saved when we do a procedure call • $t 0, …, $t 9 for temporary registers – Not saved when you do a procedure call • $0 is the zero register: – Always contains zeroes • Other conventions are used for registers used in procedures calls
R format instructions (I) • Arithmetic instructions – add $sa, $sb, $sc – sub $sd, $se, $sf • Logical instructions – and $sa, $sb, $sc – or $sd, $se, $sf – nor $sg, $sh, $si i); – xor $sj, $sk, $sl # a = b + c; # d = e – f; # a = b & c; # d = e | f; # g = ~(h | # j=
Notes • MIPS logical instructions are bitwise operations – Implement bitwise & and I operations of C • MIPS has no negation instructions – Use NOR and specify register $0 as one of the two input registers • $0 is hard-wired to contain zero – nor $sk, $sl, $0 # k = ~l;
R format instructions (II) • More arithmetic instructions – addu $s 1, $s 2, $s 3 – subu $s 1, $s 2, $s 3 – Unsigned versions of add and sub – Multiply and divide instructions will be covered later
R format instructions (III) • Shift instructions – sll $s 1, $s 0, n – slr $s 1, $s 0, n • Shift contents of source register $s 0 by n bits to the left (sll) or to the right (slr) • Fill the emptied bits with zero • Store results in destination register $s 1
Notes (II) • A right shift followed by a logical and can be used to extract some specific bits • If we are interested in bits 14 -15 of register $s 0 – We set up a register $s 2 containing 011 two – We do • slr $t 0, $s 0, 14 # use temporary register $t 0
Notes (III) • Want to extract bits XY in positions 14 and 15 ? ? ? ? ? xy? ? ? ? ? • slr $t 0, $s 0, 15 00000? ? ? ? ? xy • and $s 1, $t 0, $s 2 # $s 2 contains mask 00000000000000 xy 011
R format instructions (IV) • Register comparison instructions – slt $t 0, $s 3, $s 4 – sltu $t 0, $s 3, $s 4 • Sets register $t 0 to 1 if $s 3 < $s 4 and to 0 otherwise – slt does a signed comparison – sltu does an unsigned comparison
R format instructions (IV) for big jumps • Jump instructions – jr $s 0 • Jump to address contained in register $s 0 • Since $s 0 can contain a 32 -bit address, the jump can go anywhere – jalr $s 0, $s 1 • Jump to address contained in register $s 0 and save address of next instruction in register $s 1
The I format opcode rs rt constant/address • Last field can be – a 16 -bit displacement: Address of memory operand is the sum of the contents of register rt and this displacement – a 16 -bit constant: Register rt can then specify a second register operand
Discussion • I format contains instructions involving – One register and a memory location – Two registers and an immediate value – Two registers and a jump address relative to the current value of the program counter (PC) • MIPS instruction set uses the same format for three very different instruction styles
Register and memory instructions • Transfer data – To a register: load – From a register: store • No arithmetic instructions as in the IBM/360 IS – All arithmetic and logical operations are either register to register or immediate to register
Register and memory instructions • Load instructions – lbu $s 1, a($s 2) • Load unsigned byte into register $s 1 from memory address obtained by adding the contents of register $s 2 to the address field a – lbhu $s 1, a($s 2) • Load half-word unsigned
Register and memory instructions • Load instructions (cont’d) – lw $s 1, a($s 2) • Load word unsigned – ll $t 1, a($s 2) • Load linked: used with store conditional to implement atomic Wait for locks COSC –The famous spinlocks 4330
Register and memory instructions • Store instructions – sb $s 1, a($s 2) • Store least significant byte – sbh $s 1, a($s 2) • Store least significant half-word – sw $s 1, a($s 2) • Store word
Register and memory instructions • Store instructions (cont’d) Wait for – sc $t 1, a($s 2) COSC 4330 • Store conditional –Always follows a load linked –Fails if value in memory changes since the load linked instruction –Saves contents of $t 1 in memory and sets $t 1 to one if store
Immediate instructions • Immediate value is 16 -bit wide • addi $1, $2, n – Store in register $s 0 the sum of the contents of register $s 1 and the decimal value n • addiu $1, $2, n – Unsigned version of addi • andi $1, $2, n • ori $1, $2, n
Three missing instructions • No subi or subiu – Instead of subtracting an immediate value n we can add a negative value –n • No load immediate – Replaced by ori with a zero value – ori $s 0, $0, ↑n Typo # load value n into in register $s 0 textbook?
Loading 32 -bit constants (I) • lui $s 0, n – load upper immediate – Loads the decimal value n into the 16 most significant bits of register $s 0 lui $s 0, n 16 MSB 16 LSB
Loading 32 -bit constants (I) • Works in combination with ori lui $s 0, m 16 MSB ori $s 0, #0, n 16 LSB
Other immediate instructions • Comparison instructions – slti $t 0, $s 3, n – sltui $t 0, $s 3, n – Both set register $t 0 • To one if $s 3 < sign extended value of n • To zero otherwise – slti does a signed comparison – sltui does an unsigned comparison
Notes • We should use immediate instructions whenever possible – They are faster and use one register less than the equivalent R instructions • To isolate bits 14 -15 of register $s 0, use – slr $t 0, $s 0, 14 – and $s 1, $t 0, 3 # decimal 3 = binary 011
Immediate branch instructions (I) • All immediate jump and branch instructions use a very specific addressing scheme – Use the program counter as base register • Makes sense • Both register fields can be used for conditional branch instructions
Immediate branch instructions (II) – Immediate field contains a signed number • Can jump ahead or behind the address indicated by the current value of the PC + 4 – Address is multiplied by four before being added the. PC value the PC New PC =to. Old + 4 of + 4×n
Why PC + 4 • Because – By the time the MIPS CPU adds 4×nto the PC register, it will contain the address of the next instruction
Immediate branch instructions (III) – Works well because • PC value is a multiple of four as instructions are properly aligned at addresses that are multiple of 4 • Solution extends the range of the jump from 215 B = 32 KB to 217 B = 128 KB – can use J or JR for bigger jumps
Immediate branch instructions (IV) • beq $s 0, $1 a – Branch on equal – Jump to address computed by adding 4×a to the current value of the PC + 4 if the values of registers $s 0 and $s 1 are equal • bne $s 0, $1 a – Branch on not equal
The J format (I) opcode rs rt address • Sole operand is a 26 -bit address • Jump instructions –j a • Unconditionally jump to a new address – jal a • Unconditionally jump to a new address and store address of next
The J format (I) opcode rs rt address • Note that jal has an implicit operand – Register $ra (stands for return address) • Always register 31 • In general, implicit operands – Allow more compact instruction formats
Computing the new address • Obtained as follows – Bits 1: 0 are zero (address is multiple of 4) – Bits 28: 2 come from jump operand (26 bits) – Bits 31: 29 come from PC+4 Allows to jump to anywhere in memory
Observations • The overall philosophy used to design the MIPS instruction set was – Favor simplicity and regularity • Only three instruction formats – Optimize for the more frequent cases • Immediate to register instructions – Make good compromises • …
Comparison with IBM 360 IS IBM 360 • Variable length instructions • Sixteen GP registers • RR format has two register operands • RS format • SI format • SS format MIPS • Fixed-size instructions • Thirty-two GP registers • R format has three register operands • An option of I format • No, but the equivalent of a nonexisting RI format
The stack • Used to store saved registers • LIFO structure starting at a high address value and growing downwards • MIPS software reserves register 29 for the stack pointer ($sp) • We can push registers to the stack and pop them later
The stack Stack pointer sp
Handling procedure calls • MIPS software uses the following conventions – $a 0, … $a 3 are the four argument registers that can be used to pass parameters – $v 0 and $v 1 are the two value registers that can be used to return values – $ra is the register containing the
Simple procedure call (I) • Before starting the new procedure, we must save the registers used by the calling procedures – Not all of them • Save the eight registers $s 0, $s 1, …, $s 7 • Do not save the ten temporary registers $t 0, …, $t 9 • Must also restore these registers when
Simple procedure call (II) • At call time – addi $sp, -32 # eight times four bytes sw $s 7, 28($sp) sw $s 6, 24($sp) Reality Check: sw $s 5, 20($sp) We will only save the sw $s 4, 16($sp) registers that will be sw $s 3, 12($sp) reused by the callee sw $s 2, 8($sp) sw $s 1, 4($sp) sw $s 0, 0($sp
Simple procedure call (III) • At return time – lw $s 0, 0($sp) # restore the registers $s 0 to $s 7 lw $s 1, 4($sp) lw $s 2, 8($sp) lw $s 3, 12($sp) lw $s 4, 16($sp) lw $s 5, 20($sp) lw $s 6, 24($sp) lw $s 7, 28($sp) addi $sp, 32 # eight times four bytes
Nested procedures (I) • Procedures that call other procedures – Including themselves: recursive procedures • Likely to reuse argument registers and temporary registers • Caller will save the argument registers and temporary registers it will need after the call • Callee will save the saved registers of the caller before reusing them
Nested procedures (II) • All saved registers are restored when the procedure returns and the stack is shrunk
The assembler (I) • Helps the programmer with – Symbolic names • Arguments of jump and branch instructions are labels rather than numerical constants beq $s 0, $s 1 done …. done: …
The assembler (II) – Pseudo-instructions • To reserve memory locations for data • To create user-friendly specialized versions of very general instructions –bzero $s 0, address for –beq $s 0, $0, address
A review question Which MIPS instructions involve – Three explicit operands? – Two explicit operands? – One explicit operand?
Answer (I) • Three explicit operands: – All R format instructions but jr and jalr – All I format instructions involving an immediate value but lui – All I format instructions involving a conditional branch
Answer (II) • Two explicit operands: – All I format instructions involving a load or a store – Load upper immediate (lui) – Jump and link to register (jalr)
Answer (III) • One explicit operand: – Jump register instruction (jr) – Both J format instructions • jal has an implicit second operand that it uses to store the return address ($ra)
OTHER EXAMPLES
Another RISC IS: ARM (I) • ARM stands for Advanced RISC Machine • Originally developed as a CPU architecture for a desktop computer manufactured by Acorn in Britain – Now dominates the embedded system market • Company has no foundry – It licenses its products to
Another RISC IS: ARM (II) • Used in cell phones, embedded systems, … • Same 32 -bit instruction formats • Only 8 registers • Nine addressing modes – Including autoincrement • Branches use condition codes of arithmetic unit
Another RISC IS: ARM • All instructions have a 4 -bit condition code allowing their conditional execution – Claimed to faster than using a branch • NO zero register: – Includes instructions like logical not, load immediate, move (R to R)
The x 86 instruction set (I) • Not the result of a well-thought design process – Evolved over the years • 8086 was the first x 86 processor architecture – Announced in 1978 – Sixteen-bit architecture – Assembly language-compatible extension to Intel 8080 (8 -bit
The x 86 instruction set (II) • New instructions were added over the years, mostly by Intel , but also by AMD – Floating-point instructions – Multimedia instructions – More floating-point instructions – Vector computing • 80836 was the first 32 -bit processor – Introduced more interesting instructions
The x 86 instruction set (III) • AMD extended the x 86 architecture to 64 -bit address space and registers in 2003 • Intel followed AMD’s lead the next year
The x 86 instruction set (IV) • The result is a huge instruction set combining – Old instructions kept to insure backward compatibility • “Golden handcuff” – Newer 32 -bit instructions that are in use today
A curious tradeoff • Complexity of x 86 instruction set – Complicates the design of x 86 microprocessors • More work for Intel and AMD architects – Effectively prevents other manufacturers to design and sell x 86 -compatible microprocessors • A mixed blessing for the duopoly
Stack-oriented architectures (I) • A rarity in microprocessor architecture – Bad solution • Used in many interpreted languages – Java virtual machine, Python – Big exceptions are Dalvik and Lua • Register-based virtual machines
Interpreted vs. Compiled (I) • Compiled language Source code Compiler Machine code • Machine code is directly executable
Interpreted vs. Compiled (II) • Interpreted language Source code Compiler Bytecode Interpreter Bytecode Results
Stack-oriented architectures (II) • Named registers replaced by a stack of registers • Two basic operations: • PUSH <address> push on stack contents of memory address • POP <address> pop top of stack and store it at specified memory address
Stack-oriented architecture (III) • Binary arithmetic and logical operations – Have both operands on the top of the stack – Replace them by the result • Example: B A+B A … …
Tradeoff • Advantages – Simple compilers and interpreters – Very compact object code • Main disadvantage – More memory references • Cannot save partial results into a register
CONCLUSION
Good design principles (I) • Simplicity favors regularity – As few instruction formats as possible for easier decoding • Smaller is faster – No complicated instructions
Good design principles (II) • We should make the common case faster – PC-relative addressing for branches • Good design requires good compromises – Limiting address displacements and immediate values to 16 bits ensures that all instructions can fit in a 32 -bit word
Myths (I) • Adding more powerful instructions will increase performance – IBM 360 has an instruction saving multiple registers – DEC VAX has an instruction computing polynomial terms • These complex instructions limit pipelining options
Myths (II) • Writing programs in assembly language produces faster code than that generated by a compiler – Compilers are now better than humans for register allocations • In addition, programs written in assembly language cannot be ported to other CPU architectures – Think of Macintosh programs
Myths (III) • Backward compatibility prevents instruction sets from evolving – Not true for x 86 architecture • Can add new instructions • Write compilers that avoid the older instructions