Incremental Mining Association Rules 415 Association Rules Mining



, B(6),")


, B(6), C(6), D(3), E(4),")
, F(3) P 1 A(6), B(6), C(6), E(4) Q 2 AE(2), CE(2)")
, F(4) P 1 A(4), B(5), C(5), E(5) Q 2 AE(1), CE(1)")











- Slides: 22
Incremental Mining Association Rules 報告人: 楊士賢 4/15
假如我想做 Association Rules Mining ? • • min_support=40% 透過 Apriori Algorithm C 1={A(6), B(6), C(6), D(3), E(4), F(3)} S 1={A(6), B(6), C(6), E(4)} C 2={AB(4), AC(4), AE(2), BC(4), BE(4), CE(2)} S 2={AB(4), AC(4), BE(4)} C 3={ABC(3)}
資料變動後,假如我想再 做一次做 Association Rules Mining ? • • • min_support=40% 透過 Apriori Algorithm C 1={A(4), B(5), C(5), D(5), E(5), F(4)} S 1={A(4), B(5), C(5), D(5), E(4), F (4)} C 2={AB(2), AC(3), AD(2), AE(1), AF(1), BC(2), BD(4), BE(4), CE(2)…} • S 2={BD(4), BE(4), DE(4)} • C 3={BDE(3)}
• • • min_support=40% 透過 Apriori Algorithm C 1={A(6), B(6), C(6), D(3), E(4), F(3)} S 1={A(6), B(6), C(6), E(4)} C 2={AB(4), AC(4), AE(2), BC(4), BE(4), CE(2)} • S 2={AB(4), AC(4), BE(4)} • C 3={ABC(3)} Q 1 D(3), F(3) P 1 A(6), B(6), C(6), E(4) Q 2 AE(2), CE(2) P 2 AB(4), AC(4), BE(4) Q 3 ABC(3) Q : 是 candicate itemset 但不是frequent itemset P : 是 candicate itemset 也是 frequent itemset
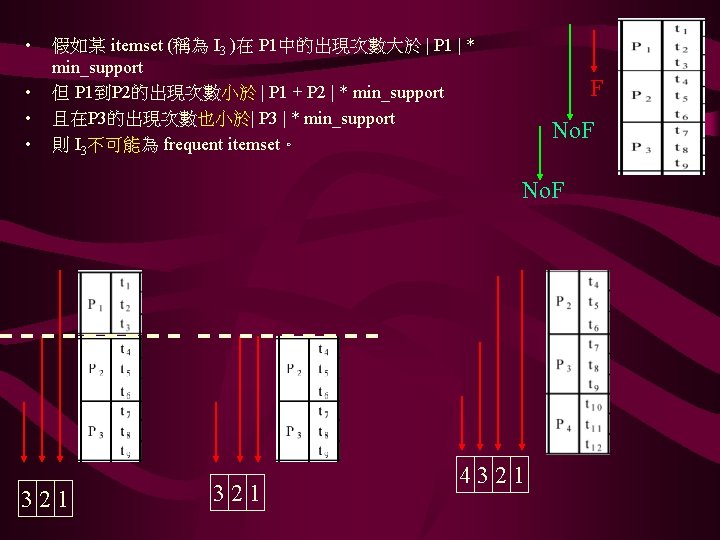
Q 1 D(3), F(3) P 1 A(6), B(6), C(6), E(4) Q 2 AE(2), CE(2) P 2 AB(4), AC(4), BE(4) Q 3 ABC(3) 變更 Q 1 D(5), F(4) P 1 A(4), B(5), C(5), E(5) Q 2 AE(1), CE(1) P 2 AB(2), AC(3), BC(2), BE(3) Q 3 ABC(1) 我們只要掃過 – 和 + 即可知道這些 itemset 的新 Support 值。
Q 1 D(5), F(4) P 1 A(4), B(5), C(5), E(5) Q 2 AE(1), CE(1) P 2 AB(2), AC(3), BC(2), BE(3) Q 3 ABC(1) C 1 A, B, C, D, E, F S 1 A, B, C, D, E, F C 2 AB, AC, AD, AE, AF, BC, BD, BE, BF, CD, CE, CF, DE, DF, EF, S 2 BD, BE, DE C 3 BDE
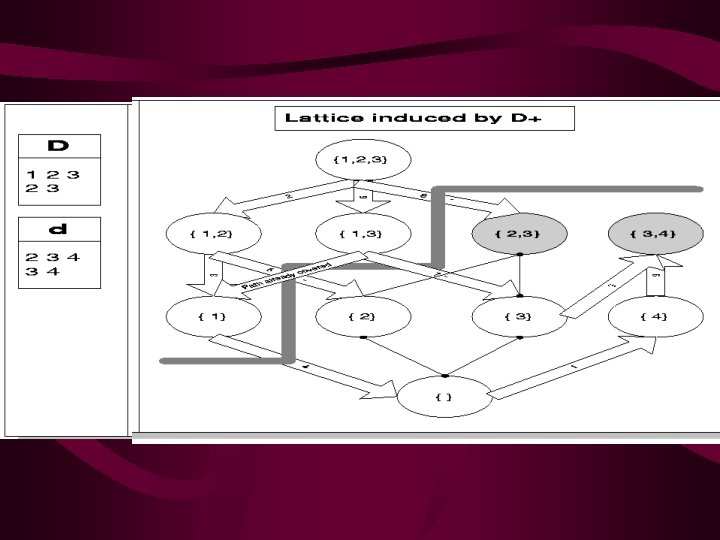
PELICAN & MAAP Algorithm • PELICAN & MAAP Algorithm 都是在 2001年發表的論 文,兩篇論文的作者皆認為所謂 “ 重要的frequent itemset ” ,指的是那些 maximum frequent itemsets,所 以在 mining 的時候,只需算出哪些是 maximum frequent itemsets 即可。 • 在做法上是屬於 FUP 家族,而 PELICAN 和 MAAP 的 不同點在 PELICAN 是利用 latice 的做法,而 MAAP 則是利用 apriori 的方式。(其實 latice 也是 apriori 的一 種 ,資料結構不同)
Min_support=50%
FUP + Sliding Window • FUP 的目的在降低 candicate itemset 的數目,以縮短 scan 資料庫的時間。 • Sliding Window 目的在快速的產生數目接近 的 2 freqeunt itemset 的 2 -candicate itemset,以縮短 mining 時間。 • FUP + Sliding Window : 先以 Sliding Window 快速的產生長度為 2的 candicate itemset ,在利用 FUP 降低長度大於 2的 candicate itemset 數目,以縮短 scan 資料庫的時間。
Experiment |D| Transaction No. in the database 100 | + | The added transaction No. 10 | – | The deleted transaction No. 10 |d| The incremental transaction No. 10 |T| Average size of the transactions 10 |I| Average No. of frequent itemsets 4 |L| No. of frequent itemsets 2000 N Number of items 10000 T 10 -I 4 -D 100 -d 10
T 10 -I 4 -D 100 -d 10 0. 1%
References • David W. Cheung, S. D. Lee, Benjamin Kao, “A General Incremental Techniques for Maintaining Discovered Association Rules”, Proceedings of the 5 th international conference on database systems for advanced applications, Melbourne, Australia, Apr. 1 -4, 1997 • Chang-Hung Lee, Cheng-Ru Lin, and Ming-Syan Chen, “Sliding-Window Filtering: An Efficient Algorithm for Incremental Mining”, ACM CIKM 2001 • Zequn Zhou, “A Low-Scan Incremental Association Rule maintenance Method Based on the Apriori Property”, AI 2001 • A. Veloso, B. Possas, W. Meira Jr. , M. B. de carvalho, Knowledge Management in Association Rule Mining, ICDM 2001