Importance du rseau dans des architectures MIMD Tout





 : où N est la")

![Les modèles de programmation parallèle - par des données parallèles [HPF] [Open MP] :](https://slidetodoc.com/presentation_image_h2/8a91fb7d9f50235c6701a9ad65c07025/image-23.jpg "Les modèles de programmation parallèle - par des données parallèles [HPF] [Open MP] :")


 MPI_Finalize() MPI_COMM_WORLD MPI_Allreduce(.")
 : La résolution système linéaire")
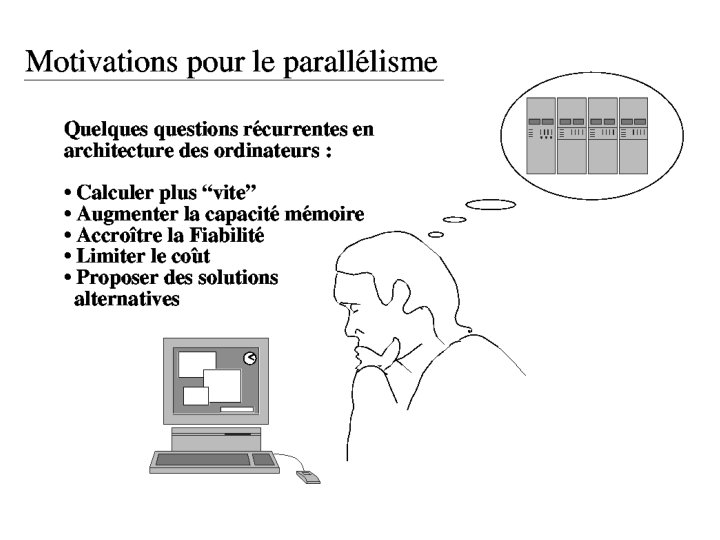
- Slides: 28
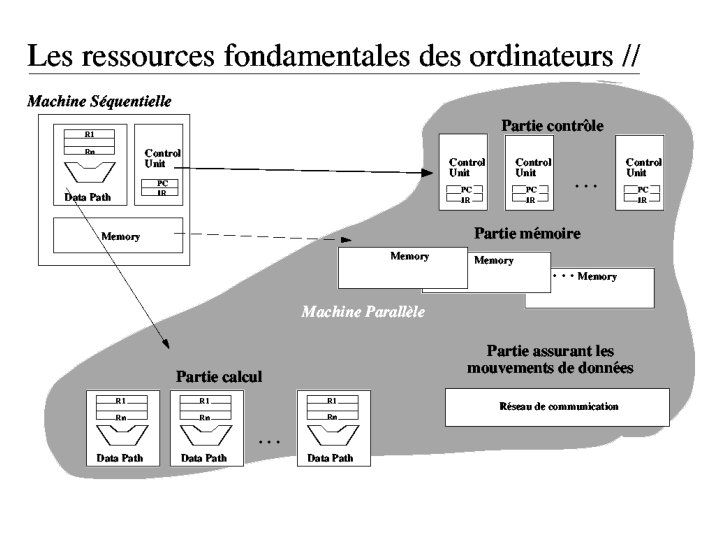
Importance du réseau dans des architectures MIMD Tout échange entre les processeurs nécessite un transfert de données via le réseau d’interconnections des processeurs. Le coût d ’un tel transfert : où d est le nombre de connections directes nécessaire pour passer du processeur i au processeur j.
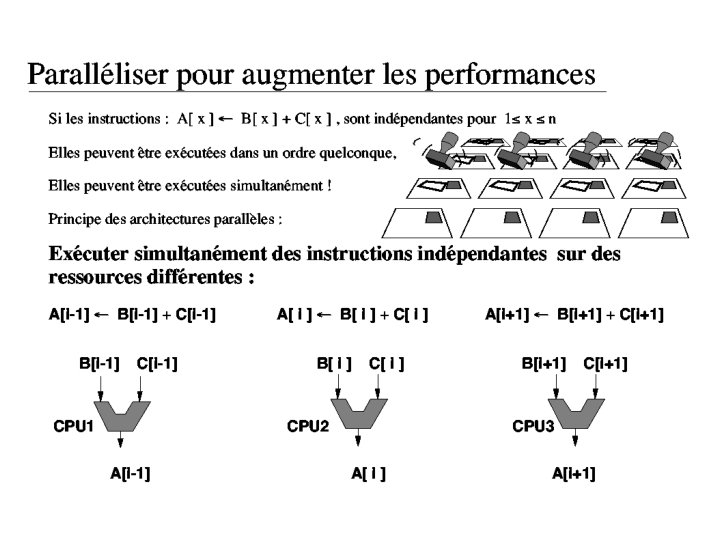
Granularité des applications : C ’est le rapport entre le temps passé par l ’application à effectuer des opérations de calcul et le temps passé dans les communications entre les processeurs : Si ce rapport est élevé l ’application se prête bien au parallèle, au contraire s ’il est faible l ’application sera difficilement parallélisable.
Exemples de programmations parallèles : - réactualisation des données : X=X+ X … - produit scalaire : ps=(X, Y). . .
Critères d’évaluation d’applications parallèles Temps d ’exécution (wall clock) : où N est la taille du problème à traiter et p le nombre de processeurs utilisés Accélération (Speed-up) Sp = Efficacité = La scalabilité est l ’évolution de l’efficacité en fonction du nombre de processeurs.
Les modèles de programmation parallèle - par des données parallèles [HPF] [Open MP] : introduction de nouveaux types de données (vecteur parallèle) et de nouvelles instructions (FORALL). Principalement utilisé sur des machines à mémoire partagée et à adressage unique. Synchronisation importante après chaque instruction scalaire ou parallèle mais implémentation relativement simple. - par échanges de messages [pvm] [mpi] : utilisation de librairies contenant des instructions d ’envois, de réceptions de messages plus des instructions de synchronisation. Le programmeur doit gérer le parallélisme, mais les synchronisations sont moins fréquentes.
Exemple de programmation avec MPI : Proc 0 #include <mpi. h > Proc 1 #include <mpi. h> . . . MPI_Init(. . . ) int a=6, b; int a=12, b; MPI_Send(1, &a, 1, MPI_INT, . . . ) MPI_Recv(0, &b, 1, MPI_INT; . . . ) MPI_Recv(1, &b, 1, MPI_INT, . . . ) MPI_Send(1, &a, 1, MPI_INT, . . . ) cout << b << endl; MPI_Finalize() 12 6
Principales fonctions de la librairie MPI : MPI_Init(. . . ) MPI_Finalize() MPI_COMM_WORLD MPI_Allreduce(. . . ) MPI_Bcast(. . ) MPI_Comm_rank(. . . ) MPI_Comm_size(. . . ) MPI_Isend(…) double MPI_Wtime() MPI_Irecv(. . . ) MPI_Waitall(. . ) MPI_Send(…) MPI_Recv(…) MPI_Barrier(. . . )
Exemple de programmation parallèle (bis) : La résolution système linéaire