ICLR 2016 Generating Sentences from a Continuous Space


 � The standard RNNLM generates sentences one word at a time and")
 � 5")
 � 6")
 � 7")


 � In this section, we present a technique for")
 � Examples of using beam search to impute missing")

 between sentences � The use of a variational autoencoder allows us")
 between sentences � Selected homotopies between pairs of random points in")


 � 訓練VAE示意圖: As close as possible “今晚想chill一下” NN Encoder Z NN Decoder")

 � PPL results of inside testing")
 � WER (%) / PPL results")

 As close as possible “今晚想chill一下” NN Encoder Z NN")
 / PPL results of mixed LMs 3 -gram")
- Slides: 23
ICLR 2016 Generating Sentences from a Continuous Space Samuel R. Bowman, Luke Vilnis, Samy Bengio 史丹佛NLP博士 紐約大學助理教授 數學、經濟學雙學士 麻省大學資 碩士 麻省大學NLP博士 Presenter: 邱世弦 小斑鳩 Google Brain ML科學家
Introduction (1/2) � The standard RNNLM generates sentences one word at a time and does not work from an explicit global sentence representation. � we introduce and study an RNN-based variational autoencoder generative model that incorporates distributed latent representations of entire sentences. � This factorization allows it to explicitly model holistic properties of sentences such as style, topic, and high-level syntactic features. � Naively, maximum likelihood learning in such a model presents an intractable (棘 手的、難駕馭的) inference problem. � Our model circumvents (巧妙地規避) these difficulties using the architecture of a variational autoencoder. 4
Introduction (2/2) � 5
The variational autoencoder (1/2) � 6
The variational autoencoder (2/2) � 7
A VAE for sentences � Our variational autoencoder language model: � We adapt the variational autoencoder to text by usingle-layer LSTM RNNs for both the encoder and the decoder. 8
Results: Language modeling � we report on language modeling experiments on the Penn Treebank in an effort to discover whether the inclusion of a global latent variable is helpful for this standard task. 9
Results: Imputing missing words (1/2) � In this section, we present a technique for imputation and a novel evaluation strategy inspired by adversarial training. � Adversarial evaluation: we evaluate the imputed sentence completions by examining their distinguishability from the true sentence endings. ◦ While the non-differentiability of the discrete RNN decoder prevents us from easily applying the adversarial criterion at train time, we can define a very flexible test time evaluation by training a discriminant function to separate the generated and true sentences, which defines an adversarial error. � We define the adversarial error as the gap between the ideal accuracy of the discriminator (50%, i. e. indistinguishable samples), and the actual accuracy attained. 10
Results: Imputing missing words (2/2) � Examples of using beam search to impute missing words within sentences: � Results for adversarial evaluation of imputations: 11
Sampling from the posterior � 12
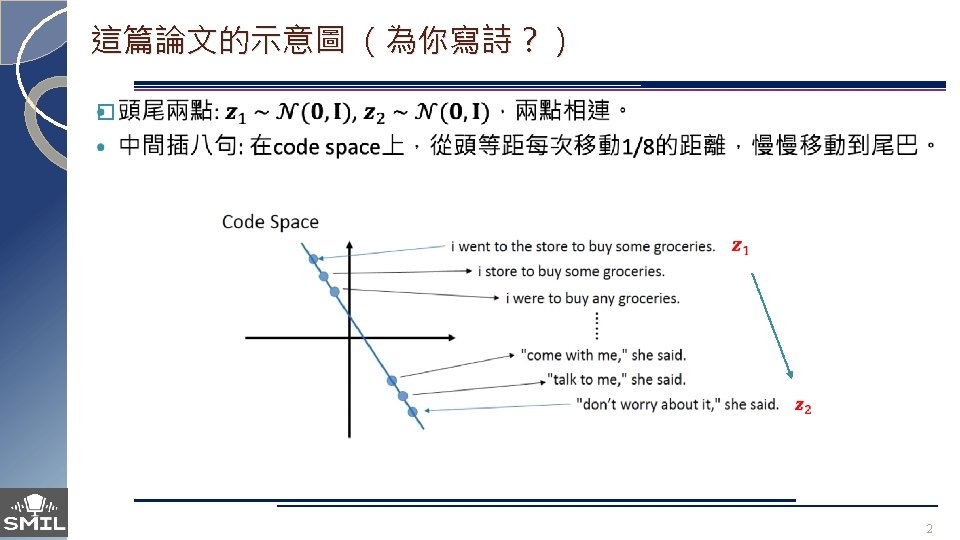
Homotopies (linear interpolation) between sentences � The use of a variational autoencoder allows us to generate sentences using greedy decoding on continuous samples from the space of codes. 13
Homotopies (linear interpolation) between sentences � Selected homotopies between pairs of random points in the latent VAE space: � 反正VAE就是比傳統的Autoencoder產生的句子順就對了。 14
Conclusion and future work � This paper introduces the use of a variational autoencoder for natural language sentences: 1. We present novel techniques that allow us to train our model successfully, and find that it can effectively impute missing words. 2. We analyze the latent space learned by our model, and find that it is able to generate coherent and diverse sentences through purely continuous sampling and provides interpretable homotopies that smoothly interpolate between sentences. � We hope in future work to investigate factorization of the latent variable into separate style and content components: 1. to generate sentences conditioned on extrinsic features. 2. to learn sentence embeddings in a semi-supervised fashion for language understanding tasks like textual entailment (文本蘊含) 3. and to go beyond adversarial evaluation to a fully adversarial training objective. 15
Data augmentation using VAE for codemixing language modeling 2019/12/19 邱世弦 Ref: Samy Bengio et al. , “Generating Sentences from a Continuous Space” (ICLR 2016)
我怎麼搞的 (1/2) � 訓練VAE示意圖: As close as possible “今晚想chill一下” NN Encoder Z NN Decoder “今晚想chill一下” Code (16 -dim vector) 17
Experiments – VAE for code-mixing data generation (1/2) � PPL results of inside testing 3 -gram (A + B). txt C. txt (A + B + C). txt A + B (原來) 65. 09 23. 65 41. 84 A + B + C 71. 91 8. 03 27. 61 71. 34 8. 57 28. 29 65. 64 17. 11 36. 49 19
Experiments – VAE for code-mixing data generation (2/2) � WER (%) / PPL results of mixed LMs 3 -gram jarvis_assistant mmwm 181 A + B (原來) 37. 97 63. 81 18. 21 229. 57 29. 14 258. 48 A + B + C 38. 24 70. 49 18. 54 218. 45 29. 31 291. 08 38. 23 79. 31 18. 48 248. 27 29. 29 288. 02 38. 19 57. 54 18. 30 202. 98 29. 06 262. 95 37. 66 -- 18. 35 -- 29. 09 -- (4)Rescores(1) 20
本來是這樣 � 訓練VAE示意圖: As close as possible “今晚想chill一下” NN Encoder Z NN Decoder “今晚想chill一下” Code (16 -dim vector) 21
我想試試看這樣做 � 訓練conditional VAE示意圖: (讓code蘊含有分類的意義) As close as possible “今晚想chill一下” NN Encoder Z NN Decoder “今晚想chill一下” Code (16 -dim vector) S F Classifier 22
� Try try see: WER (%) / PPL results of mixed LMs 3 -gram jarvis_assistant A + B (原來) 37. 97 63. 81 +AB. vocab 37. 58 18. 40 +AB. idf 3 K 39. 05 25. 12 +AB. idf 8 K 38. 25 31. 51 18. 21 229. 57 224. 88 mmwm 181 29. 14 258. 48 264. 36 23