Human genome organisation Human genome The human genome















 compact chromosomal DNA into the microscopic")
 •")















 transcription units Polycistronis transcription units are found in human mitochondrial genome and")

 • Structural component")
 • Involved in")
 • Involved")
 • Mostly")
 C/D box sno. RNA The C/D box Box C/D")
 C/D box sno. RNA Antisense nucleotides (upstream of the")
 C/D box sno. RNA During ribosome biosynthesis, the pre-r.")
 H/ACA box sno. RNA Box H/ACA sno. RNAs form")
 H/ACA box sno. RNA In pseudouridylations uridine is isomerized")
 sno. RNA genes often found within the introns of")
 • A new class of non-coding RNA gene • They")
 • The human genome has about 1000 distinct mi. RNAs")



















 and encode a transposase")


- Slides: 70
Human genome organisation
Human genome The human genome is the term to describe the total genetic information in human cell. Human genome = all the DNA present in the cell It really comprises two genoms: Ø a complex nuclear genome with about 30 000 genes; Ø a very simple mitochondrial genome with 37 genes.
• The nuclear genome provides the great bulk of essential genetic information, most of which specifies polypeptide synthesis on cytoplasmic ribosomes. • The mitochondrial genome specifies only a very small portion of the specific mitochondrial functions. • The bulk of the mitochondrial polypeptides are encoded by nuclear genes and are synthesized on cytoplasmic ribosomes, before being imported into the mitochondria.
Mitochondrial genome Mitochondria possess their own ribosomes, however the very few polypeptide-encoding genes in the mitochondrial genome produce m. RNA which are translated on the mitochondrial ribosomes.
General structure of mitochondrial genome The human mitochondrial genome is defined by a single type of circular double-stranded DNA. Ø The human mitochondrial genome complete nucleotide sequence has been established in 1981 and could be found on Mitomap mitochondrial genome database (www. mitomap. org). Ø It is 16 565 bp in length and has two strands- heavy (H) and light (L). Ø Although the mitochondrial DNA is double stranded, a small section shows triple- DNA strand structure due to the repetitive synthesis of a short segment of H strand DNA, 7 S DNA.
General structure of mitochondrial genome The mitochondrial DNA is rich in G+C nucleotides- 44%. The heavy strand is rich in guanines (G). The light strand is rich in cytosines (C).
Mitochondrial genome A single mitochondrion contains 2 to 10 mt. DNA copies. A single somatic cell (containing only two chromosome copies) has 100 - 10 000 mt. DNAs. The number of mt. DNA can vary considerably in different cell types. Lymphocytes have about 1000 mt. DNA. Certain cells, such as terminally differentiated skin cells lack any mitochondria and so have no mt. DNA. The gametes are unusual: Ø sperm cells have a few hundred copies of mt. DNA Ø oocytes have about 100 000 copies, accounting for over 30% of the oocyte DNA.
During zygote formation, a sperm cell contributes its nuclear genome, but not its mitochondrial genome, to the egg cell. Mitochondrial genome is maternally inherited: males and females both inherit their mitochondria from their mother. Males do not transmit their mitochondria to subsequent generations. During mitotic cell division, the mt. DNA molecules of the dividing cell segregate in a purely random way to the two daughter cells.
Mitochondrial genes The human mitochondrial genome contains 37 genes. A total of 24 genes specify a mature RNA product: Ø 22 mitochondrial t. RNA molecules Ø 2 mitochondrial r. RNA molecules: ü a component of the large subunit of the mt ribosomes- 23 S r. RNA; ü a component of the small subunit of the mt ribosomes- 16 S r. RNA. Ø the remainig 13 genes encode polypeptides which are synthesized on mitochondrial ribosomes: ü coding genes involved in mitochondrial respiratory complexes; ü the enzymes of oxidative phosphorylation which are engaged in the production of ATP.
Mitochondrial genes Coding and non-coding DNA The human mitochondrial genome is extremely compact and approximately 93% of the DNA sequence is coding. All 37 genes lack introns and they are tightly packed (on average 1 per 0. 45 kb). The coding sequences of some genes (subunits of ATPase) show some overlap. The coding sequences of neighboring genes are contiguous or separated by 1 or 2 noncodong bases.
Mitochondrial genes Coding and non-coding DNA The only region lacking any known coding DNA is the displacement (D) loop region. D loop is the region in which a triple- stranded DNA structure is generated by duplicate synthesis of a short piece of the H- strand DNA (7 S DNA). The D loop contains the predominant promoter for transcription of both H and L strands. Transcription of the mt. DNA starts from D loop promoters and continues, in opposing directions for the H and L strands, round the circle to generate large multigenic transcripts.
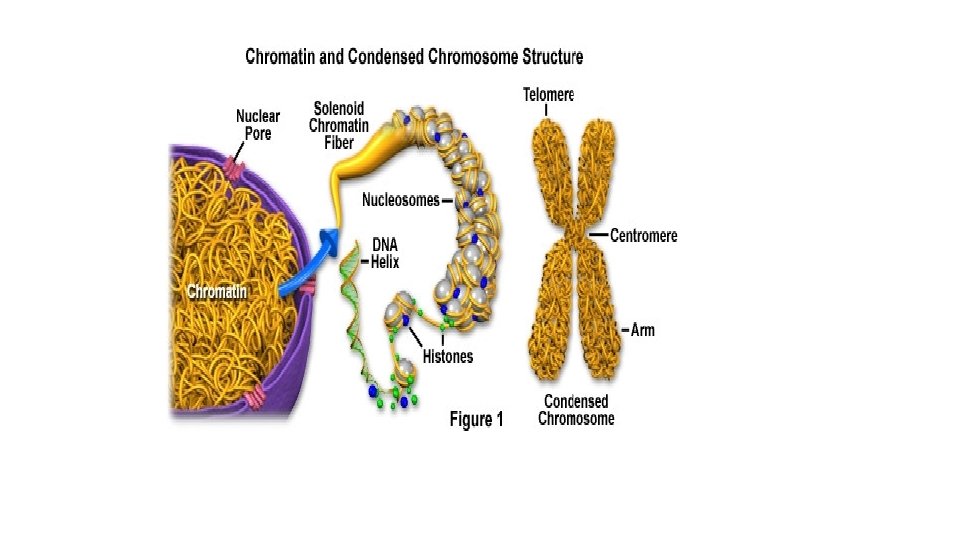
Nuclear genome The nucleus of a human cell tipically contains more than 99% of the cellular DNA is structured in long strands that are wrapped around protein complexes called nucleosomes that consist of proteins -histones. Such structured DNA constitute a chromosome. The human cell has 46 chromosomes: ü 22 pairs of autosomes ü 1 pair of sex chromosomes, X and Y
Number of chromosomes are not the same in different species.
q The haploid human genome contains approximately 3 billion base pairs of DNA packaged into 23 chromosomes. q Most cells in the body are diploid, that makes a total of 6 billion base pairs of DNA per cell. q Because each base pair is around 0. 34 nanometers long (a nanometer is onebillionth of a meter), each diploid cell therefore contains about 2 meters of DNA [(0. 34 × 10 -9) × (6 × 109)].
q It is estimated that human body contains about 50 trillion cells—which works out to 100 trillion meters of DNA per human. q The Sun is 150 billion meters from Earth. This means that each of us has enough DNA to go from here to the Sun and back more than 300 times, or around Earth's equator 2. 5 million times! How is this possible?
DNA packs into mitotic chromosome. Certain proteins (histones) compact chromosomal DNA into the microscopic space of the eukaryotic nucleus. Histones are positively charged proteins that strongly adhere to negatively-charged DNA and form complexes called nucleosomes. The resulting DNA-protein complex is called chromatin.
Human genome sequence was published in 2001. International Human Genome Sequence Consortium (IHGSC) • public funding, free access, started earlier Celera Genomics • private funding
Human gene number q The total number of genes in the human genome is now thought to be in the 25 000 - 35 000 range. q 1400 genes per chromosome on average. There are general difficulties to estimate the precise gene number. q When the draft genome sequences were published in 2001, about 11 000 genes could be identified with confidence. q Many thousands of genes were predicted by computer- based analysis of the sequence: ü Prediction of polypeptide-coding genes has been helpful, but is not always reliable- false positives and inaccuracy in genuine exons identification. ü Prediction of RNA genes is particularly poor.
1998 Human gene number A comparatively low number of human genes was a suprise. q Very simple , 1 mm long roundworm, Caenorhabditis elegans: ü consists of 959 somatic cells ü a genome only 1/30 of the human genome ü contain 19 099 polypeptide- encoding genes ü contain over 1000 RNA genes
Genome complexity might not always parallel biological complexity: ü Drosophila melanogaster has substantially fewer genes than the simpler C. elegans. Invertebrate genomes (insects, roundworm) 14 000 – 20 000 genes. Vertebrate genomes (human, mouse, putterfish) 30 000 – 35 000 genes. The unexpected low gene number in complex genoms has been rationalized on the bases of Ø increased transcriptional complexity; Ø increased frequency of alternative splicing.
Human gene distribution Gene density varies substantially between chromosomal regions
Gene size diversity q Genes in simple organisms such as bacteria are comparatively similar in size, and usually very short. q Human genes show enormous variation in size and internal organization. q There is a direct correlation between gene and product sizes, but there are some anomalies. Apolipoprotein B 4563 amino acids long encoded by 45 - kb gene Dystrophin 3685 amino acids long encoded by 2. 4 Mb gene
Genes vary in size and exon content
Genes vary in size and exon content A very small minority of human genes lack introns, and generally small in size. Intronless genes: Ø Ø Ø Interferon genes Histone genes Many ribonuclease genes Heat shock protein genes Many G-protein coupled receptors Various neurotransmitters receptors and hormone receptors
Genes vary in size and exon content ü The majority of the genes have an introns. ü There is an inverse correlation between gene size and fraction of coding DNA. ü There is huge variation in intron lengths. Large genes tend to have very large introns. ü Natural selection favors short introns in highly expressed genes, since transcription of long introns is costly in time and energy. ü The average exone size in human genes are less than 200 bp.
Base composition in the human genome 41% GC nucleotides in average The base composition vary considerably between chromosomes: Ø 38% GC for Ch. 4 and Chr. 13 Ø 49% GC for Chr. 19. It also varies considerably between the lengths of chromosomes: Ø The distal 10. 3 Mb part of Ch. 17 has 50% GC, but the adjacent 3. 9 Mb part has only 38% GC. Gene density correlates with higher GC content
Gene clusters q Genes encoding identical products or sequence related are often found in one or more clusters. These clusters may be dispersed on several chromosomes. q A very few human polypeptides are known to be encoded by two or more identical gene copies. Often, these are by recently duplicated genes in a gene cluster, such as alpha- globin genes.
Very occassionally some genes on different chromosomes encode identical polypeptides. Histone genes 86 different histone sequences distributed over 10 clusters in different chromosomes. Some subfamily members are identical althougt encoded by genes on different chromosomes.
Gene clusters Genes encoding identical products or sequence related are often found in one or more clusters. These clusters may be dispersed on several chromosomes.
Functionally related genes Some genes encode products which may not be so closely related in sequence, but are clearly functionally related. • Subunits of the same protein (α- globin and β- globin) or macromolecular structure. • Components of the same metabolic or signalling pathway (JAK 1 and STAT 1). • Ligand plus associated receptor (insulin and insuli receptor). • Immune system proteins Such genes are not clustered and are usually found on different chromosomes.
Genes within genes Several polypeptide- encoding genes are located within the introns of the larger genes. Neurofibromatosis type I gene (NF 1) Three small internal genes transcribed from the opposite strand: OGMP- oligodendrocyte myelin glycoprotein, EV 12 B and EVI 2 A – homologues of murine ecotropical viral integration sites.
Genes within genes Several polypeptide- encoding genes are located within the introns of the larger genes. The majority small nucleolar RNA (sno. RNA) genes are located within other genes, often ones which encode a ribosome-associated protein or a nucleolar protein. Possibly this arrangement has been maintained to permit co-ordinate production of protein and RNA components of the ribosome.
Polycistronic (multigenic) transcription units Polycistronis transcription units are found in human mitochondrial genome and the major r. RNA gene clusters. There are some rare examples of polypeptide encoding bicistronic transcription units in the nuclear genome. The A and B chains of insulin (related functionally). The UBA 52 and UBA 80 genes generate ubiquitin and a ribosomal protein (functionally distinct).
Organisation and distribution of human RNA genes Non- coding RNA The minority of nuclear genes specify noncoding (untranslated) RNA genes. There are probably about 3000 RNA genes, accounting for close to 10% of the total gene number. They have not been taken into account in gene count. The mitochondrial genome is exceptional in that 65% (24 from 37) of the genes specify mature RNA molecules.
Organisation and distribution of human RNA genes. Ribosomal RNA (r. RNA) • Structural component of ribosome • There approximately 700 - 800 human r. RNA genes. • Mostly organized in tandemly repeated clusters. • Many related pseudogenes.
Organisation and distribution of human RNA genes Transfer RNA (t. RNA) • Involved in translation process. • There are 497 nuclear genes encoding cytoplasmic t. RNA molecules. They can be grouped into 49 families according to their anticodon specificities. • t. RNA genes appear to be dispersed throughout the genome and clustered: Ø found on all chromosomes except Chr. 22 and Y). Ø more than half of them (280 t. RNA genes) reside on either Chr. 6, or on Chr. 1. • There also 324 t. RNA- derived putative pseudogenes.
Organisation and distribution of human RNA genes. Small nuclear RNA (sn. RNA) • Involved in assisting general gene expression. • Many sn. RNA are uridine-rich. Named as U 3 sn. RNA which means the third uridine-rich small nucleolar RNA to be classified. • They are encoded close to 100 genes • More than 70 of these genes specify sn. RNA used in the major spliceosome (removes the introns during splicing process). • 44 genes specify U 6 sn. RNA and 16 genes- U 1 sn. RNA. • There a large number of related nonfunctional sequences (pseudogenes).
Organisation and distribution of human RNA genes Small nucleolar RNA (sno. RNA) • Mostly employed in the nucleolus • to direct site- specific base modifications of r. RNA; • to carry out base modifications on sn. RNA. • Some sno. RNA are involved in the processing of pre-r. RNAS rather than nucleotide modification. • They are 2 subfamilies of sno. RNA: ü C/D box sno. RNA ü H/ACA sno. RNA • nucleolus- the site of ribosome synthesis and assembly
Small nucleolar RNA (sno. RNA) C/D box sno. RNA The C/D box Box C/D sno. RNAs direct the 2'-O-methylation of r. RNA nucleotides. Contain two short sequence motifs. C/D box sno. RNAs show conserved boxes termed C (UGAUGA) and D (CUGA), positioned near their 5' and 3' termini. Sometimes two additional, less conserved, boxes called C' and D' are present. Antisense nucleotides (upstream of the box D or D’) are complementary to a specific site of r. RNA.
Small nucleolar RNA (sno. RNA) C/D box sno. RNA Antisense nucleotides (upstream of the box D or D’, 10 -21 nt) are complementary to a specific site of r. RNA. The methyl group is added onto nucleotide at the fifth position upstream from this box. While the sno. RNA component directs the sno. RNP complex to the appropriate r. RNA location, it is a protein enzyme- methyltransferase that actually catalyzes the methylation reaction.
Small nucleolar RNA (sno. RNA) C/D box sno. RNA During ribosome biosynthesis, the pre-r. RNAs must undergo several modifications mainly 2'-O-ribose methylation and pseudouridylation The 2'-O methylation of nucleotides may • protect the RNA from hydrolytic degradation, • enhance hydrophobic surfaces for interaction, • stabilize helical stems. The methyl group is added onto nucleotide at the fifth position upstream from this box.
Small nucleolar RNA (sno. RNA) H/ACA box sno. RNA Box H/ACA sno. RNAs form a secondary structure made up to two large hairpin domains connected by a hinge region, followed by a short tail. • The conserved box motifs include: ü the H (5'ANANNA 3' where N is any nucleotide); ü the ACA trinucleotide always found three nucleotides away from the 3' end of the sno. RNA. Generally there is 14 -16 nucleotide distance between the box motifs and the site to be modified by the pseudouridine synthase- dyskerin.
Small nucleolar RNA (sno. RNA) H/ACA box sno. RNA In pseudouridylations uridine is isomerized to give pseudouridine, the most common modified base. Dyskerin is the pseudouridine synthase which catalyzes the conversion of uridine to pseudouridine. Pseudouridines have increased flexibility in their C-C glycosyl bonds and therefore may allow for increased capacity for hydrogen bond formation, contributing to RNA tertiary structure.
Small nucleolar RNA (sno. RNA) sno. RNA genes often found within the introns of other genes. Most of the sno. RNA genes appear to be single copy and dispersed. Some large clusters are known (in SNURF-SNRPN transcription unit).
Micro. RNAs (mi. RNA) • A new class of non-coding RNA gene • They are 19 -25 bases long RNAs • They derived from larger up to 70 - nucleotide long precursors containing an inverted repeat which permits ds hairpin RNA formation. • Hairpin precursor RNAs are cleaved by a ribonuclease III- Dicer.
Micro. RNAs (mi. RNA) • The human genome has about 1000 distinct mi. RNAs that regulate at least 1/3 of the protein- encoding genes. • They act as antisense regulators by binding to complementary sequences in the 3’ UTR of m. RNA. • Block translation or result in degradation of target m. RNA
Pseudogenes Genes are frequently characterized by defective copies- pseudogenes. Non-functional copy of a gene q Nonprocessed pseudogene Ø Nonfunctional copies of the genomic DNA sequence of a gene. Ø Contains exons, introns and promoter regions of the functional genes, but recognized to be defective by the presence of innapropriate termination codons (such as in α-globin and β-globin clusters).
Pseudogenes Genes are frequently characterized by defective copies- pseudogenes. q Processed pseudogene Ø Nonfunctional copies of the exonic sequences of a gene. Ø Contain at one end poly(A) tail Ø No introns Ø No 5’ promoter regions Ø Reverse transcriptases transcribe m. RNA into c. DNA which can then integrate into chromosomal DNA.
Pseudogenes Genes are frequently characterized by defective copies- pseudogenes. q Processed pseudogene are typically not expressed, but some examples are known of expressed processed genes. Ø The c. DNA has integrated into a chromosomal DNA site, which happens, by chance, to be adjascent to a promoter which can drive expression of the processed gene copy. Both types of pseudogenes include events (frameshifts, stop codons) that make the gene nonfunctional. The 20 -30% of all genomic sequence predictions could be pseudogene. We assume pseudogenes have no function, but we really don’t know!
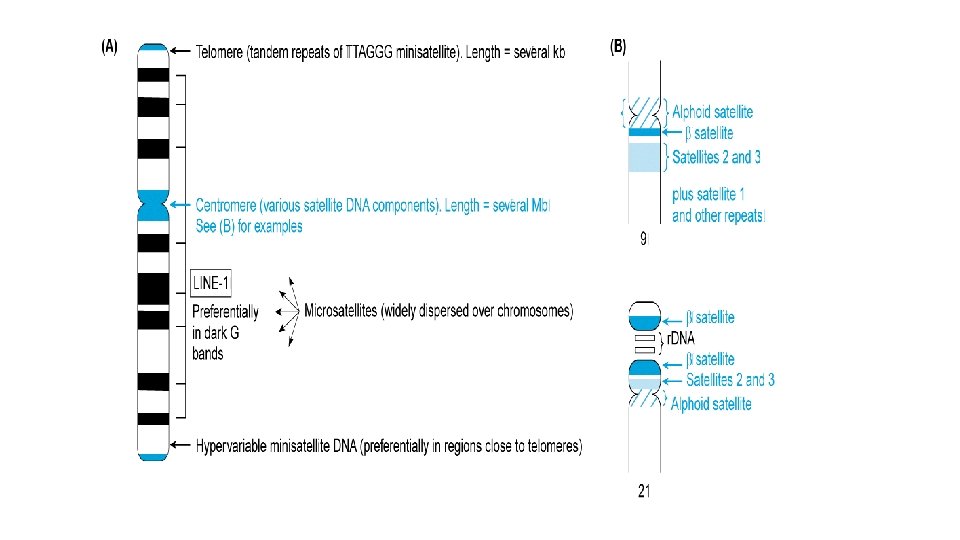
Tandemly repeated noncoding DNA q Highly repeated non-coding DNA often occurs in arrays of tandem repeats of a sequence which may be a simple one (1 -10 nucleotides), or more complex (tens to hundreds of nucleotides). q Three major subclasses can be defined according to the array size: Ø satellite DNA Ø minisatellite DNA Ø microsatellite DNA q Individual arrays can occur at a few or many different chromosomal locations.
Satellite DNA Alpha satellite Minisatellite Microsatellite
Alpha satellite consists of tandem repeats of a 171 -bp repeat unit and makes up the bulk of centromeric heterochromatin. α- satellite is present on all chromosomes, and its repeat units often contain a binding site for centromere protein, CENP-B. α- satellite plays an important role in centromere function.
Minisatellite DNA Minisatelites can be found in tandem arrays, but the majority are interspersed in the genome. Occur at more than 1000 locations in the human genome. Minisatellites also called a Variable Number Tandem Repeats (VNTRs). They usually contain repeats of 9 - 100 bp. Ø Hypervariable minisatellite DNA family repeat units vary in size, but share a common core sequence, GGGCAGGAXG (X= any nucleotide). Found mostly near the telomeres. ü It has been reported to be a ”hotspot” for homologous recombination in human cells. Ø Telomeric minisatellite DNA family repeat units found at the very ends of chromosomes. Telomeric DNA is 3 -20 kb of tandem 6 nucleotide (TTAGGG) repeat units. ü Provide a mechanism for replicating the ends of the linear DNA of chromosomes.
Microsatellite DNA q Microsatelites are found mostly in tandem repeats. q Microsatellites, also termed Short Tandem Repeats (STRs). They consist of tracts of repeats of 1 -7 bp. q They are interspersed throughout of genome, accounting for over 60 Mb (2% of the genome). q Arrays of dinucleotide repeats are the most common type (0. 5% of the genome): Ø CA/TG are very common – 1 per 36 kb; Ø AT/TA- 1 per 50 kb; TGCTCAGTCAGGC Ø AG/TC- 1 per 125 kb; TGCTCAG----GC Ø CG/GC repeats are very rare – 1 per 10 Mb. q Mostly found within the introns of genes, rare in exons, where they are mutational hotspots.
Minisatellite and microsatellite as DNA markers Analysis of STRs and VNTRs sequences is used in many genetic approaches. Some of repeats are hypervariable, meaning that the number of copies of the repeat varies greatly among people. Therefore lots of alleles are generally present in population. Two individuals have a higher chance of genetic differences at STRs and VNTRs than at non repeating sequences (due to replication errors).
Minisatellite and microsatellite as DNA markers Minisatelites has been used in DNA fingerprinting, in which a single DNA probe containig the core sequence hybridize simultaneously to multple minisatellite DNA loci on all chromosomes, getting a unique DNA hybridization profile. DNA fingerprinting analysis is often used in paternity and forensic identity.
Paternity identity VNTR patterns are extremely specific and can be accurately compared. A child will share one band with the biological mother and one with the biological father. A persons VNTRs will never have sequences that their parents do not have.
Forensic identity
Interspersed repetitive noncoding DNA Almost all of the interspersed repetitive noncoding DNA is derived from transposable elements – transposons. Transposons are mobile DNA sequences which can migrate to different regions of the genome. Close to 45% of the genome can be transposons. Transposons can be organized into 2 groups according to the method of transposition: Ø retrotransposones and Ø DNA transposons
Transposons q Move DNA within and between chromosomes q Reorganize and create chromosome rearrangements
Interspersed repetitive noncoding DNA Retrotransposones The copying mechanism uses reverse transcriptase to make c. DNA copies of RNA transcripts. After which the copy migrates and inserts elsewhere in the genome. Include 3 mammalian transposon classes: Ø LINEs- long interspersed nuclear elements; Ø SINEs- short interspersed nuclear elements; Ø retrovirus-like elements containig long terminal repeats.
LINEs- long interspersed nuclear elements LINE 1 element • ~0. 8 kb, ~20% of human DNA (~100. 000 copies) • 3 distantly related families: LINE 1 -3 • prefer AT-rich euchromatic bands Encodes 2 proteins: • an RNA-binding protein; • protein with both endonuclease and reverse transcriptase activities. Of the 6000 full- length LINE 1 sequences, about 60 - 100 are still capable of transposing, and may occasionally cause disease by disrupting gene function following insertion into an important conserved sequence. The LINE 1 is responsible for most of the reverse transcription in the genome, allowing retrotransposition of SINEs and creation of processed pseudogenes.
SINEs- short interspersed nuclear elements q SINEs retrotransposones are the second most abundant class of transposable elements in the human genome. q Contains several families: • Alu, ~0. 3 kb, ~10, 7% of human DNA (1, 200, 000 copies) • MIR (mammalian-wide interspersed repeat), ~0. 13 kb, 3% of human DNA (500, 000 copies). q SINEs are about 100 -400 bp long and do not encode proteins and are not autonomous.
SINEs- short interspersed nuclear elements q SINEs and LINEs share sequences at their 3’ end and SINEs have been shown to be mobilized by neighboring LANE. q The reverse transcriptase required for SINE transposition is provided by a LINEs elements. q SINEs repeats are not just genomic parasites , but are making a useful contribution to cells. q SINEs are transcribed under conditions of stress, and the resulting RNAs bind a specific protein kinase (PKR) and block its ability to inhibit protein translocation. q SINE RNAs can promote protein translation under stress.
Retrovirus-like elements containig long terminal repeats • LTR transposons include autonomous and nonautonomous retrovirus-like elements which are flanked by long terminal repeats (LTR) containing transcriptional regulatory elements. • The autonomous members are known as endogenous retroviral sequences (ERVs). • They contain gag and pol genes, which encode a protease, reverse transcriptase, RNAse H and integrase. • The nonautonomous retroviral elements lack the pol gene and often gag gene. They are used by viruses to insert their genetic material into the host genomes.
DNA transposons q DNA transposons have terminal inverted repeats (ITR) and encode a transposase which regulates transposition. q They account for close to 3% of the human genome. q All the resident human DNA transposon sequences are no longer active and so are transposon fossils.
Chromosomal location of repeats
Human Genome Organization HUMAN GENOME Nuclear genome 3, 200 Mb 25, 000 genes Genes and generelated sequences Mitochondrial genome 16. 5 kb 37 genes Extragenic DNA Two r. RNA genes 22 t. RNA genes 13 polypeptideencoding genes Unique or moderately repetitive Coding DNA Pseudogenes Unique or low copy number Noncoding DNA Gene fragments Introns, untranslated sequences, etc. Tandemly repeated Moderate to highly repetitive Interspersed repeats