How to Play Go using a computer A
 A Low-Effort Journal Club Talk All ideas/insights/diagrams")
 Setup: 1 Board Generally 19")





 •")
 The original Alpha. Go! Basic algorithm: 1) Supervised Learning:")
























- Slides: 35
How to Play Go (using a computer) A Low-Effort Journal Club Talk All ideas/insights/diagrams plundered from: https: //www. nature. com/nature/journal/v 550/n 7676/pdf/nature 24270. pdf http: //cs 231 n. github. io/convolutional-networks/ https: //ujjwalkarn. me/2016/08/11/intuitive-explanation-convnets/ http: //mcts. ai/about/index. html Wikipedia https: //www. nature. com/nature/journal/v 529/n 7587/pdf/nature 16961. pdf
How to play go (with a computer or otherwise) Setup: 1 Board Generally 19 x 19 lines (sometimes smaller), 2 players (white and black), ‘unlimited’ stones for each player Play: 1. Start with empty board. Players alternate placing stones on empty intersections of the board, starting with black. 2. The game ends when both players ‘pass’ consecutively. Scoring: One point is awarded for every stone on the board and every empty intersection completely surrounded by a player’s stones or the boundary Tromp
More rules More: 1. No board position can be repeated. 2. A solid group of stones completely surrounded by an opponents stones is removed from the board.
Rudimentary strategy Connection and Separation: Harder to capture your connected groups. Life and Death: Territory you hold may be alive or dead if it can be captured in the future. Need ‘two eyes’. Low and high: Low to the edge is more secure, high to middle captures more territory Joseki: Studied sequences of corner moves balancing need to secure territory in corner vs expanding to center of board
Ranking go players •
Why learn to play go? “Grand challenge for AI” • Deep Blue won at chess by hand-coding in values of pieces (and board positions) to optimize exploration of state tree • Depended on detailed human knowledge of chess strategy • Value is often localized and easy to measure (eg. Queen more valuable than pawn) • A ‘good’ Go board position depends a lot on intuition • Valuable board positions depend on information that is non-local (and topological) • There are many, many more possible board positions in Go than Chess (O(100)/turn as opposed to O(10) for chess) • Go games tends to last longer than Chess (also O(100) vs O(10) turns)
Why reinforcement learning? Supervised learning can be efficient way to learn and replicate the decisions of human experts. But: • Data sets can be expensive, unreliable, unavailable. • Human experience may put ceiling on performance (learns only to be better than training data, not as good as possible) Reinforcement learning: • Learn from own experiences; may be able to explore more, or different parts of, state space than humans already have
Markov decision process (MDP) •
Alpha. Go Fan (and Lee) The original Alpha. Go! Basic algorithm: 1) Supervised Learning: Trained a convolutional neural net to learn policy using a large dataset of human expert Go games. 2) Reinforcement Learning: Next the policy is improved by self-play against pool of different versions of the policy. 3) More Reinforcement Learning: A completey separate CNN was trained to learn the value fuction 4) Monte Carlo Tree Search: Rather than play with either policy alone (or both), Alpha. Go used a Monte Carlo search and fast rollout policy to simulate games at every turn and improve the naïve policy/value function.
Performance • Policy Network: Breadth reduction. Alpha. Go evaluated thousands of times fewer positions than Deep Blue, despite larger search space. • Value Network: Evaluated more precisely as well.
Performance
Alpha. Go Zero How does Alpha. Go Zero differ from Alpha. Go Fan/Lee in broad strokes? 1. 2. 3. 4. Trained only by self-play reinforcement learning Used only position of stones as input features--no feature engineering Single neural network (instead of policy and value networks) Simpler tree search without Monte Carlo rollouts
Alpha. Go architecture •
Convolutional NN •
Convolutional NN • Filter looks at each L x L block to extract relevant features (at that scale): • If you have repeated filter layers or CNN blocks, you can extract features/wavelets at longer and longer length scales (whether or not you pool/coarse-grain) • After convolving, pooling (and Re. Lu), there is usually then a fully connected layer that takes all of these coarse-grained features and ‘does the relevant computation’ (Physicist’s Question: Is there a better way to learn features from a Go board? Is this wavelet-like basis optimal? )
Residual Blocks •
Batch normalization •
Rectifier nonlinearities •
Neural net architecture •
Other ingredients •
MCTS •
MCTS •
MCTS •
MCTS •
How to train this neural net? •
Training •
How well does Alpha. Go Zero play? • Beats Alpha. Go Lee after 36 hours (Alpha. Go Lee took months to reach this level) and used only a single machine vs. many for Lee—at end of training wins 100 -0 • Train same neural network architecture by supervised learning on expert games: worse at playing better at predicting expert moves Alpha. Go Zero uses better superhuman strat
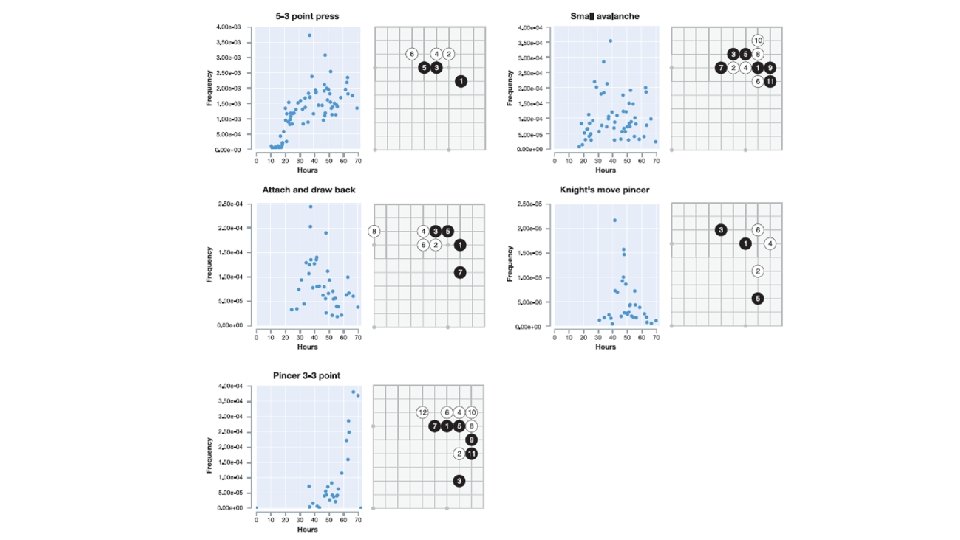
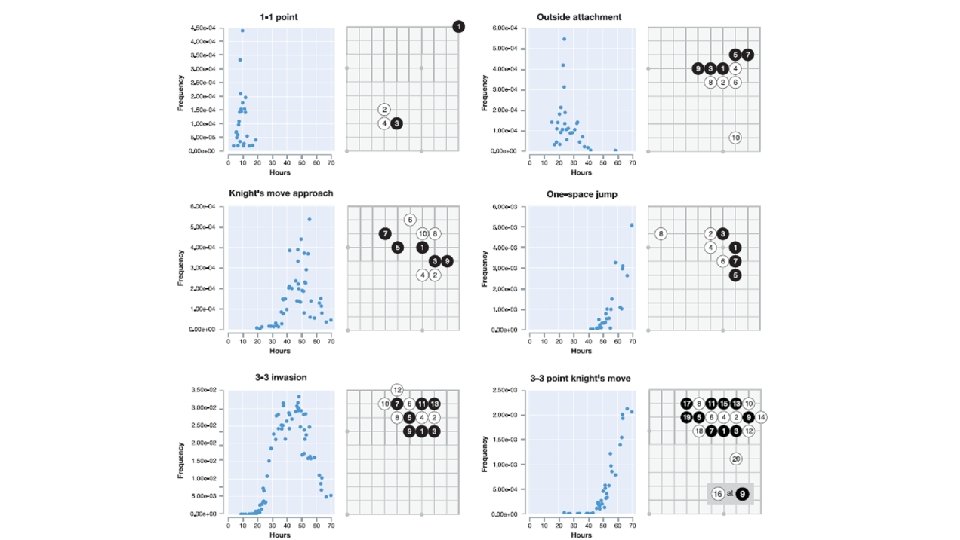
Go knowledge learned • Alpha. Go Zero learned both fundamentals of Go, but also non-standard (and better!) strategies beyond scope of traditional Go knowledge
Go knowledge learned • Alpha. Go Zero learned both fundamentals of Go, but also non-standard (and better!) strategies beyond scope of traditional Go knowledge
Go knowledge learned
Final Performance • Alpha. Go Master: take the same NN architecture and algorithms, but train on human data. • Defeated best human player 60 -0 in Jan 2017 • Alpha. Go Zero reached Elo 5, 185 and beats Alpha. Go Master 89 -11