Hoofdstuk 2 Kijken naar gegevens relaties Hoofdstuk 1











 x – x sx y–y sy")











 en andere onder (negatief) dus kwadrateren zodat allen positief")

2 = (yi - a - bxi )2 in voorbeeld : (76.")
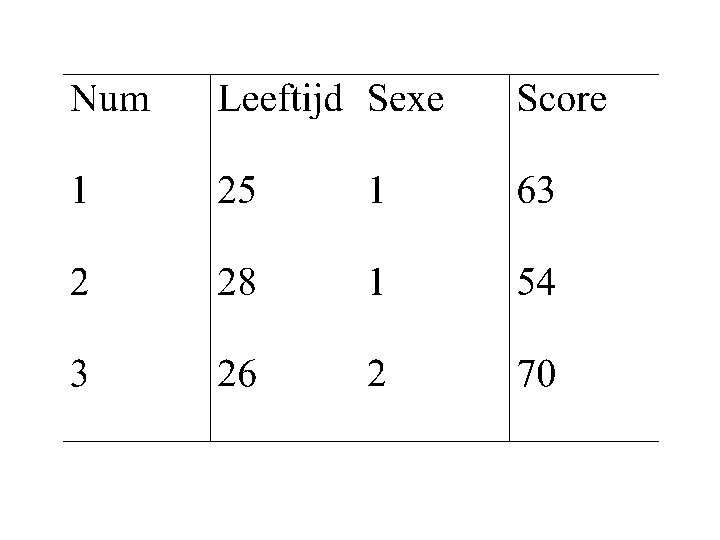
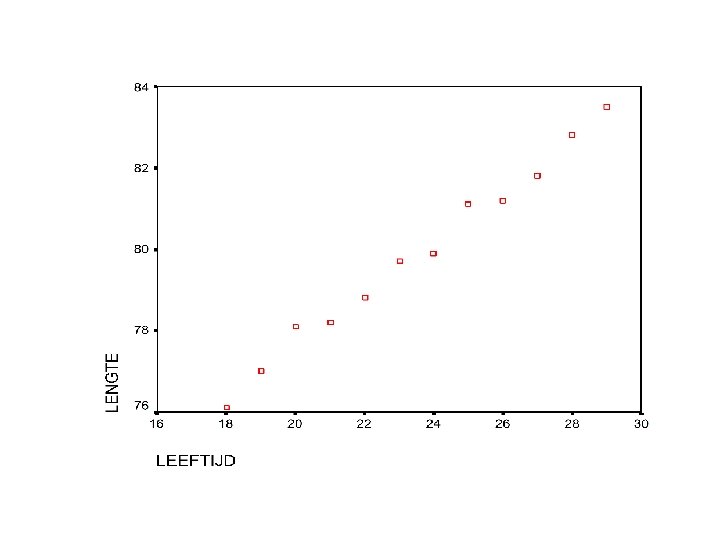
 LEEFTIJD")






















")






- Slides: 66
Hoofdstuk 2 Kijken naar gegevens : relaties
• Hoofdstuk 1 : 1 variabele • Hoofdstuk 2 : relaties tussen verschillende variabelen • In gegevensverzameling : meerdere variabelen per geval • Geval : individuele persoon individueel dier individueel ding waarvoor variabelen
• Kwantitatieve of kwalitatieve variabelen – kwantitatief : numeriek (gemid. en stand. afw. ) – kwalitatief : klasse, categorie • Bij meerdere variabelen vaak kwantitatief en kwalitatief samen aanwezig • Relatie tussen twee variabelen – gewoon relatie – ene heeft invloed op de andere
• Invloed van ene variabele = de verklarende variabele OF de onafhankelijke variabele op de andere variabele = de te verklaren variabele OF de afhankelijke variabele
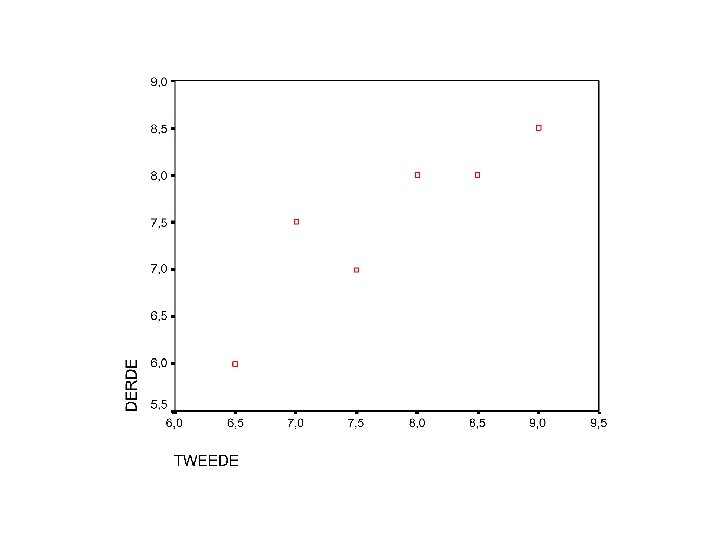
2. 1. Spreidingsdiagrammen • Doel : relatie tussen 2 kwantitatieve variabelen bij zelfde individu grafisch weergeven • Voorbeeld : punten van Tom taal rekenen WO LO Tekenen Muziek 2 de jaar 7 9 8 8. 5 6. 5 7. 5 3 de jaar 7. 5 8 8 6 7
A. Spreidingsdiagrammen interpreteren • Zoeken naar een globaal patroon • Meest voorkomende : LINEAIRE relatie : = de vorm van een rechte lijn • RICHTING : Positieve samenhang : – boven gemidd voor A, ook boven gemidd voor B – onder gemidd voor A, ook onder gemidd voor B – OF : HOE MEER
• RICHTING : Negatieve samenhang : – boven gemidd voor A, onder gemidd voor B en omgekeerd – OF : HOE MEER HOE MINDER • VORM : Lineair of niet lineair – Relatie niet altijd lineair • STERKTE van verband : hoe meer op een rechte lijn hoe sterker
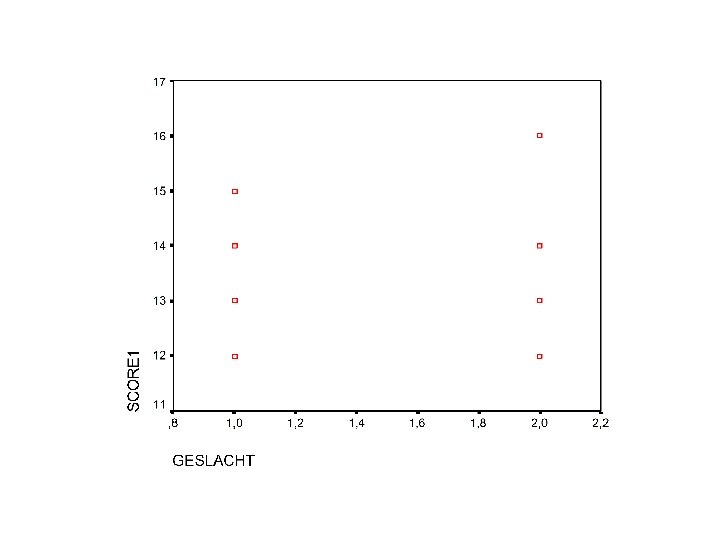
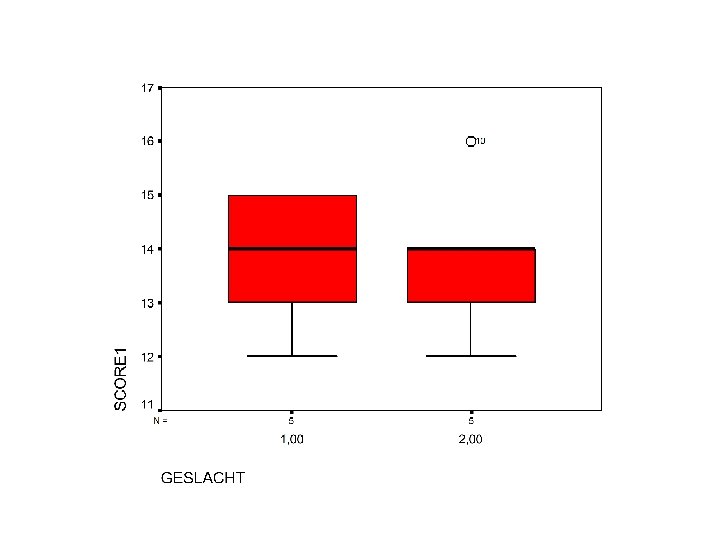
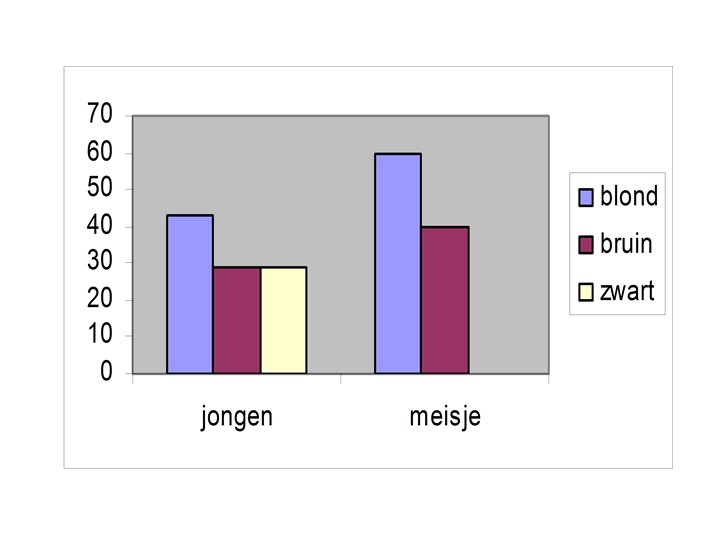
B. Kwalitatieve verklarende variabelen • Kwalitatieve variabelen kunnen – ook grafisch in spreidingsdiagrammen • > de kwalitatieve variabele op de x-as – of met zij-aan-zij doosdiagramman • Voorbeeld : geslacht en score op een test
• Soms wel een ordening : opleiding & inkomen
2. 2. Correlatie • Sterke lineaire relatie als de punten dicht bij een rechte lijn liggen • Zwakke relatie als de punten verspreidt liggen • Maar dit niet enkel op het zicht interpreteren : een numerieke maat nodig die de sterkte aanduidt
A. De correlatie r • Correlatiecoëfficiënt : meet de richting en sterkte van de lineaire relatie tussen twee kwantitatieve variabelen • Correlatie : enkel betrekking op LINEAIRE relatie tussen KWANTITATIEVE variabelen
• Correlatiecoëfficiënt r r = 1/ (n-1) x – x sx y–y sy • Samenhang tussen x en y : als zowel x als y onder gemiddelde of beide boven gemiddelde zal r hierboven groter worden
• Als x en y tegengestelde tekens hebben, zal de correlatie negatief zijn • In de formule wordt gebruik gemaakt van gestandaardiseerde afwijkingen (x - gem x)/sx. DUS wijziging in meeteenheid heeft geen invloed op r. • Formule van r niet kennen wel computeroutput
B. Eigenschappen van correlatie 1. Geen x en y bij correlatie, geen afhankelijke en onafhankelijke variabele 2. Moeten twee kwantitatieve variabelen zijn 3. r verandert niet als de meeteenheid van x, y of beide verandert 4. Een positieve r wijst op een positieve samenhang, een negatieve r op een negatieve samenhang 5. r ligt tussen -1 en +1, positieve en negatieve samenhang
1. Naarmate r dichter naar -1 of +1 gaat liggen de punten dichter bij de rechte lijn, en is het verband sterker 2. Waarden van r die dichtbij 0 liggen geven een heel zwak lineair verband 3. r=1 of r=-1 betekenen dat de punten precies op de rechte lijn liggen, dan is er een perfect verband 4. Correlatie meet slechts de sterkte van een lineaire relatie, sterke kromlijnige relaties worden niet in correlatie weerspiegeld 5. R is niet resistent, wordt sterk beïnvloed door uitschieters
2. 3. Kleinste-kwadratenregressie • Hoe kunnen we spreidingsdiagram op een korte manier weergeven • Meest eenvoudige relatie : afhankelijke variabele y hangt lineair (rechtlijnig) af van een onafhankelijke variabele x • REGRESSIELIJN = rechte lijn die afhankelijkheid van een variabele van een andere beschrijft
• Bij correlatie : 2 kwantitatieve variabelen zonder x en y • Bij regressie : duidelijke x = onafhankelijke variabele y = afhankelijke variabele • Regressielijn : voorspellen van y op basis van x
A. Aanpassen van een lijn aan de data • Bij een lineair patroon in het spreidingsdiagram gaat een rechte lijn niet PRECIES door alle punten • DUS : aanpassen van een lijn = lijn tekenen die zo dicht mogelijk bij de punten komt • De VERGELIJKING van zo een lijn geeft een beknopte beschrijving van de afhankelijkheid van y van variabele x
• Voorbeeld : gemiddelde lengte naar leeftijd in maanden 18 19 20 21 22 23 24 25 26 27 28 29 lengte in cm 76. 1 77. 0 78. 1 78. 2 78. 8 79. 7 79. 9 81. 1 81. 2 81. 8 82. 8 83. 5
• Beschrijving van een rechte lijn y=a+bx y = te verklaren variabele of afhankelijke op verticale as x = de verklarende of onafhankelijke op horizontale as b = de helling, hoeveelheid waarmee y toeneemt als x één eenheid toeneemt a = constante (waarde van y bij x=0)
• Terug naar het voorbeeld : lengte = 64. 93 + (0. 635. leeftijd) – helling b = 0. 635 dus elke maand ongeveer 0. 6 cm lengte toenemen – dus b = mate van verandering in y als x verandert – constante a = 64. 93 zou lengte zijn bij leeftijd 0 (geboorte) indien ze zouden groeien met vaste verhouding, wat niet zo is, dus niet belangrijk
B. Voorspelling • Op basis van regressielijn kan de afhankelijke variabele y VOORSPELD worden op basis van x bv. wat zou de lengte zijn bij leeftijd 32 ? Lengte = 64. 93 + (0. 635 X 32) = 85. 25 cm of grafisch op basis van figuur (extrapolatie) • Als de gegevens zeer dicht bij de lijn liggen is de voorspelling betrouwbaar, bij grote spreiding rondom de lijn minder
C. Kleinste-kwadratenregressie • Hoe vinden we nu deze lijn door de data ? – methode van de kleinste kwadraten • HOE ? – Eerst y voorspellen uit x – y op y-as – verticale afstanden van punten tot de lijn zijn fouten in de voorspelling van y – doel is zo weinig mogelijk fouten dus afwijkingen zo klein mogelijk maken
– Sommige punten boven (positief) en andere onder (negatief) dus kwadrateren zodat allen positief zijn – som van de kwadraten is de omvang van alle afwijkingen – DUS die lijn zoeken waarvoor de som van de kwadraten het kleinst is = de kleinste kwadraten regressielijn
• Afwijking = waargenomen y - voorspelde y = yi - yi = yi - a - bxi (afwijkingen)2 = (yi - a - bxi )2 = som van kwadraten van de afwijking zo klein mogelijk = hiervoor moeten a en b gevonden worden
• (afwijkingen)2 = (yi - a - bxi )2 in voorbeeld : (76. 1 - a - 18 b)2 + (77. 0 - a - 19 b) 2 + … • formule niet kennen • wel op basis van computeroutput
D. Interpreteren van de regressielijn • Regression : Coefficients t Model 1 (Constant) LEEFTIJD a B 64, 928 , 635 Std. Error , 508 , 021 Dependent Variable: LENGTE Sig. Beta , 994 127, 709 , 000 29, 665 , 000
E. Correlatie en regressie • Bij regressielijn afhankelijke variabele voorspellen uit onafhankelijke – y op x • Maar kan ook omgekeerd regressie van – x op y Beide regressielijnen zijn sterk verschillend – verticale minimaliseren – horizontale minimaliseren
1 e verband tussen correlatie en regressie • Het kwadraat van de correlatiecoëfficiënt, r 2 is de variatie in y waarden die verklaard worden door de kleinste-kwadratenregressie van y op x – bv. r = -0. 64 dus r 2 = 0. 41 of 41% van de variatie van een van de variabelen wordt verklaard door de lineaire regressie op de andere variabele
• r 2 wordt veel gebruikt omdat het een directe maat is voor het succes van een regressie 2 e verband tussen correlatie en regressie • Helling van de regressielijn sy b=r sx of een verandering van 1 st. afw. in x komt overeen met een verandering van r st. afw. in y
• Als we weten dat de kleinste kwadraten regressielijn loopt door het punt ( x, y) van de grafiek en de helling is r sy / sx DAN kan de regressie volledig beschreven worden uit gem x, gem y, sx, sy, en r
2. 4. Waarschuwingen over regressie en correlatie • Regressie en correlatie worden heel veel gebruikt • Ook zonder nadenken • Steeds zicht blijven houden op mogelijkheden en beperkingen
A. Residuen • Residu = het verschil tussen een waargenomen waarde en de door het model voorspelde waarde = AFWIJKING residu = waargenomen y - voorspelde y =y-y • Bij kijken naar gegevens eerst globaal patroon en dan de afwijking WAARNEMING = AANPASSING + RESIDU
• Voorbeeld : - bij 24 maand was de lengte 79. 9 cm - regressielijn : y = 64. 93 + (0. 635 X 24) = 80. 17 - het residu bedraagt 79. 9 - 80. 17 = -0. 27 • residuen zijn de verticale afstanden tot de regressielijn • het zijn de afwijkingen die overblijven nadat de lijn is getrokken waarvan de som van de kwadraten van afwijkingen zo klein mogelijk is
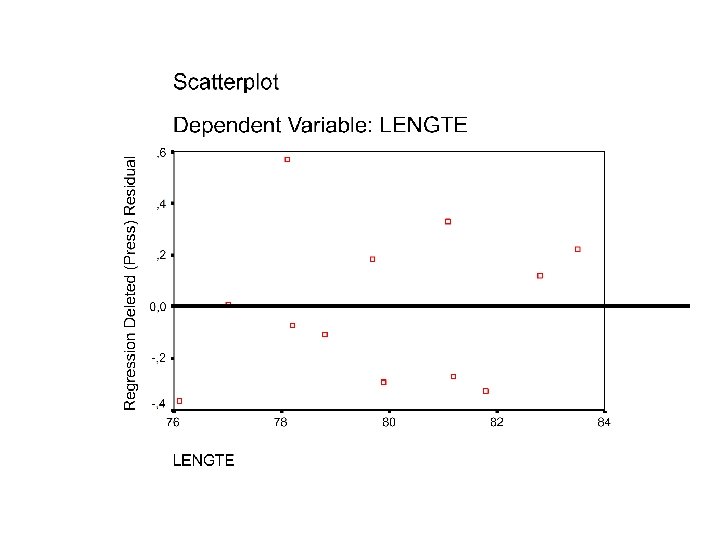
• Door residuen te bekijken zien we hoe goed de lijn de gegevens beschrijft • Het gemiddelde van de residuen is steeds gelijk aan 0 indien de kleinste-kwadratenlijn werd berekend • Bekijken op basis van een residuendiagram
• Het residuendiagram moet een ongestructureerde band zijn om 0 • Indien er een patroon zit in de residuen – bv. curvilinear – bv. systematish groter wordende residuen => dan moet er verder gekeken worden of er niets over het hoofd is gezien • Op basis van residuen zou een verborgen variabele kunnen worden ontdekt
B. Verborgen variabelen • Een verborgen variabele heeft een belangrijke invloed op de relaties maar is niet opgenomen bij de bestudeerde variabelen • Door een specifiek patroon in residuen diagram kan bv. opgespoord worden
C. Uitschieters en invloedrijke waarnemingen • Naast globaal patroon zijn afzonderlijke punten die buiten dat patroon vallen soms nog belangrijker • Voorbeeld : leeftijd waarop een kind begint te spreken en latere score op test regressielijn : later spreken, lagere score
• Uitschieters in regressie : in verticale richting ver van de regressielijn dus groot residu – kunnen we ontdekken op basis van residuendiagram • Invloedrijke waarnemingen in regressie : als verwijdering ervan een opvallende wijziging in de regressielijn teweegbrengt, vaak extreme x-waarden – kan niet op basis van residuen gevonden worden, wel spreidingsdiagram
• Bij invloedrijke waarnemen : – nagaan of ze correct zijn – behoort ze wel tot de populatie DOEN : eens regressielijn met en zonder invloedrijke waarnemingen bekijken
D. Wees alert • Alleen maar voor lineaire samenhang • noch r, noch kleinste-kwadratenregressie is resistent : dus : - kijken naar invloedrijke waarneming - opletten voor intikfouten • Steeds opletten voor verborgen variabelen bv. positieve correlatie tussen lerarensalarissen en verkoop van sterke drank
• = nonsens correlaties = een sterke correlatie impliceert geen oorzaak-gevolg relatie • soms lage correlatie maar toch verband bv. twee clusters DUS : niet alleen naar correlatie kijken ook steeds naar de figuur • Pas y voorspellen uit x bij voldoende sterke r 2 , dus eerst correlatie kwadrateren en pas dan regressie
• Ook opletten met extrapolatie : dikwijls geldt de regressielijn enkel voor een beperkt gebied van x • Opletten met correlaties tussen gemiddelden -> door gemiddelden wordt reeds heel wat variatie gladgestreken -> deze correlaties zijn gewoonlijk overschattingen
• Bij beschrijving van 2 variabelen – niet alleen op correlatie en regressie baseren – ook telkens gemiddelde en standaardafwijking in rekening brengen – figuur maken is altijd zinvol
2. 6. Relatie tussen kwalitatieve variabelen • Tot nu toe enkel kwantitatieve • Kwalitatieve zijn ook belangrijk – geslacht, ras, beroep = in se kwalitatief – kwantitatief in klassen • Analyses gebaseerd op aantallen of percentages gevallen in elke klasse • Twee kwalitatieve variabelen : voorgesteld in een kruistabel
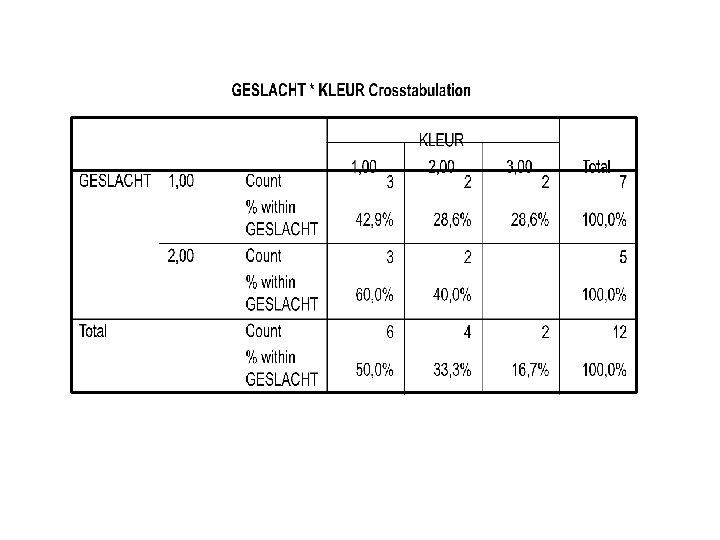
GESLACHT * KLEUR Crosstabulation Count GESLACHT 1, 00 2, 00 Total KLEUR 1, 00 2, 00 3, 00 Total 3 3 2 2 2 7 5 6 4 2 12
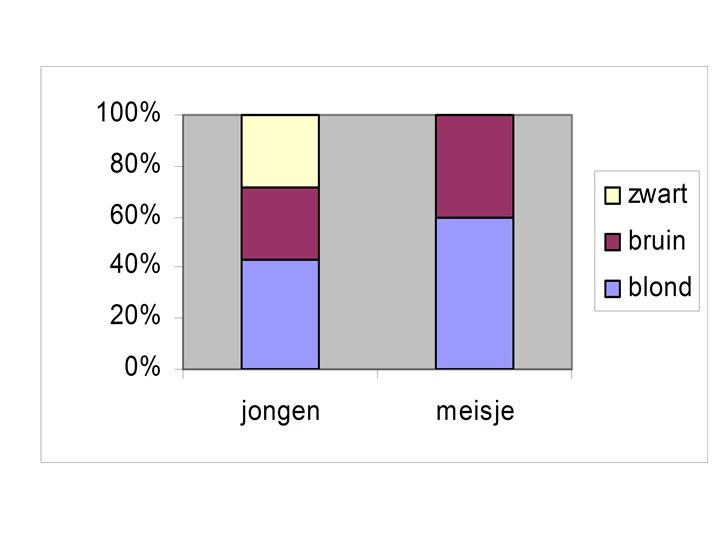
A. Marginale verdelingen • Marginale verdelingen = totalen van beide variabelen uit onderrand en rechterkolom • Relaties tussen kwalitatieve variabelen door uit de aantallen de percentages te berekenen • Grafisch voorstellen in staafdiagram : hoogte van de staaf is percentage • Gesegmenteerd staafdiagram : 100% in 1 staaf voorgesteld : vergelijking
B. Beschrijven van relaties • Bij kruistabellen altijd percentages in twee richtingen mogelijk rij-percentages en kolompercentages GESLACHT * KLEUR Crosstabulation KLEUR 1, 00 2, 00 GESLACHT 1, 00 Count 3 2 % within KLEUR 50, 0% 2, 00 Count 3 2 % within KLEUR 50, 0% Total Count % within KLEUR Total 3, 00 2 7 100, 0% 58, 3% 5 41, 7% 6 4 2 12 100, 0%
C. De paradox van Simpson • Voorbeeld : ziekenhuizen overleden overleefd A 3% (63) 97% (2037) goede conditie A B overleden 1% (6) 1. 3% (8) overleefd 99% (594) 98. 7% (592) B 2% (16) 98% (784) slechte conditie A B 3. 8% (57) 4% (8) 96. 2% (1433) 96% (192)
• Paradox van Simpson = de omkering van de richting van een relatie wanneer de data uit verscheidene groepen gecombineerd worden tot een enkele groep • Oorzaak : een verborgen derde variabele – beter om een driedimensionale tabel te maken zodat elke variabele zichtbaar wordt – nooit uitspraken op grond van eerste indruk, steeds grondig onderzoeken en nadenken – Samenvoegen van drie variabelen naar twee variabelen is altijd gevaarlijk: info verlies
2. 7. Oorzaak en gevolg • Dikwijls : onafhankelijke variabelen veroorzaken afhankelijke variabelen • MAAR dit is vaak niet terecht – snelheidslimiet - minder verkeersdoden – wet op wapenbezit - minder moorden Kunnen we hier echt spreken van een OORZAAK ? => dikwijls naast deze ene onafhankelijke variabele nog veel andere die een rol spelen
• Echte oorzaak-gevolg relatie uit toekomstgericht onderzoek, longitudinaal waarbij personen jaren gevolgd worden • Steeds zoeken naar verborgen variabelen ! Voorbeeld : roken - longkanker - genetische hypothese - “slonzige levensstijl”
• Samenhang tussen x en y kan : 1. Oorzaak en gevolg : veranderingen in x veroorzaken veranderingen in y 2. Gemeenschappelijke afhankelijkheid : zowel x als y reageren op veranderingen in verborgen variabelen 3. Verstrengeling : naast x zijn er nog zoveel andere factoren die een effect hebben op y (bv. SES)
• Figuur : 1 x y 2 x y z 3 x y z
• Hoe een oorzaak-gevolg relatie vastleggen ? EXPERIMENT = enige bevredigende methode : bij wijziging van x ook veranderingen in y waarbij verborgen variabelen beheerst worden • Als experimenten niet mogelijk zijn : – verschillende onderzoeken, verschillende groepen – effect blijft na opnemen van derde variabelen – plausibele verklaring is noodzakelijk – samenhang is sterk