Hierarchical Beta Process and the Indian Buffet Process

Hierarchical Beta Process and the Indian Buffet Process by R. Thibaux and M. I. Jordan Discussion led by Qi An
 Beta process (BP) Connections between IBP")
Outline • • Introduction Indian buffet process (IBP) Beta process (BP) Connections between IBP and BP Hierarchical beta process (h. BP) Application to document classification Conclusions

Introduction • Mixture models VS. – Each data is drawn from one mixture component – Number of mixture components is not set a prior – Distribution over partitions • Factorial models – Each data is associated with a set of latent Bernoulli variables – Cardinality of the set of features can vary – A “featural” description of objects – A natural way to define interesting topologies on cluster – May be appropriate for large number of clusters


Beta process is a special case of independent increment process, or Levy process, Levy process can be characterized by Levy measure. For beta process, it is If we draw a set of points measure v, then from a Poisson process with base As the representation shows, B is discrete with probability one. When the base measure B 0 is discrete: locations with , then B has atoms at the same
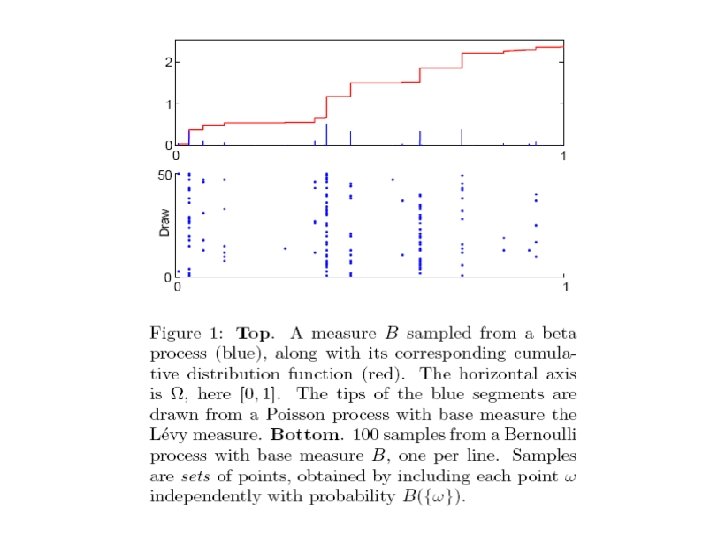

Bernoulli process Here, Ω can be viewed as a set of potential features and the random measure B defines the probability that X can possess particular feature. In Indian buffet process, X is the customer and its features are the dishes the customer taste.

Connections between IBP and BP It is proven that the observations from a beta process satisfy Procedure: The first customer will try Poi(γ) number of dishes (feature). After that , the new observation can taste previous dish j with probability and then try a number of new features where is the total mass As a result, beta process is a two-parameter (c, γ) generalization of the Indian buffet process. IBP=BP(c=1, γ=α)

The total number of unique dishes can be roughly represented as This quantity becomes Poi(γ) if c 0 (all customers share the same dishes) or Poi(n γ) if c ∞ (no sharing).

An algorithm to generate beta process Authors propose to generate an approximation, Let For each step n≥ 1 , of B

Hierarchical beta process Consider a document classification problem. We have a training data set X, which is a list of documents. Each document is classified by one of n topics. We model a document by the set of words it contains. We assume document Xi, j is generated by including each word w independently with a probability pjw specific to topic j. These probabilities form a discrete measure Aj over all word space Ω. We can put a beta process BP(cj, B) prior on Aj. Since we want the sharing across different topics, B has to be discrete. We thus put a beta process prior BP(c 0, B 0) on B, which allows sharing the same atoms among topics. The HBP model can be summarized as: This model can be solved with Monte Carlo inference algorithm.
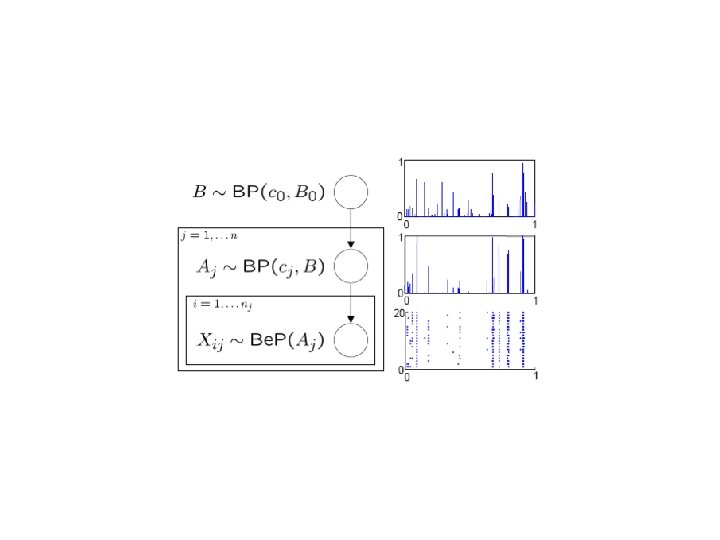

Applications • Authors applied the hierarchical beta process to a document classification problem • Compare it to the Naïve Bayes (with Laplace smoothing) results • The h. BP model can obtain 58% result while the best Naïve Bayes result is 50%

Conclusions • The beta process is shown to be suitable for nonparametric Bayesian factorial modeling • The beta process can be extended to a recursively-defined hierarchy of beta process • Compared to the Dirichlet process, the beta process has the potential advantage of being an independent increments process • More work on inference algorithm is necessary to fully exploit beta process models.
- Slides: 14