Helper Threads via Virtual Multithreading on an experimental



 l l l Each hardware thread context is")















- Slides: 20
Helper Threads via Virtual Multithreading on an experimental Itanium 2 processor platform. Perry H Wang et. Al.
Outline l l l Helper threads VMT ideas Implementation details • Hardware • Firmware • Compiler Results Conclusion.
Helper threads l l Used in Multi-threaded architectures to prefetch hard-to-predict delinquent data or compute hard-to-predict branches. Threads share resources as fetch bandwith and functional units.
Hyper Threading (Intel - P 4) l l l Each hardware thread context is exposed as logical processor to the OS. OS finds threads for execution and binds them to the logical processor. User has to use OS-visible thread API to create and manage threads.
Helper Threads - Issues l l Resource contention among multiple helper threads Adaptable invocation for different program phases. • Threads have to be self-throttling. l OS based thread synchronization is unpredictable and has long latency ( ~micro secs)
Virtual Multithreading l l l Single processor supports multiple thread contexts. Monitors long latency micro-architectural events. Switches to different Instruction in same program in 100 cycles. OS transparent Uses firmware support in Itanium 2 processor to reduce context switch time.
Context switch requires
Advantages with VMT on Itanium l l Ability to track micro-architectural events without involvement of the OS. Eg: Last level cache misses. Large register set partitioned by compiler for helper threads • • l Register communication is easier Value Synchronization - no memory comm. OS context switches allow threads to be resumed on any processor.
New Instructions l Yield ØSynchronous transfer to VMT thread, similar to branch misprediction l Yield conditional ØTransfer only when pipeline stalls at some later instruction. ØExecution proceed, instructions retire ØNo pipeline stall instruction behaves as nop
Key Characteristics l Self throttling – main and helper threads keep counters to track progress (iteration counter) • • l l Helper thread falls behind -> reload value Helper thread runs too far ahead -> relinquish ctrl. Main thread begins execution at instruction that triggered helper thread invocation. VMT preserves thread continuation of helper threads -> helper thread can restart where it stopped.
Key Characteristics l VMT has to maintain l Compiler preserves 2 registers for the purpose. Support for multiple helper threads can be done by reprogramming these registers. l • Initial instruction address. • Continuation instruction address
Itanium Firmware l Programmable debugging hardware support for PAL • l l To enable silicon debugging & validation. PAL can program PMU to monitor and count events of interest - opcode monitoring, instruction addr. , Data addr. Debugging hardware can trigger a PAL handler when the monitored even occurs.
Firmware l l VMT mechanism emulated by firmware infrastructure. Opcode monitoring to simulate yield and yield conditional. PAL programs PMU to track • Last level cache misses • Pipeline stalls • Instructions with special opcodes. Thread switch latency = pipeline flush + overhead for manipulating registers. (~140 cycles giving 60 cycles of computation time when memory miss ~200 cycles)
Experimental machine. l l 4 way 1. 5 Ghz Itanium 2 processor based MP system with 16 GB of RAM. Separate 16 KB 4 -way set associate L 1 I- and Dcache Shared 256 KB 8 -way set associative L 2 cache. 6 MB 24 -way L 3 cache that can be configured as 1 MB 4 -way set associative cache.
workloads l l l MCF – combinatorial optimization. VPR – FPGA Circuit Placement and Routing DOT – graph layout optimization tool l DSS system running on 100 GB IBM DB 2 database 6 queries with long run time and span large portions of database. 95% cpu utilization, 40 concurrent threads
Compiler and optimizations l l Electon –O 3, IPA, Profile guided opt. , Itanium 2 specific opt. Recompiled to obtain threads and linked with original binaries. • • • Register partitioning to minimize VMT context switch Aggressive software prefetching with profile feedback. Ld. s , chk, predication, branch prediction hints.
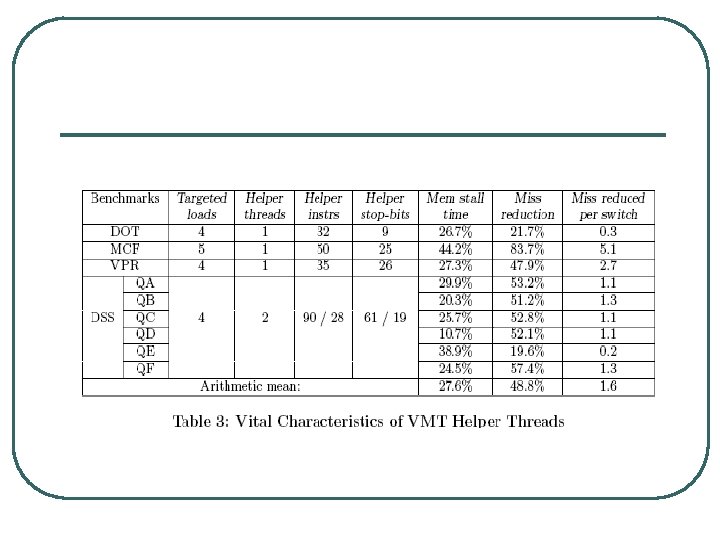
Speed. Up l l l A few helper threads give good speedup Significant fraction of L 3 misses are removed from main thread (avg. 48%). Capacity misses in L 3 are due to pointer chasing. Helper thread size is small. Helper thread can contain control flow dependencies also. Throughput improved by reducing latency of individual threads
Conclusion l l Fly-weight context switching 5. 8 – 38. 5% increase for SPEC 2000 INT 5 -12% speedup on DSS workload. VMT threads are to be invoked based on program behavior depending on number of cache misses.
My view on limitations l l Requires large register files and firmware support. Too Itanium (not adaptable to other architectures). Scalability of helper threads. (# helper threads running at one time…to complex)