Hbase The HBase HBase is a distributed columnoriented

Hbase

The HBase • HBase is a distributed columnoriented database built on top of HDFS. – Easy to scale to demand • HBase is the Hadoop application to use when you require real-time read/write random-access to very large datasets. – Use Map. Reduce to search • HBase depends on Zoo. Keeper and by default it manages a Zoo. Keeper instance as the authority on cluster state.

Data Model • A data model similar to Bigtable. – a data row has a sortable row key and an arbitrary number of columns – the table is stored sparsely, rows in the same table can have widely varying numbers of columns Conceptual View Physical Storage View

Example • Capture network packets into HDFS, save to a file for every minute. • Run Map. Reduce app, estimate flow status. – count tcp, udp, icmp packet number – compute tcp, udp, or all packet flow • The result save to HBase. – row key and timestamp are the captrue time Row-key Timesta mp Tcp: count Tcp: flow Udp: coun Udp: flow t … 2001003 291011 1269852 90000 2423432 7989010 927 387897 8991645 466 … 2010032 91012 1269852 96000 2899787 1093999 3009 481241 8163769 889 … … … …

Display • Specify start time and stop time to scan table then estimate data and display as flow graph. • Sample output

The performance of accessing files to HDFS directly and through a HDFS-based FTP server
 • ssh登入namenode下達指令 – 上傳檔案至HDFS: • hadoop fs -Ddfs.")
Accessing files to HDFS directly (1/7) • ssh登入namenode下達指令 – 上傳檔案至HDFS: • hadoop fs -Ddfs. block. size=資料區塊位元組數 Ddfs. replication=資料區塊複製數量 -put 本機資料 HDFS檔案目錄 – 由HDFS下載檔案: • hadoop fs -get HDFS上的資料 本機目錄

 1 M 2 M 4 M 8")
Accessing files to HDFS directly (3/7, R=1) 1 M 2 M 4 M 8 M 16 M 32 M 64 M 128 M 256 M 512 M MB級(100 MB) GB級(3. 3 GB) 4 120. 5 3. 7 103. 2 3. 4 93. 5 3. 2 81. 7 2. 7 84. 8 2. 5 65. 9 1. 8 65. 1 1. 9 51. 6 1. 9 62. 7 1. 9 77 (橫軸表示資料分割區塊大小,單位:byte) (縱軸表示一份資料完全寫入HDFS所需要的時間, 單位:秒)
 1 M 2 M 4 M 8")
Accessing files to HDFS directly (4/7, R=1) 1 M 2 M 4 M 8 M 16 M 32 M 64 M 128 M 256 M 512 M MB級(100 MB) GB級(3. 3 GB) 2. 3 61. 5 2. 2 63 2. 1 62. 4 2. 1 61. 8 2. 1 61. 7 2. 1 62. 2 2. 1 60. 1 2 61. 8 2 63. 1 2 62. 1 (橫軸表示資料分割區塊大小,單位:byte) (縱軸表示一份資料完全從HDFS讀出所需要的時間,單位:秒)
 1 M 2 M 4 M 8")
Accessing files to HDFS directly (5/7, R=2) 1 M 2 M 4 M 8 M 16 M 32 M 64 M 128 M 256 M 512 M MB級(100 MB) GB級(3. 3 GB) 3. 8 224. 5 3. 4 190. 1 3. 2 147 3 131. 2 2. 8 133. 5 3. 1 124. 9 3. 2 118. 7 3. 2 120. 5 3. 3 143. 3 124. 9 (橫軸表示資料分割區塊大小,單位:byte) (縱軸表示一份資料完全寫入HDFS所需要的時間,單位:秒)
 1 M 2 M 4 M 8")
Accessing files to HDFS directly (6/7, R=2) 1 M 2 M 4 M 8 M 16 M 32 M 64 M 128 M 256 M 512 M MB級(100 MB) GB級(3. 3 GB) 2. 3 63. 4 2. 3 61. 5 2. 2 61. 5 2. 1 60. 1 2 60 2. 1 58. 4 1. 9 58 2. 1 61. 7 2 61. 5 2 58. 5 (橫軸表示資料分割區塊大小,單位:byte) (縱軸表示一份資料完全從HDFS讀出所需要的時間,單位:秒)

 • 使用者用FTP client連上FTP server後 – lfs表示一般的FTP server")
Accessing files through a HDFSbased FTP server(1/3) • 使用者用FTP client連上FTP server後 – lfs表示一般的FTP server daemon直接存取 local file system。 – HDFS表示由我們撰寫的FTP server daemon, 透過與位在同一台server上的Name. Node daemon溝通後,存取HDFS。 • 之後上傳/下載完檔案花費之總秒數皆為 測量 3次秒數平均後之結果 • 網路頻寬約維持在 10 Mb/s~12 Mb/s間
 (橫軸:上傳單一檔案GB數) (縱軸:上傳完檔案花費總秒數) (HDFS:檔案區塊大小 128 MB,複製數=2) lfs HDFS")
Accessing files through a HDFSbased FTP server(2/3) (橫軸:上傳單一檔案GB數) (縱軸:上傳完檔案花費總秒數) (HDFS:檔案區塊大小 128 MB,複製數=2) lfs HDFS 0. 5 GB 46. 33 62. 33 1. 0 GB 95 138. 67 1. 5 GB 141. 67 199 2. 0 GB 188. 67 270 2. 5 GB 237 346 3. 0 GB 288. 33 400 3. 5 GB 345 471 4. 0 GB 383. 67 472
 (橫軸:下載單一檔案GB數) (縱軸:下載完檔案花費總秒數) (HDFS:檔案區塊大小 128 MB,複製數=2) lfs HDFS")
Accessing files through a HDFSbased FTP server(3/3) (橫軸:下載單一檔案GB數) (縱軸:下載完檔案花費總秒數) (HDFS:檔案區塊大小 128 MB,複製數=2) lfs HDFS 0. 5 GB 48 45 1. 0 GB 92 91 1. 5 GB 141 137. 33 2. 0 GB 192 185. 67 2. 5 GB 236. 67 226. 33 3. 0 GB 273. 33 278 3. 5 GB 322 320. 33 4. 0 GB 380. 33 378. 67

Hadoop認證分析 • the name node has no notion of the identity of the real user。(沒有真實用戶的概念) • User Identity : – The user name is the equivalent of「whoami」. – The group list is the equivalent of「bash -c groups」. • The super-user is the user with the same identity as name node process itself. If you started the name node, then you are the super-user.

Why Using Proxy to connect name node • Data. Nodes do not enforce any access control on accesses to its data blocks。(client可與datanode 直接連線,提供Block ID即可read、write)。 • Hadoop client(any user)can access HDFS or submit Mapreduce Job。 • Hadoop only works with SOCKS v 5. ( in client, Client. Protocol and Submission. Protocol ) • 結論:hadoop(Private IP叢集)+ RADIUS + SOCKS proxy。
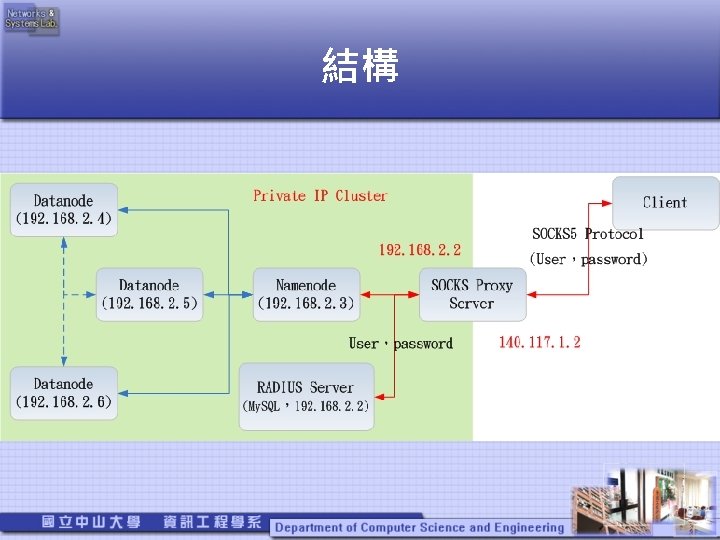
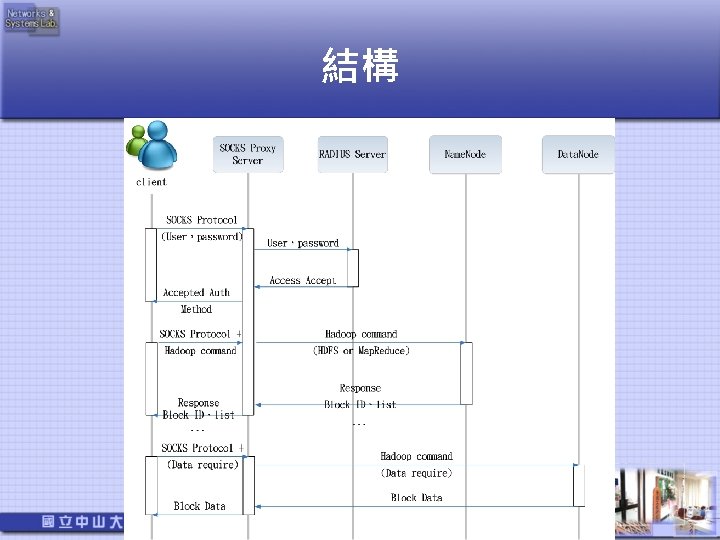

Hadoop SOCKS • 只需在Hadoop client設定SOCKS連線,Namenode無需設定。
辨識Proxy transfer的權限。 • 由RADIUS Server紀錄user是否可以存取hadoop。 (user-group) • User使用Hadoop client(whoami)的執行身分來存取")
User 認證 • 使用SOCKS protocol的method(username、 password)辨識Proxy transfer的權限。 • 由RADIUS Server紀錄user是否可以存取hadoop。 (user-group) • User使用Hadoop client(whoami)的執行身分來存取 Hadoop。

- Slides: 23