Hashing Techniques CST 203 2 Database Management Systems

Hashing Techniques CST 203 -2 Database Management Systems Lecture 7

�Disadvantages on index structure: � We must access an index structure to locate data, or must use binary search, and that results in more I/O operations � Space taken by index structure �Hashing allows us to avoid accessing an index structure

Hash File Organization �We obtain the address of the disk block containing a desired record directly by computing a function on the search-key value of the record �Bucket is a unit of storage that can store one or more records �A bucket is typically a disk block, but could be chosen to be smaller or larger than a disk block.
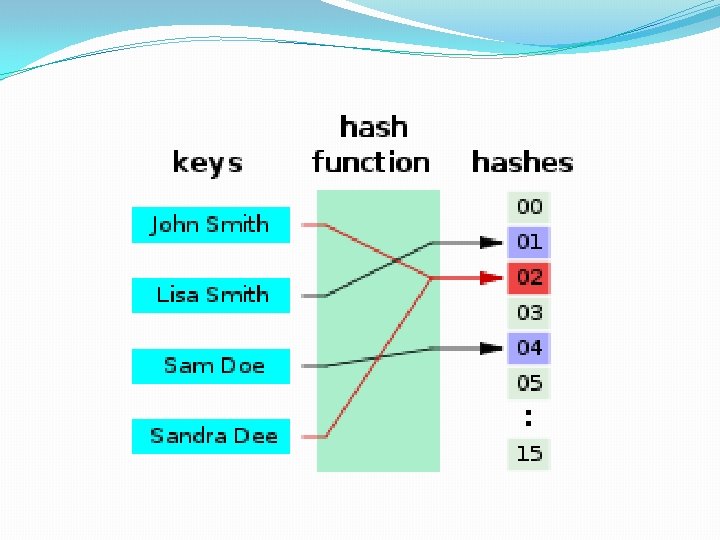

�A hash function h is a function from K to B. h – hash function Ki - search key Bi = h(Ki) �If h(K 5) = h(K 7) � bucket h(K ) contains records with search-key values K and records with search-key values K 5 5 7

Deletion �Equally straightforward �If the search-key value of the record to be deleted is Ki, we compute h(Ki), then search the corresponding bucket for that record, and delete the record from the bucket

Hash Functions �The worst possible hash function maps all search-key values to the same bucket �An ideal hash function distributes the stored keys uniformly across all the buckets, so that every bucket has the same number of records �We want to choose a hash function that assigns search -key values to buckets

�The distribution is uniform. � The hash function assigns each bucket the same number of search-key values from the set of all possible search-key values �The distribution is random � Each bucket will have nearly the same number of values assigned to it, regardless of the actual distribution of searchkey values. � The hash value will not be correlated to any externally visible ordering on the search-key values, such as alphabetic ordering or ordering by the length of the search keys
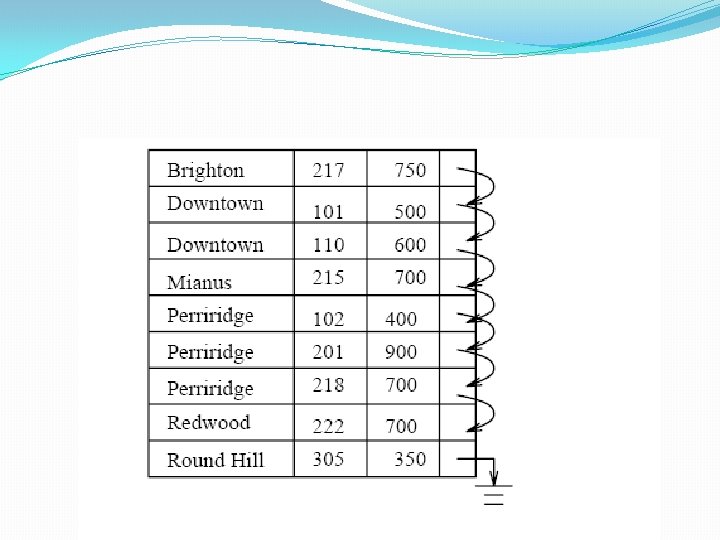
 Hash file organization of account file, using")
Example of Hash File Organization (Cont. ) Hash file organization of account file, using branch-name as key � Assume……. . There are 26 buckets � hash function maps names beginning with the ith letter of the alphabet to the ith bucket � Simple but no uniform distribution � Assume……… there are 10 buckets, � The binary representation of the ith character is assumed to be the integer i. � The hash function returns the sum of the binary representations of the characters modulo 10 � E. g. h(Perryridge) = 5 h(Round Hill) = 3 h(Brighton) = 3
 {")
int h = 0; for (int i = 0; i < n; i++) { h = h + s. char. At(i); } h = h % 10;

Example of Hash File Organization Hash file organization of account file, using branch-name as key

Handling of Bucket Overflows �We have assumed that, when a record is inserted, the bucket to which it is mapped has space to store the record �If the bucket does not have enough space, a bucket overflow is said to occur �Reasons: Insufficient buckets. � Skew � 1. Multiple records may have the same search key. 2. The chosen hash function may result in non-uniform distribution of search keys.

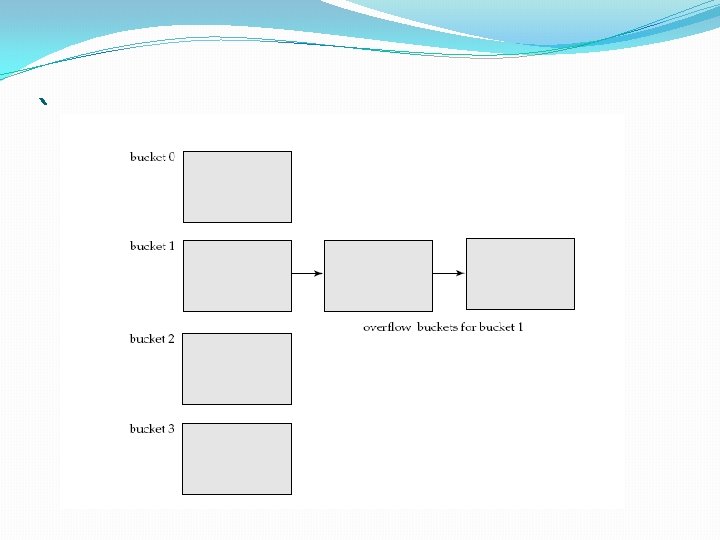
�We handle bucket overflow by using overflow buckets. �If a record must be inserted into a bucket b, and b is already full, �the system provides an overflow bucket for b, and inserts the record into the overflow bucket. �If the overflow bucket is also full, the system provides another overflow bucket, and so on �All the overflow buckets of a given bucket are chained together in a linked list(overflow chaining)

Hash Indices �A hash index organizes the search keys, with their associated pointers, into a hash file structure �We apply a hash function on a search key to identify a bucket, and store the key and its associated pointers in the bucket (or in overflow buckets)
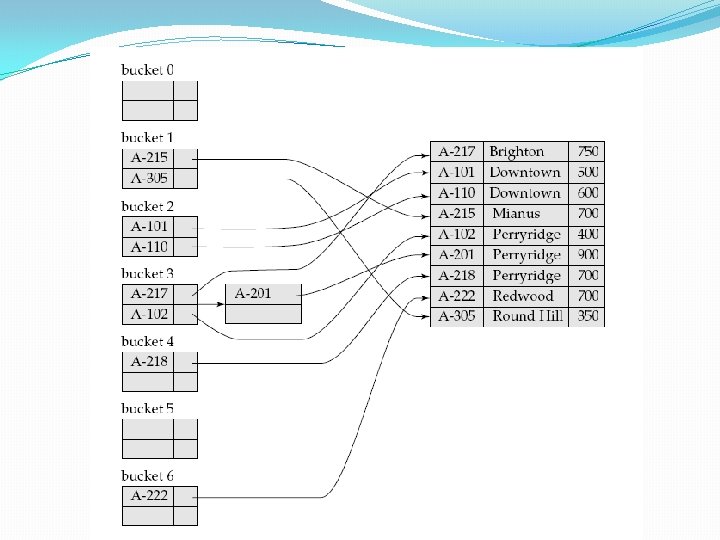

�The term hash index is used to denote hash file structures as well as hash indices �Hash indices are only secondary index structures �But, hash file organization provides the same direct access to records that indexing provides, we pretend that a file organized by hashing also has a primary hash index on it

Dynamic Hashing �Most databases grow larger over time �For static hashing, Choose a hash function based on the current file size. This option will result in performance degradation as the database grows � Choose a hash function based on the anticipated size of the file at some point in the future. Although performance degradation is avoided, a significant amount of space may be wasted initially � Periodically reorganize the hash structure in response to file growth. Such a reorganization involves choosing a new hash function, recomputing the hash function on every record in the file, and generating new bucket assignments. This reorganization is a massive, time-consuming operation. Furthermore, it is necessary to forbid access to the file during reorganization. �
- Slides: 19