Handwritten digit recognition By Levit Gregory INTRODUCTION n

Handwritten digit recognition By Levit Gregory

INTRODUCTION n The subject of “Handwritten digit recognition” is of great concern and has many applications in various fields like zip code recognition.

Handwritten digit recognition The statistical approach The semantic approach The voting Algorithms

Reasons for choosing statistical approach n n No usage of large training database is required. Low running time. Without resorting to neural-nets. Not many applications in the field of hand written digit recognition are done by statistical approach (only few articles deal with statistical method).

Statistical approach one is searching for the statistical characteristics of various digits, these characteristics could be very simple, like: n the ratio of black pixels to white pixels, E. g. an image of the digit "1" will have relatively fewer black pixels than an image of the digit "8" though both are drawn to the same scale

n Continuing the same approach, cursory analysis shows that the ratio of height to width for the digit "0" is less than the same ratio for the digit "6“.

n by careful analysis of the histograms of various digits, it is possible to differentiate between them.

Principles of my method n For example, take the following binary image of the number 8 (already cropped).

n First I draw 5 horizontal rays through the image (spacing is determined on the fly, depending on size of cropped image). The number of intersections along each ray is recorded.

n n Similarly 5 vertical rays are shot and recorded. . . Finally the Euler number (Scalar whose value is the total number of objects in the image minus the total number of holes in those objects) is recorded in the last array entry.

n n n This recorded array can be regarded as an vector in the intersection space (I-space), I use 11 dimension space (10 intersecting lines + 1 Euler number). In the I-space there are 10 constant vectors composing the training set, those vectors are acquired from 10 default images kept in the programs data base. Each one of the vector represent a digit from ‘ 0’ to ‘ 9’. A new input image is projected to I space, thus converted to a vector.

n n The algorithm then finds the distance between the new vector and the 10 constant vectors. The minimal distance will give the best matching to one of the constant vectors. The recognition answer will be the digit represented by the constant vector.

Examples and Results n For training set I created an example of each digit 0 -9 using ms-paint. For testing I created 3 groups of 0 -9 digit images also in ms-paint. I tried to make each group more different, and assigned different image characteristics to each of them; like image size, marker size and handwriting style.
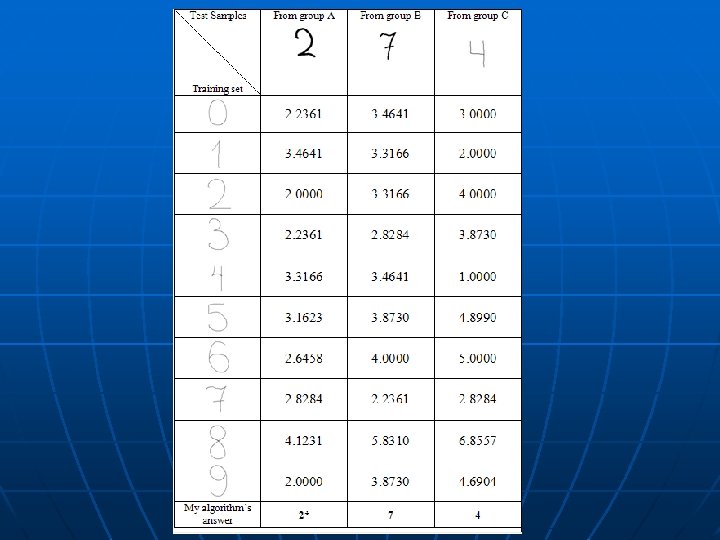
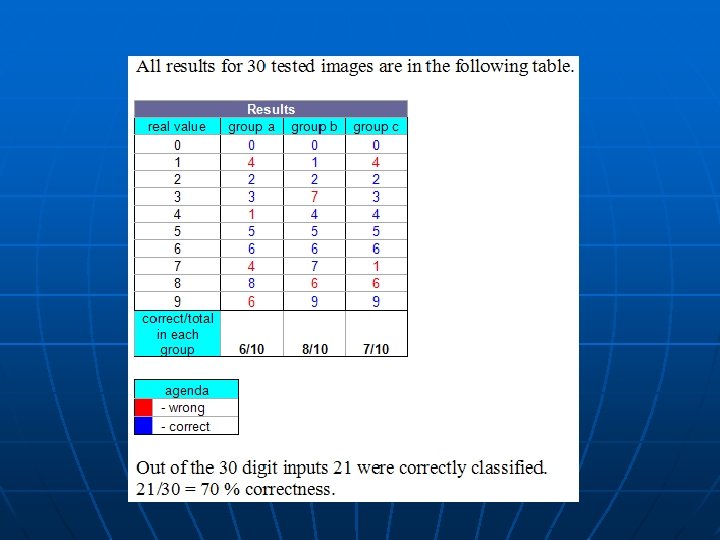

Conclusions n n n 70% success. Problematic pairs of digits have similar profile as can be seen from results table; ‘ 4’ and ‘ 1’, ‘ 7’ and ‘ 1’, ‘ 6’ and ‘ 8’. NOT Orientation/Rotation invariant. Writing styles matter (weird 7's or incomplete zeros). Salt and pepper noise can throw off results.
- Slides: 16