Handling Streaming Data in Spotify Using the Cloud








































![Scio Ecclesiastical Latin IPA: /ˈʃi. o/, [ˈʃiː. o], [ˈʃi. i o] Verb: I can,](https://slidetodoc.com/presentation_image/54874bacf00137c0a8ab4d44021fc1ca/image-41.jpg "Scio Ecclesiastical Latin IPA: /ˈʃi. o/, [ˈʃiː. o], [ˈʃi. i o] Verb: I can,")

 sc. text.")
![Page. Rank def page. Rank(in: SCollection[(String, String)]) = { val links = in. group.](https://slidetodoc.com/presentation_image/54874bacf00137c0a8ab4d44021fc1ca/image-44.jpg "Page. Rank def page. Rank(in: SCollection[(String, String)]) = { val links = in. group.")

 100 GB recommendations")






- Slides: 56
Handling Streaming Data in Spotify Using the Cloud Igor Maravić <igor@spotify. com> Software Engineer Neville Li <neville@spotify. com> Software Engineer
Current Event Delivery System
Current event delivery system Client Any data centre Client Gateway Hadoop data centre Service Discovery Liveness Monitor Client Checkpoin t Monitor Syslog Producer ACK Brokers Syslog Consumer s Grouper s Realtime Brokers Hadoop ETL job
Complex Client Any data centre Client Gateway Hadoop data centre Service Discovery Liveness Monitor Client Checkpoin t Monitor Syslog Producer ACK Brokers Syslog Consumer s Grouper s Realtime Brokers Hadoop ETL job
Stateless Client Any data centre Client Gateway Hadoop data centre Service Discovery Liveness Monitor Client Checkpoin t Monitor Syslog Producer ACK Brokers Syslog Consumer s Grouper s Realtime Brokers Hadoop ETL job
Delivered data growth
Redesigning Event Delivery
Redesigning event delivery Hadoop data centre Client Hadoop Any data centre Client Gateway Client Syslog File Tailer Event Delivery Service Reliable Persiste nt Queue ETL
Same API Hadoop data centre Client Hadoop Any data centre Client Gateway Client Syslog File Tailer Event Delivery Service Reliable Persiste nt Queue ETL
Dedicated event streams Hadoop data centre Client Hadoop Any data centre Client Gateway Client Syslog File Tailer Event Delivery Service Reliable Persiste nt Queue ETL
Persistence Hadoop data centre Client Hadoop Any data centre Client Gateway Client Syslog File Tailer Event Delivery Service Reliable Persiste nt Queue ETL
Keep it simple Hadoop data centre Client Hadoop Any data centre Client Gateway Client Syslog File Tailer Event Delivery Service Reliable Persiste nt Queue ETL
Choosing Reliable Persistent Queue
Kafka 0. 8
Event delivery with Kafka 0. 8 Client Any data centre Client Gateway Brokers Client Hadoop data centre Mirror Makers Hadoop Syslog File Tailer Event Delivery Service Brokers Camus (ETL)
Event delivery with Kafka 0. 8 Client Any data centre Client Gateway Brokers Client Hadoop data centre Mirror Makers Hadoop Syslog File Tailer Event Delivery Service Brokers Camus (ETL)
Cloud Pub/Sub
2 M QPS published to Pub/Sub 2 M/s 1. 5 M/s 1 M/s 500 k/s 0/s
Event delivery with Cloud Pub/Sub Client Any data centre Client Gateway Hadoop data centre Cloud Storage Hadoop Client Syslog Client File Tailer Event Delivery Service Cloud Pub/Sub ETL
ETL
Event time based hourly buckets 2016 -032123 H 2016 -032200 H 2016 -032201 H 2016 -0322 02 H 2016 -032203 H 2016 -032204 H
Incremental bucket fill 2016 -032123 H 2016 -032200 H 2016 -032201 H 2016 -0322 02 H 2016 -032203 H 2016 -032204 H
Bucket completeness 2016 -032123 H 2016 -032200 H 2016 -032201 H 2016 -0322 02 H 2016 -032203 H 2016 -032204 H
Late data handling 2016 -032123 H 2016 -032200 H 2016 -032201 H 2016 -0322 02 H 2016 -032203 H 2016 -032204 H
Experimentatio n with Dataflow
ETL as a set of micro-services Hadoop data centre Completionist Cloud Pub/Sub Hadoop Cloud Storage Consumer Deduper
Consumer Hadoop data centre Completionist Cloud Pub/Sub Hadoop Cloud Storage Consumer Deduper
Completionist Hadoop data centre Completionist Cloud Pub/Sub Hadoop Cloud Storage Consumer Deduper
Deduper Hadoop data centre Completionist Cloud Pub/Sub Hadoop Cloud Storage Consumer Deduper
Where are we right now? Hadoop data centre Completionist Cloud Pub/Sub Hadoop Cloud Storage Consumer Deduper
Scio A Scala API for Google Cloud Dataflow
Origin Story Scalding and Spark ML, recommendations, analytics 50+ users, 400+ unique jobs Growing rapidly
Moving to Google Cloud Early 2015 - Dataflow Scala hack project
Why not Scalding on GCE Pros • Community Twitter, e. Bay, Etsy, Stripe, Linked. In, … • Stable and proven
Why not Scalding on GCE Cons • Hadoop cluster operations • Multi-tenancy resource contention and utilization • No streaming mode (Summingbird? )
Why not Spark on GCE Pros • Batch, streaming, interactive and SQL • MLlib, Graph. X • Scala, Python, and R support • Zeppelin, spark-notebook, Hue
Why not Spark on GCE Cons • Hard to tune and scale • Cluster lifecycle management
Why Dataflow with Scala Dataflow • Hosted solution, no operations • Ecosystem GCS, Big. Query, Pub. Sub, Bigtable, … • Unified batch and streaming model
Why Dataflow with Scala • High level DSL easy transition for developers • Reusable and composable code via FP • Numerical libraries: Breeze, Algebird
Scio Ecclesiastical Latin IPA: /ˈʃi. o/, [ˈʃiː. o], [ˈʃi. i o] Verb: I can, know, understand, have knowledge.
Core API similar to sparkcore Some ideas from scalding github. com/spotify/scio
Word. Count Almost identical to Spark version val sc = Scio. Context() sc. text. File("shakespeare. txt"). flat. Map(_. split("[^a-z. A-Z']+"). filter(_. non. Empty)). count. By. Value(). save. As. Text. File("wordcount. txt")
Page. Rank def page. Rank(in: SCollection[(String, String)]) = { val links = in. group. By. Key() var ranks = links. map. Values(_ => 1. 0) for (i <- 1 to 10) { val contribs = links. join(ranks). values. flat. Map { case (urls, rank) => val size = urls. size urls. map((_, rank / size)) } ranks = contribs. sum. By. Key. map. Values((1 - 0. 85) + 0. 85 * _) } ranks }
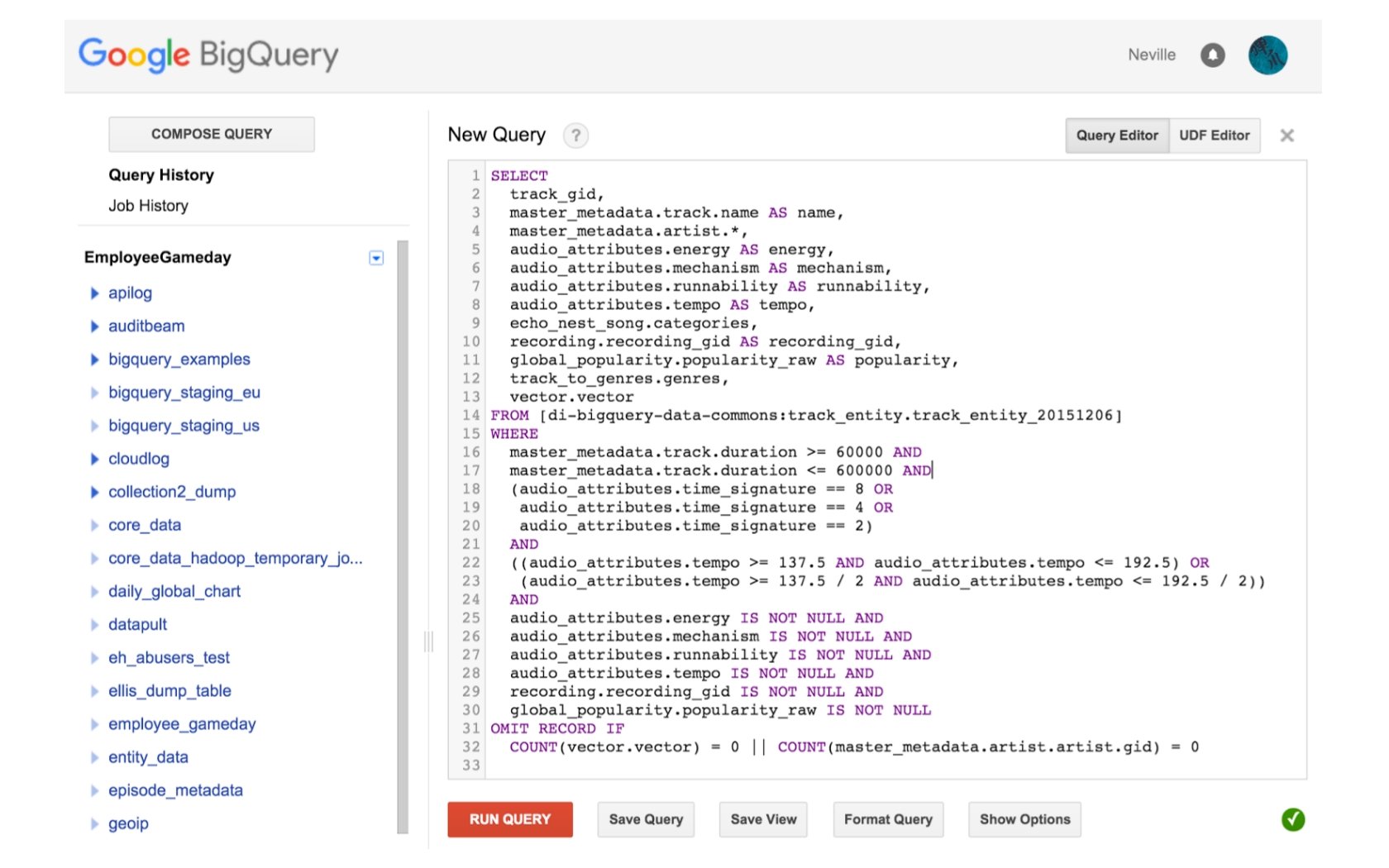
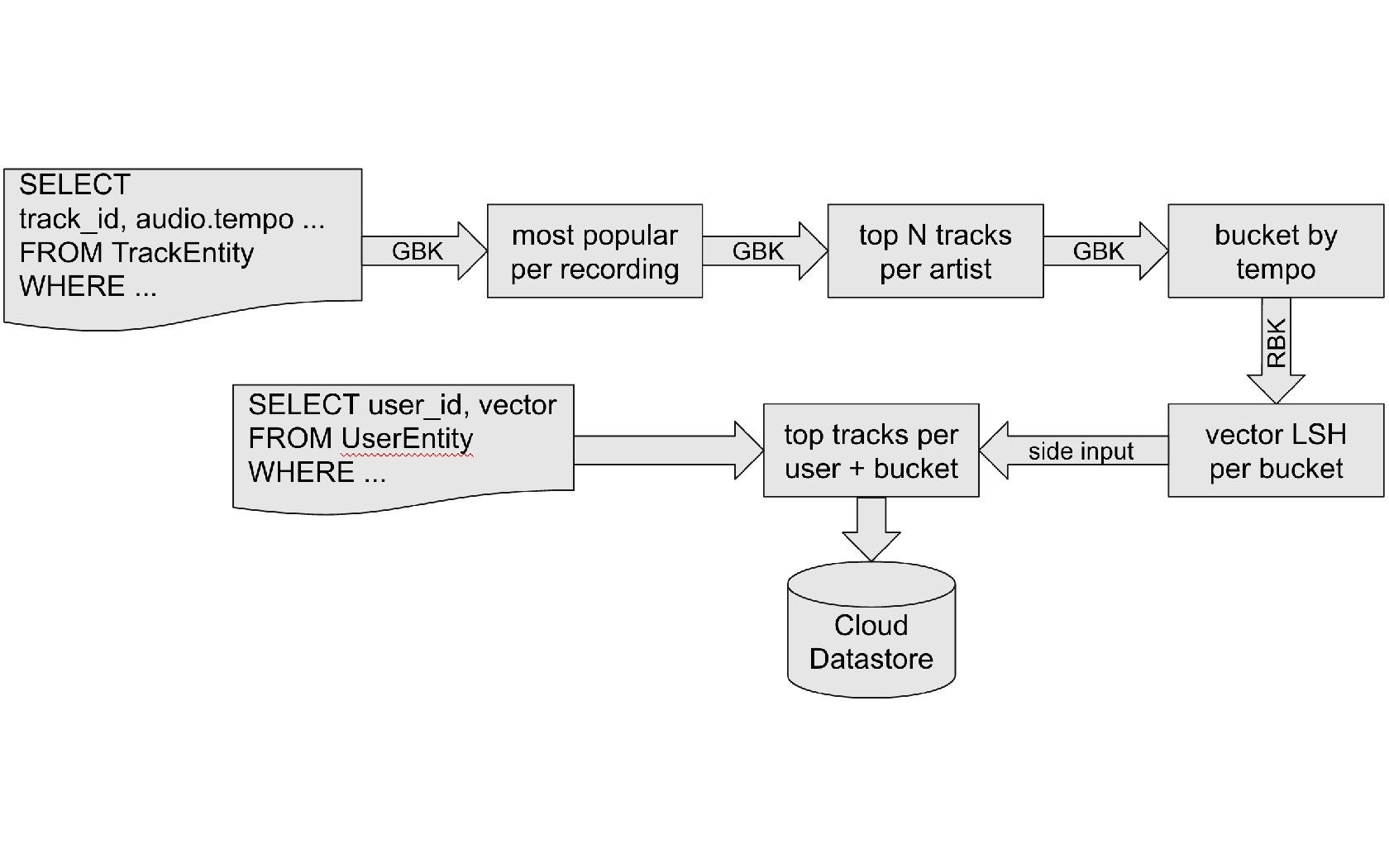
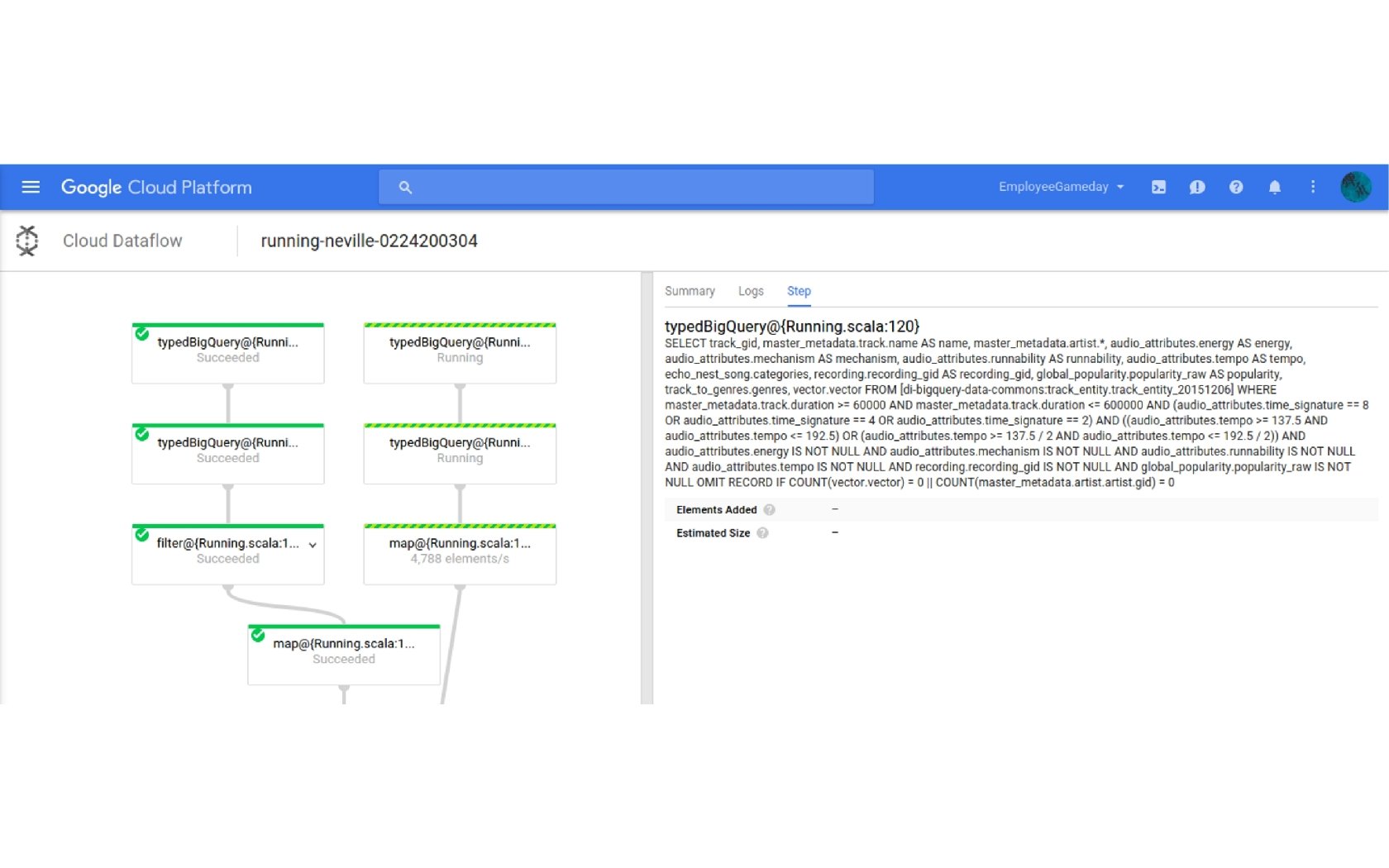
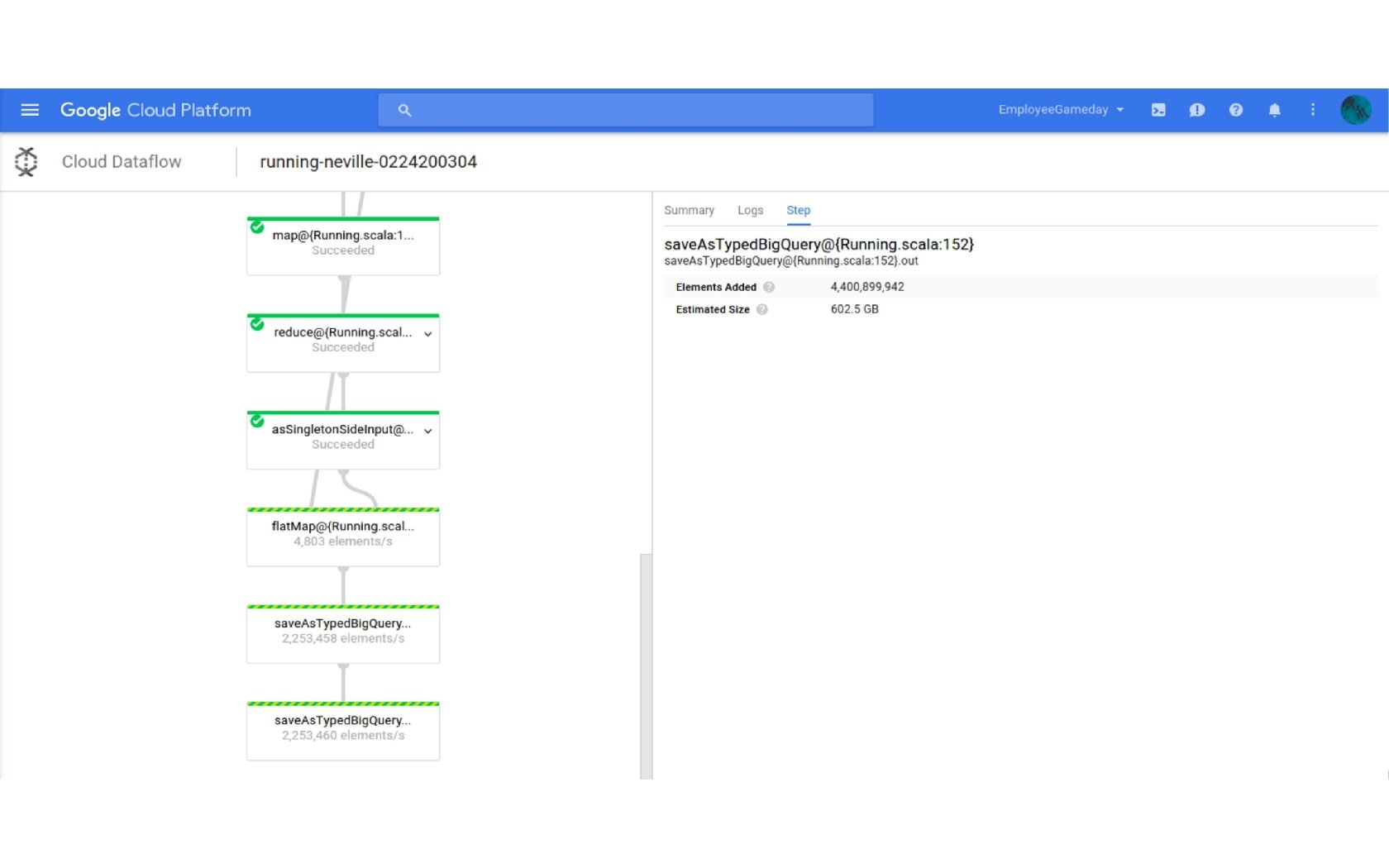
Spotify Running 60 million tracks 30 m users * 10 tempo buckets * 25 tracks Audio: tempo, energy, time signature. . . Metadata: genres, categories, … Latent vectors from collaborative filtering
Personalized new releases • • Pre-computed weekly on Hadoop (on-premise cluster) 100 GB recommendations from HDFS to Bigtable in US+EU 250 GB Bloom filters from Bigtable to HDFS 200 LOC
User conversion analysis • • For marketing and campaigning strategies Track user transitions through products Aggregated for simulation and projection 150 GB Big. Query in and out
Demo Time!
What’s next? • • • Migrating internal teams Big. Query SQL-2011 dialect Apache Beam migration Better streaming support PRs and issues welcome!
Learnings
Blog posts @ labs. spotify. com Spotify’s Event Delivery The Road To The Cloud Part I, Part III
Thank you! Igor Maravić <igor@spotify. com> Neville Li <neville@spotify. com>