GraphBased Methods for Open Domain Information Extraction William

Graph-Based Methods for “Open Domain” Information Extraction William W. Cohen Machine Learning Dept. and Language Technologies Institute School of Computer Science Carnegie Mellon University Joint work with Richard Wang

Traditional IE vs • Goal: recognize people, places, companies, times, dates, … in NL text. • Supervised learning from corpus completely annotated with target entity class (e. g. “people”) • Linear-chain CRFs • Language- and genre-specific extractors Open Domain IE • Goal: recognize arbitrary entity sets in text – Minimal info about entity class – Example 1: “ICML, NIPS” – Example 2: “Machine learning conferences” • Semi-supervised learning – from very large corpora (WWW) • Graph-based learning methods • Techniques are largely language-independent (!) – Graph abstraction fits many languages

Outline • History – Open-domain IE by pattern-matching • The bootstrapping-with-noise problem – Bootstrapping as a graph walk • Open-domain IE as finding nodes “near” seeds on a graph – – – Set expansion - from a few clean seeds Iterative set expansion – from many noisy seeds Relational set expansion Multilingual set expansion Iterative set expansion – from a concept name alone
 • • Start with seeds: “NIPS”, “ICML”")
History: Open-domain IE by patternmatching (Hearst, 92) • • Start with seeds: “NIPS”, “ICML” Look thru a corpus for certain patterns: • • • … “at NIPS, AISTATS, KDD and other learning conferences…” Expand from seeds to new instances Repeat…. until ___ – “on PC of KDD, SIGIR, … and…”

Bootstrapping as graph proximity NIPS “…at NIPS, AISTATS, KDD and other learning conferences…” AISTATS SNOWBIRD “For skiiers, NIPS, SNOWBIRD, … and…” SIGIR KDD … “on PC of KDD, SIGIR, … and…” “… AISTATS, KDD, …” shorter paths ~ earlier iterations many paths ~ additional evidence
 – (Wang & Cohen, ICDM 07) • Basic")
Set Expansion for Any Language (SEAL) – (Wang & Cohen, ICDM 07) • Basic ideas – Dynamically build the graph using queries to the web – Constrain the graph to be as useful as possible • Be smart about queries • Be smart about “patterns”: use clever methods for finding meaningful structure on web pages

1. 2. 3. Canon Nikon Olympus System Architecture 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. Pentax Sony Kodak Minolta Panasonic Casio Leica Fuji Samsung … • Fetcher: download web pages from the Web that contain all the seeds • Extractor: learn wrappers from web pages • Ranker: rank entities extracted by wrappers

The Extractor • Learn wrappers from web documents and seeds on the fly – Utilize semi-structured documents – Wrappers defined at character level • Very fast • No tokenization required; thus language independent • Wrappers derived from doc d applied to d only – See ICDM 2007 paper for details

. . Generally <a ref=“finance/ford”>Ford</a> sales … compared to <a ref=“finance/honda”>Honda</a> while <a href=“finance/gm”>General Motors</a> and <a href=“finance/bentley”>Bentley</a> …. 1. Find prefix of each seed and put in reverse order: • ford 1: /ecnanif”=fer a> yllarene. G … • Ford 2: >”drof/ /ecnanif”=fer a> yllarene. G … • honda 1: /ecnanif”=fer a> ot derapmoc … • Honda 2: >”adnoh/ /ecnanif”=fer a> ot … 2. Organize these into a trie, tagging each node with a set of seeds: yllarene. G … {f 1, h 1} /ecnanif”=fer a> {f 1, f 2, h 1, h 2} >” {f 2, h 2} ot derapmoc … {f 1} {h 1} drof/ /ecnanif”=fer a> yllarene. G. . adnoh/ /ecnanif”=fer a> ot. . {h 2} {f 2}

. . Generally <a ref=“finance/ford”>Ford</a> sales … compared to <a ref=“finance/honda”>Honda</a> while <a href=“finance/gm”>General Motors</a> and <a href=“finance/bentley”>Bentley</a> …. 1. Find prefix of each seed and put in reverse order: 2. Organize these into a trie, tagging each node with a set of seeds. 3. A left context for a valid wrapper is a node tagged with one instance of each seed. yllarene. G … {f 1, h 1} /ecnanif”=fer a> {f 1, f 2, h 1, h 2} >” {f 2, h 2} ot derapmoc … {f 1} {h 1} drof/ /ecnanif”=fer a> yllarene. G. . adnoh/ /ecnanif”=fer a> ot. . {h 2} {f 2}

. . Generally <a ref=“finance/ford”>Ford</a> sales … compared to <a ref=“finance/honda”>Honda</a> while <a href=“finance/gm”>General Motors</a> and <a href=“finance/bentley”>Bentley</a> …. 1. Find prefix of each seed and put in reverse order: 2. Organize these into a trie, tagging each node with a set of seeds. 3. A left context for a valid wrapper is a node tagged with one instance of each seed. 4. The corresponding right context is the longest common suffix of the corresponding seed instances. {f 1, h 1} “> yllarene. G … /ecnanif”=fer a> {f 1, f 2, h 1, h 2} >” ot derapmoc … {f 1} ”>Ford</a> sales … {h 1} ”>Honda</a> while … drof/ /ecnanif”=fer a> yllarene. G. . {f 2, h 2} </a> adnoh/ /ecnanif”=fer a> ot. . {h 2} {f 2}
*(document length))")
Nice properties: • There are relatively few nodes in the trie: • O((#seeds)*(document length)) • You can tag every node with the complete set of seeds that it covers • You can rank of filter nodes by any predicate over this set of seeds you want: e. g. , • covers all seed instances that appear on the page? • covers at least one instance of each seed? • covers at least k instances, instances with weight > w, … {f 1, h 1} “> yllarene. G … /ecnanif”=fer a> {f 1, f 2, h 1, h 2} >” ot derapmoc … {f 1} ”>Ford</a> sales … {h 1} ”>Honda</a> while … drof/ /ecnanif”=fer a> yllarene. G. . {f 2, h 2} </a> adnoh/ /ecnanif”=fer a> ot. . {h 2} {f 2}

I am noise Me too!

Differences from prior work • Fast character-level wrapper learning – Language-independent – Trie structure allows flexibility in goals • Cover one copy of each seed, cover all instances of seeds, … – Works well for semi-structured pages • Lists and tables, pull-down menus, javascript data structures, word documents, … • High-precision, low-recall data integration vs. High-precision, low-recall information extraction

The Ranker • Rank candidate entity mentions based on “similarity” to seeds – • Noisy mentions should be ranked lower Random Walk with Restart (GW) • …?

Google’s Page. Rank web site xxx web site a b cdefg web site yyyy pdq. . web site a b cdefg web site yyyy Inlinks are “good” (recommendations) Inlinks from a “good” site are better than inlinks from a “bad” site but inlinks from sites with many outlinks are not as “good”. . . “Good” and “bad” are relative.

Google’s Page. Rank web site xxx • follows a random link, or web site a b cdefg web site yyyy pdq. . web site a b cdefg web site yyyy Imagine a “pagehopper” that always either • jumps to random page
 web site xxx")
Google’s Page. Rank (Brin & Page, http: //www-db. stanford. edu/~backrub/google. html) web site xxx • follows a random link, or web site a b cdefg web site yyyy pdq. . web site a b cdefg web site yyyy Imagine a “pagehopper” that always either • jumps to random page Page. Rank ranks pages by the amount of time the pagehopper spends on a page: • or, if there were many pagehoppers, Page. Rank is the expected “crowd size”
 web site xxx • follows a")
Personalized Page. Rank (aka Random Walk with Restart) web site xxx • follows a random link, or web site a b cdefg web site yyyy pdq. . web site a b cdefg web site yyyy Imagine a “pagehopper” that always either • jumps to particular page

Personalize Page. Rank Random Walk with Restart web site xxx • follows a random link, or web site a b cdefg web site yyyy Imagine a “pagehopper” that always either pdq. . • jumps to a particular page P 0 • this ranks pages by the total number of paths connecting them to P 0 web site a b cdefg web site yyyy • … with each path downweighted exponentially with length

The Ranker • Rank candidate entity mentions based on “similarity” to seeds – • Noisy mentions should be ranked lower Random Walk with Restart (GW) • On what graph?

Building a Graph “ford”, “nissan”, “toyota” Wrapper #2 find northpointcars. com extract curryauto. com “chevrolet” 22. 5% “honda” 26. 1% Wrapper #3 derive Wrapper #1 “acura” 34. 6% “volvo chicago” 8. 4% Wrapper #4 “bmw pittsburgh” 8. 4% • A graph consists of a fixed set of… – Node Types: {seeds, document, wrapper, mention} – Labeled Directed Edges: {find, derive, extract} • Each edge asserts that a binary relation r holds • Each edge has an inverse relation r-1 (graph is cyclic) – Intuition: good extractions are extracted by many good wrappers, and good wrappers extract many good extractions,

Differences from prior work • Graph-based distances vs. bootstrapping – Graph constructed on-the-fly • So it’s not different? – But there is a clear principle about how to combine results from earlier/later rounds of bootstrapping • i. e. , graph proximity • Fewer parameters to consider • Robust to “bad wrappers”

Evaluation Datasets: closed sets

Evaluation Method • Mean Average Precision – – Commonly used for evaluating ranked lists in IR Contains recall and precision-oriented aspects Sensitive to the entire ranking Mean of average precisions for each ranked list Prec(r) = precision at rank r (a) Extracted mention at r matches any true mention where L = ranked list of extracted mentions, r = rank • Evaluation Procedure 1. (per dataset) Randomly select three true entities and use their first listed mentions as seeds 2. Expand the three seeds obtained from step 1 3. Repeat steps 1 and 2 five times 4. Compute MAP for the five ranked lists (b) There exist no other extracted mention at rank less than r that is of the same entity as the one at r # True Entities = total number of true entities in this dataset
![Experimental Results: 3 seeds Vary: � [Extractor] + [Ranker] + [Top N URLs] Extractor:](http://slidetodoc.com/presentation_image_h2/dce57f3e7fd0f6f28508719e29144dfd/image-26.jpg "Experimental Results: 3 seeds Vary: � [Extractor] + [Ranker] + [Top N URLs] Extractor:")
Experimental Results: 3 seeds Vary: � [Extractor] + [Ranker] + [Top N URLs] Extractor: • E 1: Baseline Extractor (longest common context for all seed occurrences� ) • E 2: Smarter Extractor (longest common context for 1 occurrence of each seed) Ranker: { EF: Baseline (Most Frequent), GW: Graph Walk } N URLs: � { 100, 200, 300 }

Side by side comparisons Telukdar, Brants, Liberman, Pereira, Co. NLL 06

Side by side comparisons Each. Movie vs WWW Ghahramani & Heller, NIPS 2005 NIPS vs WWW

Why does SEAL do so well? • Hypotheses: – More information appears in semi -structured documents than in free text – More semi-structured documents can be (partially) understood with character-level wrappers than with HTML-level wrappers Free-text wrappers are only 10 -15% of all wrappers learned: “Used [. . . ] Van Pricing" “Used [. . . ] Engines" “Bell Road [. . . ] " “Alaska [. . . ] dealership" “www. sunnyking[. . . ]. com"" “engine [. . . ] used engines" “accessories, [. . . ] parts" “is better [. . . ] or"

Comparing character tries to HTMLbased structures

Outline • History – Open-domain IE by pattern-matching • The bootstrapping-with-noise problem – Bootstrapping as a graph walk • Open-domain IE as finding nodes “near” seeds on a graph – – – Set expansion - from a few clean seeds Iterative set expansion – from many noisy seeds Iterative set expansion – from a concept name alone Multilingual set expansion Relational set expansion

A limitation of the original SEAL
 (Wang & Cohen, ICDM 2008) • Makes several")
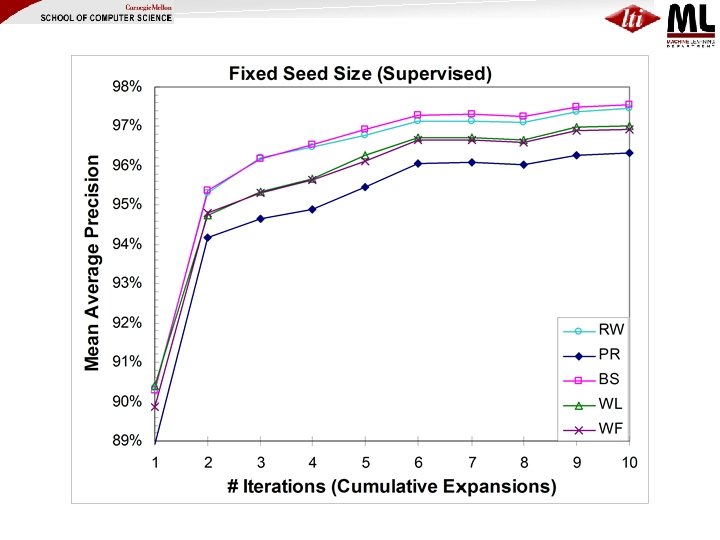
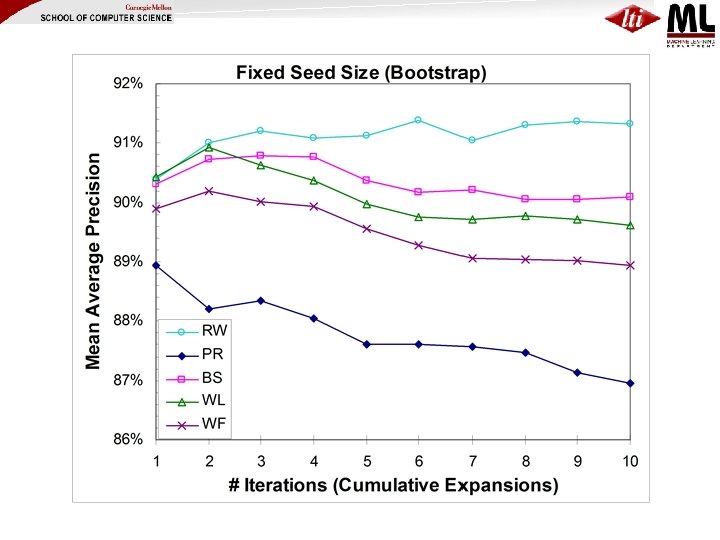
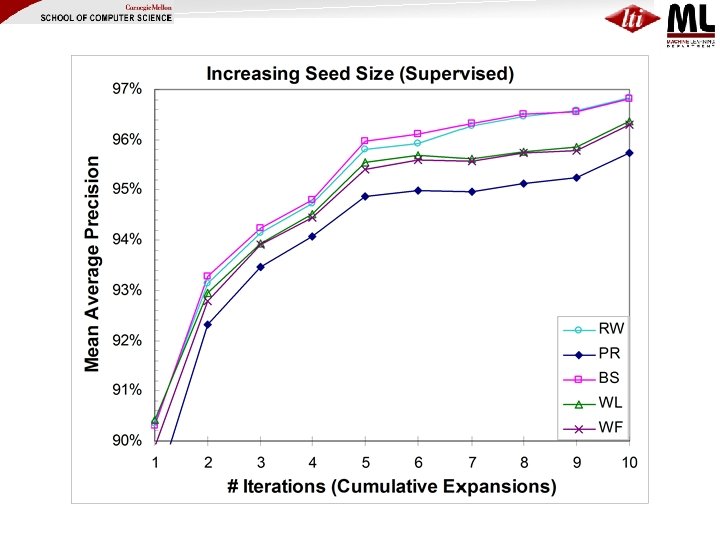
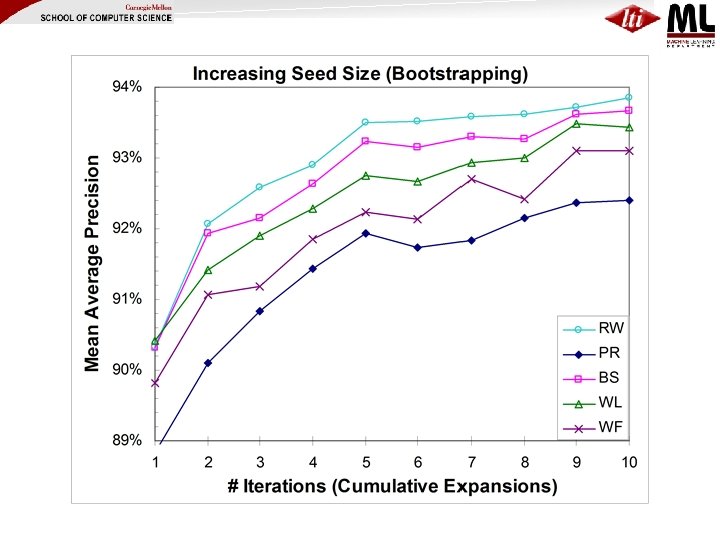
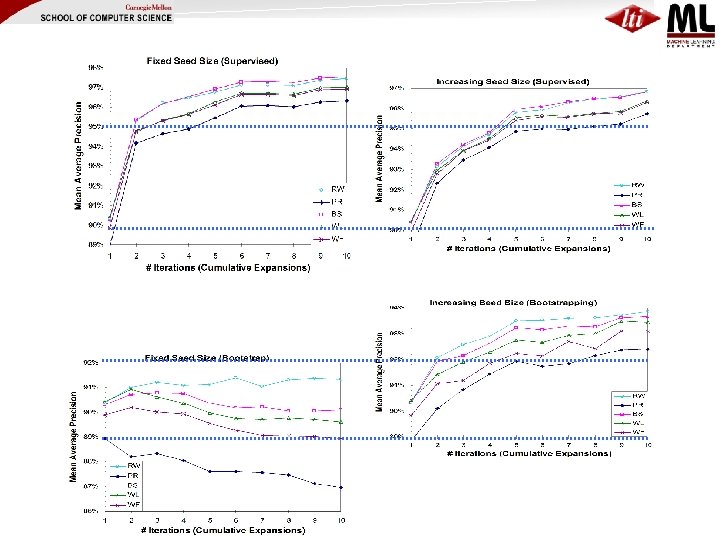
Proposed Solution: Iterative SEAL (i. SEAL) (Wang & Cohen, ICDM 2008) • Makes several calls to SEAL, each call… – Expands a couple of seeds – Aggregates statistics • Evaluate i. SEAL using… – Two iterative processes • Supervised vs. Unsupervised (Bootstrapping) – Two seeding strategies • Fixed Seed Size vs. Increasing Seed Size – Five ranking methods
 Initial Seeds • …Finally rank nodes by proximity to")
ISeal (Fixed Seed Size, Supervised) Initial Seeds • …Finally rank nodes by proximity to seeds in the full graph • Refinement (ISS): Increase size of seed set for each expansion over time: 2, 3, 4, 4, … • Variant (Bootstrap): use highconfidence extractions when seeds run out

Ranking Methods Random Graph Walk with Restart – H. Tong, C. Faloutsos, and J. -Y. Pan. Fast random walk with restart and its application. In ICDM, 2006. Page. Rank – L. Page, S. Brin, R. Motwani, and T. Winograd. The Page. Rank citation ranking: Bringing order to the web. 1998. Bayesian Sets (over flattened graph) – Z. Ghahramani and K. A. Heller. Bayesian sets. In NIPS, 2005. Wrapper Length – Weights each item based on the length of common contextual string of that item and the seeds Wrapper Frequency – Weights each item based on the number of wrappers that extract the item
; large differences when")
Little difference between ranking methods for supervised case (all seeds correct); large differences when bootstrapping Increasing seed size {2, 3, 4, 4, …} makes all ranking methods improve steadily in bootstrapping case

Outline • History – Open-domain IE by pattern-matching • The bootstrapping-with-noise problem – Bootstrapping as a graph walk • Open-domain IE as finding nodes “near” seeds on a graph – – – Set expansion - from a few clean seeds Iterative set expansion – from many noisy seeds Relational set expansion Multilingual set expansion Iterative set expansion – from a concept name alone
![Relational Set Expansion [Wang & Cohen, EMNLP 2009] • Seed examples are pairs: –](http://slidetodoc.com/presentation_image_h2/dce57f3e7fd0f6f28508719e29144dfd/image-43.jpg "Relational Set Expansion [Wang & Cohen, EMNLP 2009] • Seed examples are pairs: –")
Relational Set Expansion [Wang & Cohen, EMNLP 2009] • Seed examples are pairs: – E. g. , audi: : germany, acura: : japan, • Extension: find wrappers in which pairs of seeds occur – With specific left & right contexts – In specific order (audi before germany, …) – With specific string between them • Variant of trie-based algorithm

Results First iteration Tenth iteration

Outline • History – Open-domain IE by pattern-matching • The bootstrapping-with-noise problem – Bootstrapping as a graph walk • Open-domain IE as finding nodes “near” seeds on a graph – – – Set expansion - from a few clean seeds Iterative set expansion – from many noisy seeds Relational set expansion Multilingual set expansion Iterative set expansion – from a concept name alone

Multilingual Set Expansion

Multilingual Set Expansion • Basic idea: – – – – Expand in language 1 (English) with seeds s 1, s 2 to S 1 Expand in language 2 (Spanish) with seeds t 1, t 2 to T 1. Find first seed s 3 in S 1 that has a translation t 3 in T 1. Expand in language 1 (English) with seeds s 1, s 2, s 3 to S 2 Find first seed t 4 in T 1 that has a translation s 4 in S 2. Expand in language 2 (Sp. ) with seeds t 1, t 2, t 3 to T 2. Continue….

Multilingual Set Expansion • What’s needed: – Set expansion in two languages – A way to decide if s is a translation of t

Multilingual Set Expansion Submit s as a query and ask for results in language T. Find chunks in language T in the snippets that frequently co-occur with s • Bounded by change in character set (eg English to Chinese) or punctuation Rank chunks by combination of proximity & frequency Consider top 3 chunks t 1, t 2, t 3 as likely translations of s.

Multilingual Set Expansion

Multilingual Set Expansion

Outline • History – Open-domain IE by pattern-matching • The bootstrapping-with-noise problem – Bootstrapping as a graph walk • Open-domain IE as finding nodes “near” seeds on a graph – – – Set expansion - from a few clean seeds Iterative set expansion – from many noisy seeds Relational set expansion Multilingual set expansion Iterative set expansion – from a concept name alone
![ASIA: Automatic set instance acquisition [Wang & Cohen, ACL 2009] • Start with name](http://slidetodoc.com/presentation_image_h2/dce57f3e7fd0f6f28508719e29144dfd/image-53.jpg "ASIA: Automatic set instance acquisition [Wang & Cohen, ACL 2009] • Start with name")
ASIA: Automatic set instance acquisition [Wang & Cohen, ACL 2009] • Start with name of concept (e. g. , “NFL teams”) • Look for instances using (language-dependent) patterns: – “… for successful NFL teams (e. g. , Pittsburgh Steelers, New York Giants, …)” • Take most frequent answers as seeds • Run bootstrapping i. SEAL – with seed sizes 2, 3, 4, 4…. – and extended for noise-resistance: • wrappers should cover as many distinct seeds as possible (not all seeds) … • … subject to a limit on size • Modified trie method


Datasets with concept names

Experimental results Direct use of text patterns

Comparison to Kozareva, Riloff & Hovy (which uses concept name plus a single instance as seed)…no seed used.
")
Comparison to Pasca (using web search queries, CIKM 07)

Comparison to Word. Net + Nk • Snow et al, ACL 2005: series of experiments learning hyper/hyponyms – – Bootstrap from Wordnet examples Use dependency-parsed free text E. g. , added 30 k new instances with fairly high precision Many are concepts + named-entity instances: • Experiments with ASIA on concepts from Wordnet shows a fairly common problem: – E. g. , “movies” gives as “instances”: “comedy”, “action/adventure”, “family”, “drama”, …. – I. e. , ASIA finds a lower level in a hierarchy, maybe not the one you want

Comparison to Word. Net + Nk • Filter: a simulated sanity check: – Consider only concepts expanded in Wordnet + 30 k that seem to have named-entities as instances and have at least instances – Run ASIA on each concept – Discard result if less than 50% of the Wordnet instances are in ASIA’s output

Summary: • Some are good • Some of Snow’s concepts are low-precision relative to ASIA (4. 7% 100%) • For the rest ASIA has 2 x 100 x the coverage (in number of instances)

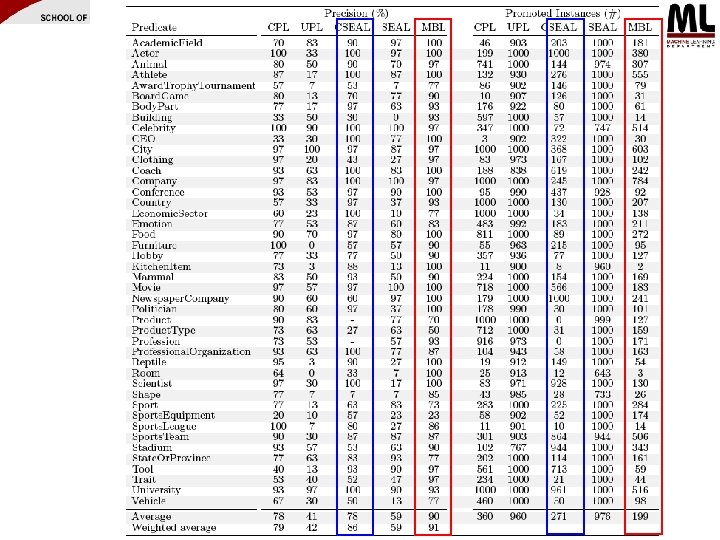
Two More Systems to Compare to • Van Durme & Pasca, 2008 • Talukdar et al, 2008 • ASIA – Requires an English part-of-speech tagger. – Analyzed 100 million cached Web documents in English (for many classes). – Requires 5 seed instances as input (for each class). – Utilizes output from Van Durme’s system and 154 million tables from the Web. Tables database (for many classes). – – – Does not require any part-of-speech tagger (nearly language-independent). Supports multiple languages such as English, Chinese, and Japanese. Analyzes around 200~400 Web documents (for each class). Requires only the class name as input. Given a class name, extraction usually finishes within a minute (including network latency of fetching web pages).

• Precisions of Talukdar and Van Durme’s systems were obtained from Figure 2 in Talukdar et al, 2008.

Top 10 Instances from ASIA

Joint work with Tom Mitchell, Weam Abu. Zaki, Justin Betteridge, Andrew Carlson, Estevam R. Hruschka Jr. , Bryan Kisiel, Burr Settles Learn a large number of concepts at once person team. Plays. Sport(t, s ) plays. For. Team(a, t) sport athlete coach NP 1 team plays. Sport(a, s) coaches. Team(c, t) NP 2 Krzyzewski coaches the Blue Devils.

Coupled learning of text and HTML patterns evidence integration CBL SEAL Free-text extraction patterns HTML extraction patterns Ontology and populated KB the Web

Summary/Conclusions • Open-domain IE as finding nodes “near” seeds on a graph NIPS “…at NIPS, AISTATS, KDD and other learning conferences…” AISTATS SNOWBIRD For skiiers, NIPS, SNOWBIRD, … and…” SIGIR KDD … “on PC of KDD, SIGIR, … and…” “… AISTATS, KDD, …” • RWR as robust proximity measure • Character tries as flexible pattern language • high-coverage • modifiable to handle expectations of noise

Summary/Conclusions • Open-domain IE as finding nodes “near” seeds on a graph: – Graph built on-the-fly with web queries • A good graph matters! • A big graph matters! – character-level tries >> HTML heuristics – Rank the whole graph • Don’t confuse iteratively building the graph with ranking! – Off-the-shelf distance metrics work • Differences are minimal for clean seeds • Much bigger differences with noisy seeds • Bootstrapping (especially from free-text patterns) is noisy

Thanks to • DARPA PAL program – Cohen, Wang • Google Research Grant program – Wang Sponsored links: http: //boowa. com (Richard’s demo)
- Slides: 71