GPU Architecture Overview Patrick Cozzi University of Pennsylvania
















.")
 bottlenecked at 1 instruction / clock Superscalar –")



 extraction ¨ Superscalar ¨ Out-of-order n")
![Vectors Motivation for (int i = 0; i < N; i++) A[i] = B[i]](https://slidetodoc.com/presentation_image_h/281a4bbd7e4cc3e1f6af48d3175e29d4/image-23.jpg "Vectors Motivation for (int i = 0; i < N; i++) A[i] = B[i]")
 ¨ Let’s make the execution")










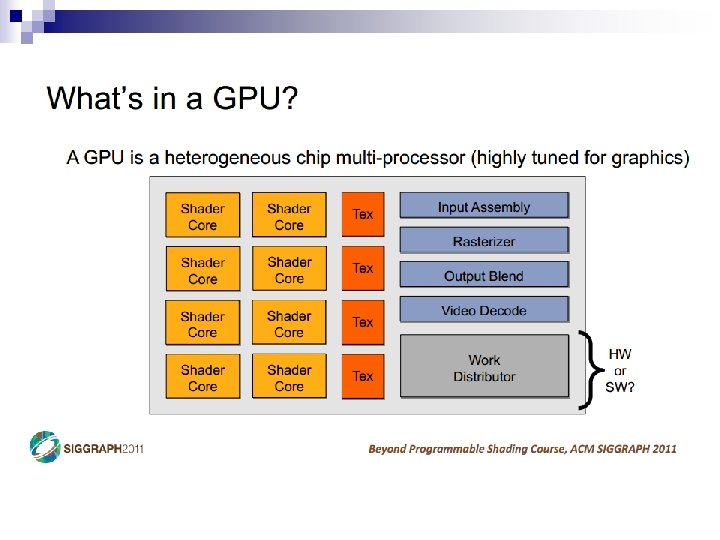


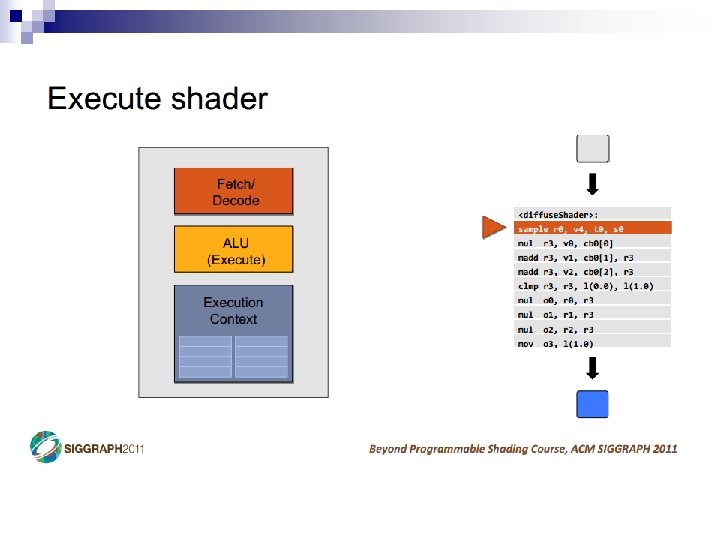
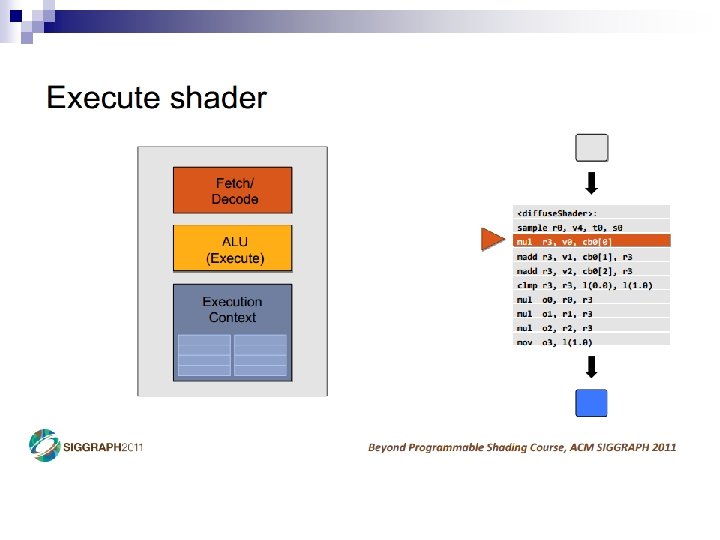




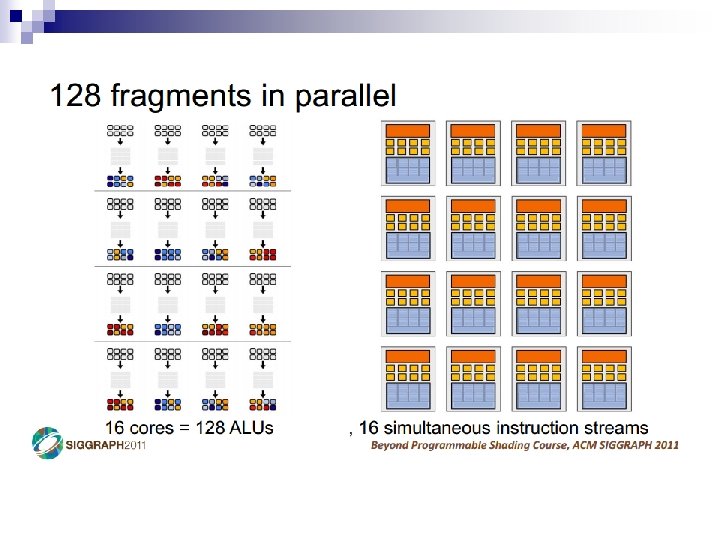
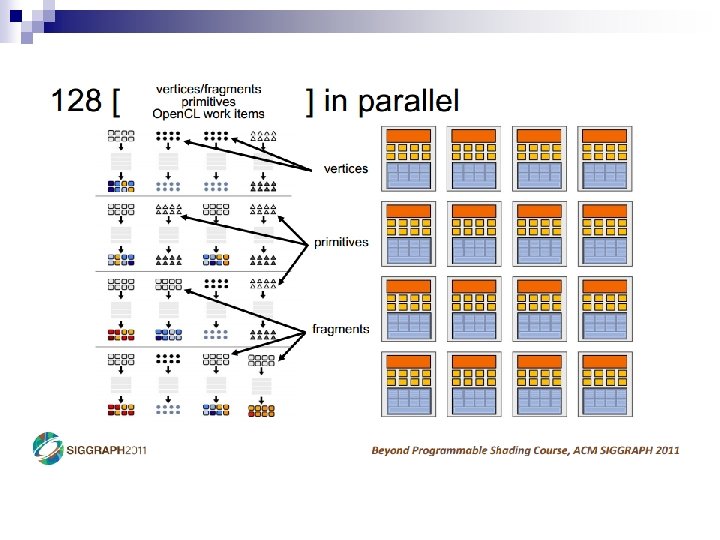






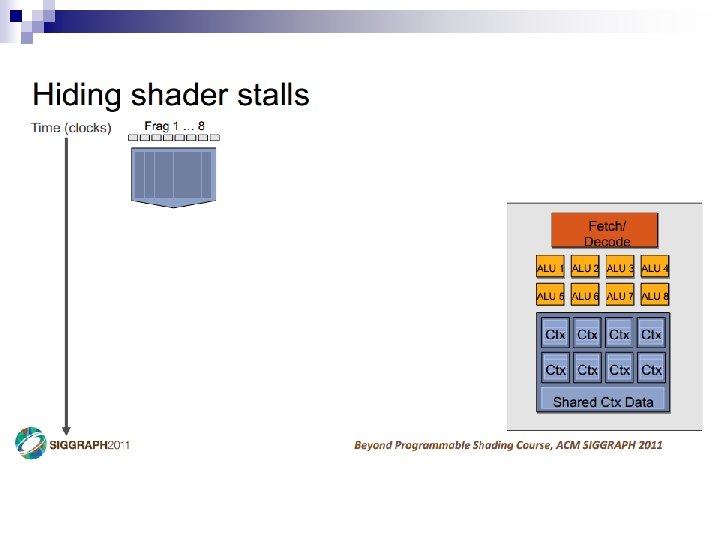
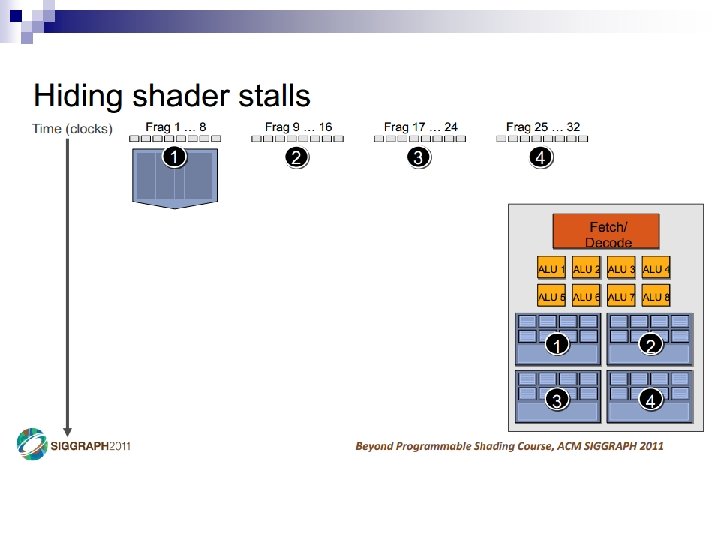
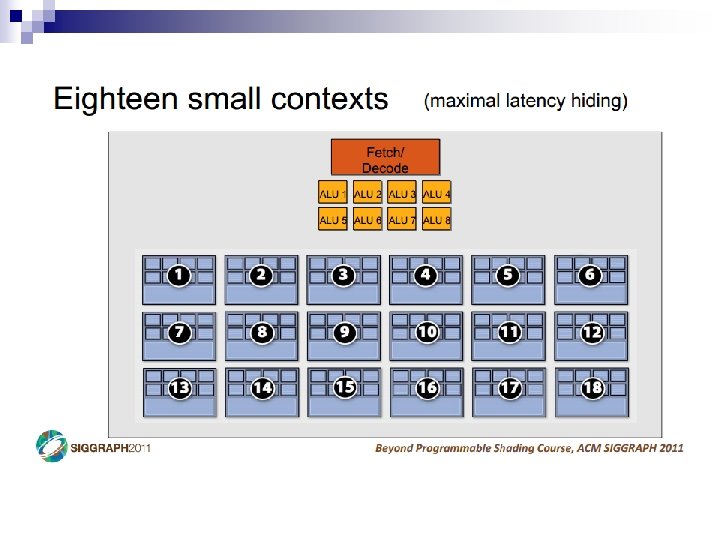
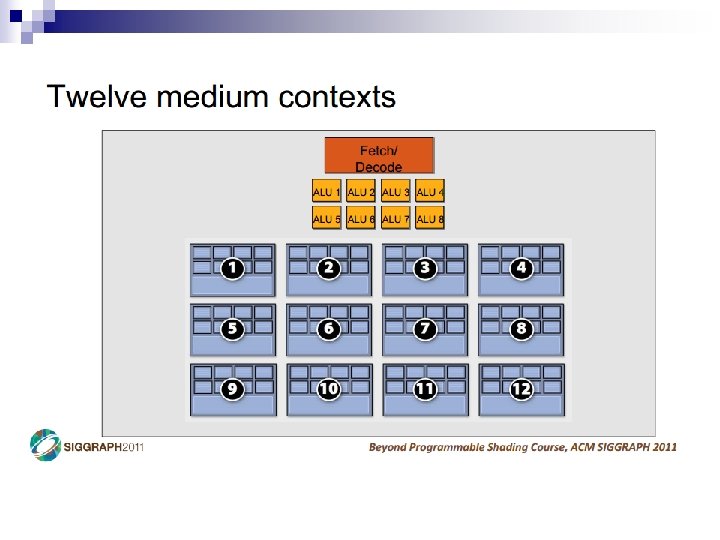
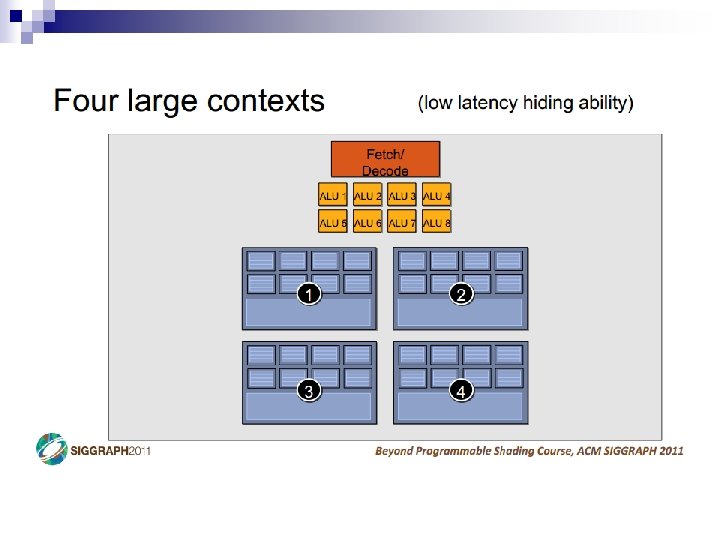




- Slides: 69
GPU Architecture Overview Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012
Announcements Project 0 due Monday 09/17 n Karl’s office hours n ¨ Tuesday, 4: 30 -6 pm ¨ Friday, 2 -5 pm
Course Overview Follow-Up Read before or after lecture? n Project vs. final project n Closed vs. open source n Feedback vs. grades n Guest lectures n
Acknowledgements CPU slides – Varun Sampath, NVIDIA n GPU slides n ¨ Kayvon Fatahalian, CMU ¨ Mike Houston, AMD
CPU and GPU Trends FLOPS – FLoating-point OPerations per Second n GFLOPS - One billion (109) FLOPS n TFLOPS – 1, 000 GFLOPS n
CPU and GPU Trends Chart from: http: //proteneer. com/blog/? p=263
CPU and GPU Trends n Compute ¨ Intel Core i 7 – 4 cores – 100 GFLOP ¨ NVIDIA GTX 280 – 240 cores – 1 TFLOP n Memory Bandwidth ¨ System Memory – 60 GB/s ¨ NVIDIA GT 200 – 150 GB/s n Install Base ¨ Over 200 million NVIDIA G 80 s shipped
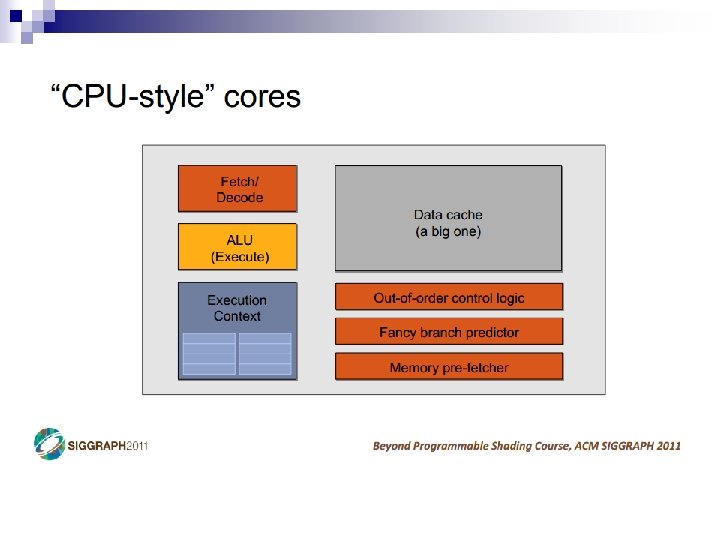
CPU Review n What are the major components in a CPU die?
CPU Review • Desktop Applications – Lightly threaded – Lots of branches – Lots of memory accesses Profiled with psrun on ENIAC Slide from Varun Sampath
A Simple CPU Core + 4 PC I$ Register File s 1 s 2 d D$ control Fetch Decode Execute Memory Writeback Image: Penn CIS 501
Pipelining + 4 PC Insn Mem Tinsn-mem Register File Data Mem s 1 s 2 d Tregfile TALU Tdata-mem Tregfile Tsinglecycle Image: Penn CIS 501
Branches A Register File O s 1 s 2 d F/D B S X D/X IR ? ? ? nop ? ? ? O B X/M IR a Data Mem d D M/W IR IR jeq loop Image: Penn CIS 501
Branch Prediction + Modern predictors > 90% accuracy o Raise performance and energy efficiency (why? ) – Area increase – Potential fetch stage latency increase
Memory Hierarchy n n Memory: the larger it gets, the slower it gets Rough numbers: Latency Bandwidth Size SRAM (L 1, L 2, L 3) DRAM (memory) 1 -2 ns 200 GBps 1 -20 MB 70 ns 20 GBps 1 -20 GB Flash (disk) 70 -90µs 200 MBps 100 -1000 GB HDD (disk) 10 ms 1 -150 MBps 500 -3000 GB
Caching Keep data you need close n Exploit: n ¨ Temporal n Chunk just used likely to be used again soon ¨ Spatial n locality Next chunk to use is likely close to previous
Cache Hierarchy I$ n Hardware-managed ¨ L 1 Instruction/Data caches ¨ L 2 unified cache ¨ L 3 unified cache n Software-managed ¨ Main memory D$ L 2 L a r g e r L 3 Main Memory ¨ Disk (not to scale) F a s t e r
Intel Core i 7 3960 X – 15 MB L 3 (25% of die). 4 -channel Memory Controller, 51. 2 GB/s total Source: www. lostcircuits. com
Improving IPC n n IPC (instructions/cycle) bottlenecked at 1 instruction / clock Superscalar – increase pipeline width Image: Penn CIS 371
Scheduling n Consider instructions: xor r 1, r 2 add r 3, r 4 sub r 5, r 2 addi r 3, 1 n n n -> -> r 3 r 4 r 3 r 1 xor and add are dependent (Read-After. Write, RAW) sub and addi are dependent (RAW) xor and sub are not (Write-After-Write, WAW)
Register Renaming n How about this instead: xor p 1, p 2 add p 6, p 4 sub p 5, p 2 addi p 8, 1 n -> -> p 6 p 7 p 8 p 9 xor and sub can now execute in parallel
Out-of-Order Execution n Reordering instructions to maximize throughput Fetch Decode Rename Dispatch Issue Register-Read Execute Memory Writeback Commit Reorder Buffer (ROB) ¨ Keeps n n track of status for in-flight instructions Physical Register File (PRF) Issue Queue/Scheduler ¨ Chooses next instruction(s) to execute
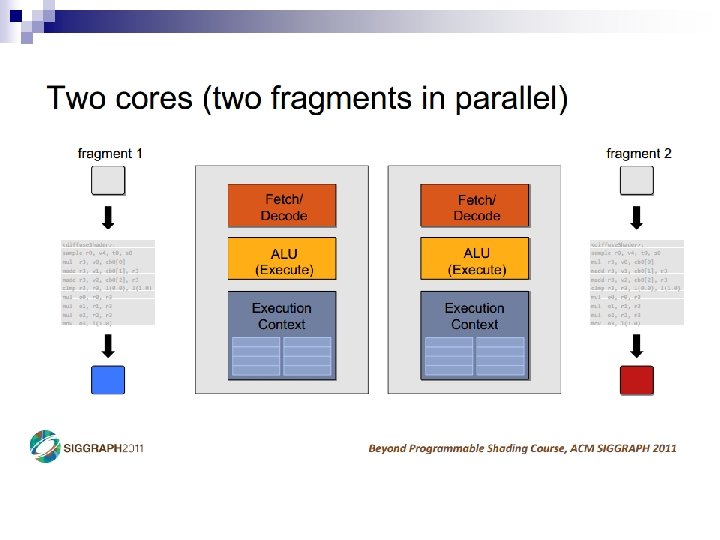
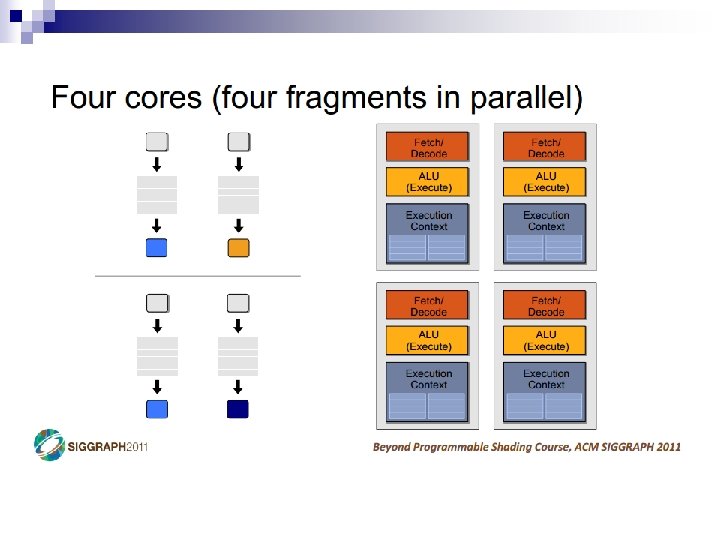
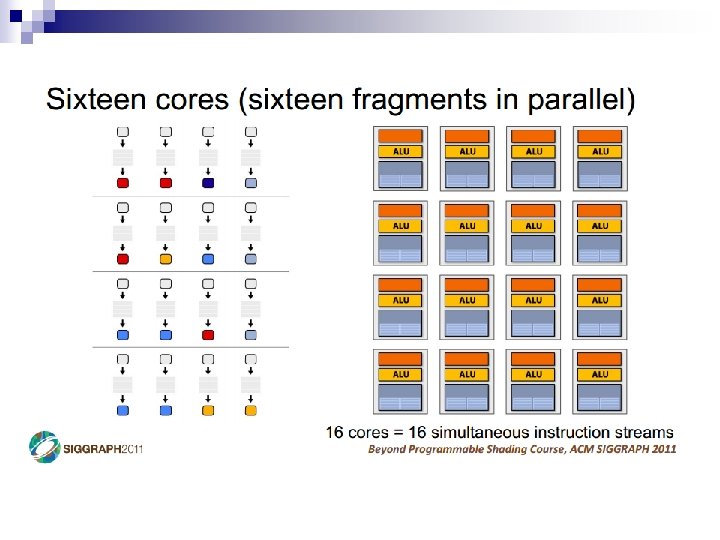
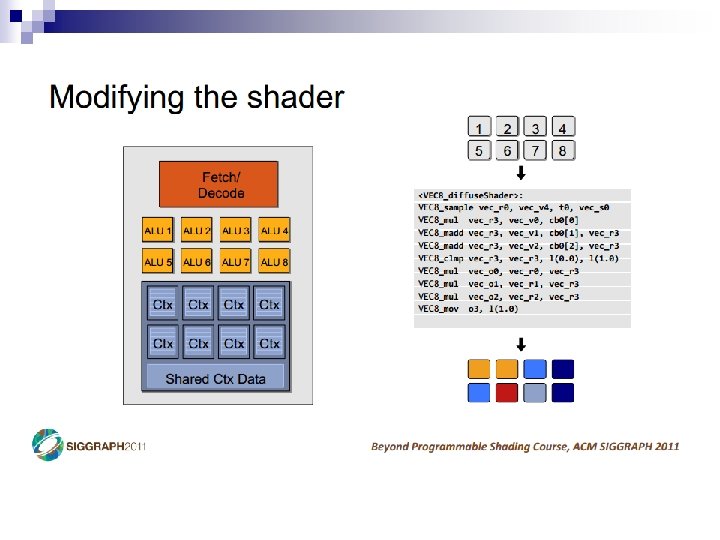
Parallelism in the CPU n Covered Instruction-Level (ILP) extraction ¨ Superscalar ¨ Out-of-order n Data-Level Parallelism (DLP) ¨ Vectors n Thread-Level Parallelism (TLP) ¨ Simultaneous ¨ Multicore Multithreading (SMT)
Vectors Motivation for (int i = 0; i < N; i++) A[i] = B[i] + C[i];
CPU Data-level Parallelism n Single Instruction Multiple Data (SIMD) ¨ Let’s make the execution unit (ALU) really wide make the registers really wide too for (int i = 0; i < N; i+= 4) { // in parallel A[i] = B[i] + C[i]; A[i+1] = B[i+1] + C[i+1]; A[i+2] = B[i+2] + C[i+2]; A[i+3] = B[i+3] + C[i+3]; }
Vector Operations in x 86 n SSE 2 ¨ 4 -wide packed float and packed integer instructions ¨ Intel Pentium 4 onwards ¨ AMD Athlon 64 onwards n AVX ¨ 8 -wide packed float and packed integer instructions ¨ Intel Sandy Bridge ¨ AMD Bulldozer
Thread-Level Parallelism n Thread Composition ¨ Instruction streams ¨ Private PC, registers, stack ¨ Shared globals, heap Created and destroyed by programmer n Scheduled by programmer or by OS n
Simultaneous Multithreading Instructions can be issued from multiple threads n Requires partitioning of ROB, other buffers + Minimal hardware duplication + More scheduling freedom for Oo. O – Cache and execution resource contention can reduce single-threaded performance n
Multicore Replicate full pipeline n Sandy Bridge-E: 6 cores + Full cores, no resource sharing other than last-level cache + Easier way to take advantage of Moore’s Law – Utilization n
CPU Conclusions n n n CPU optimized for sequential programming ¨ Pipelines, branch prediction, superscalar, Oo. O ¨ Reduce execution time with high clock speeds and high utilization Slow memory is a constant problem Parallelism ¨ Sandy Bridge-E great for 6 -12 active threads ¨ How about 12, 000?
How did this happen? http: //proteneer. com/blog/? p=263
Graphics Workloads n Triangles/vertices and pixels/fragments Right image from http: //http. developer. nvidia. com/GPUGems 3/gpugems 3_ch 14. html
Early 90 s – Pre GPU Slide from http: //s 09. idav. ucdavis. edu/talks/01 -BPS-SIGGRAPH 09 -mhouston. pdf
Why GPUs? n Graphics workloads are embarrassingly parallel ¨ Data-parallel ¨ Pipeline-parallel CPU and GPU execute in parallel n Hardware: texture filtering, rasterization, etc. n
Data Parallel n Beyond Graphics ¨ Cloth simulation ¨ Particle system ¨ Matrix multiply Image from: https: //plus. google. com/u/0/photos/100838748547881402137/albums/5407605084626995217/5581900335460078306
Reminders n Piazza ¨ Signup: n https: //piazza. com/upenn/fall 2012/cis 565/ Git. Hub ¨ Create an account: https: //github. com/signup/free ¨ Change it to an edu account: https: //github. com/edu ¨ Join our organization: https: //github. com/CIS 565 -Fall-2012 n No class Wednesday, 09/12