GPGPU MultiGPUs GPU General Purpose CPU GPU GPU
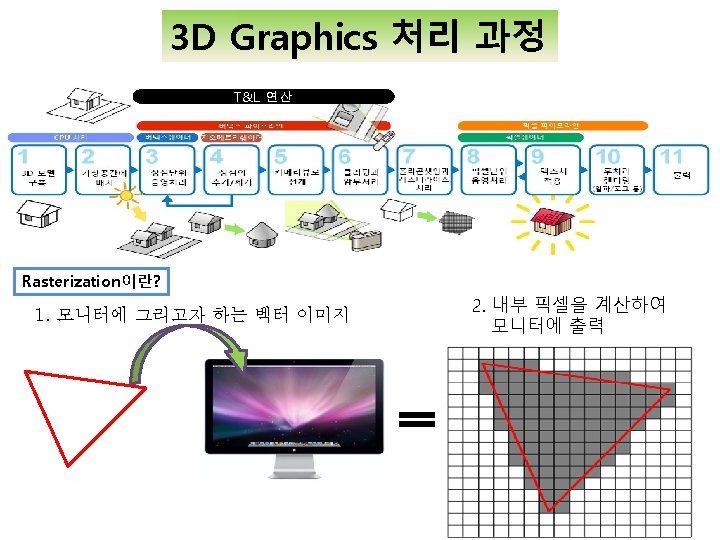
으로 활용하도록 하기 위해")
{ for(j=0; j<512; j++){ int result_a_up")
 (ms) 그래픽카드 수에 따른 실행시간 비교 (ms) 0. 18 0. 15986 C")
 블록당 차원 수에 따른 실행시간 비교 (ms) 각 블록 크기에 따른")

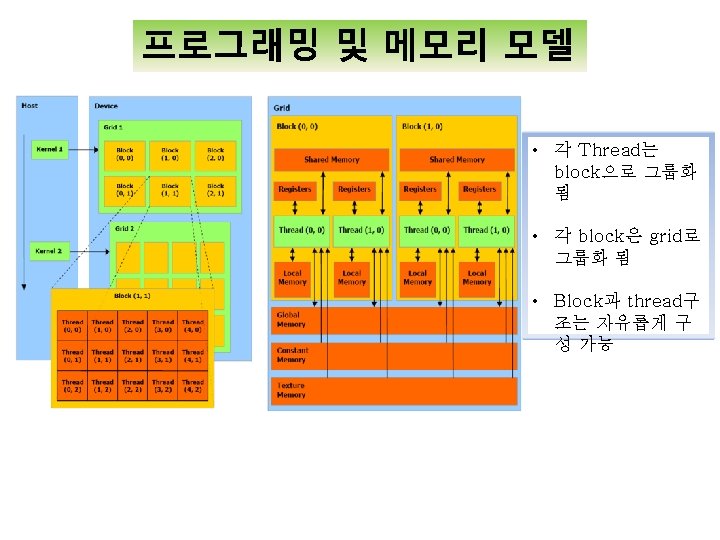
- Slides: 8
GPGPU & Multi-GPUs 기존의 그래픽 처리에만 사용되던 GPU를 범용 목적(General Purpose)으로 활용하도록 하기 위해 CPU에서 처리하던 연산 일부 를 GPU가 맡아서 병렬로 처리하는 기술 GPU 서버 CPU 데스크톱 CPU Intel Xeon x 5690 3. 46 Ghz * 2 ea CPU Intel Core 2 Duo E 8400 3. 00 GHz Memory 144 GB Memory 4 GB GPU NVIDIA Geforce GTX 580 * 7 EA GPU NVIDIA Geforce 9800 GT OS Cent. OS 5. 8 OS Windows 7
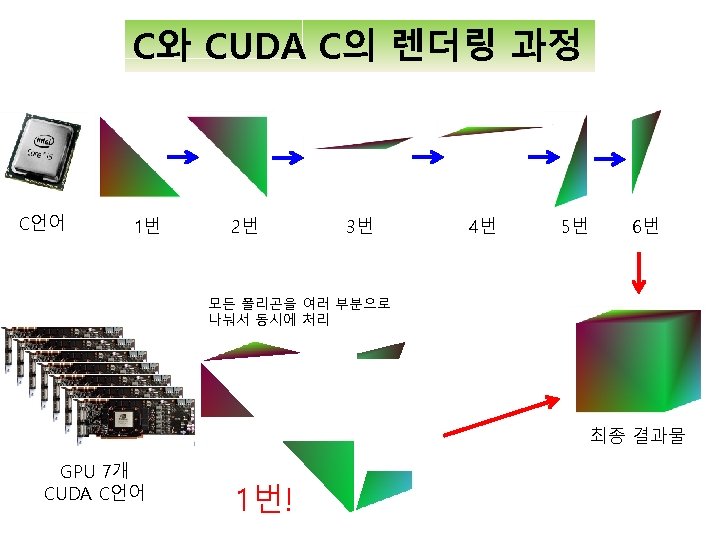
C에서 CUDA C로 변환 C 사라짐 for(i=0; i<512; i++){ for(j=0; j<512; j++){ int result_a_up = ((MEM[11]-MEM[1])*(i-MEM[0]))-((MEM[10]-MEM[0])*(j-MEM[1])); int result_a_down = ((MEM[11]-MEM[1])*(MEM[5]-MEM[0]))-((MEM[6]-MEM[1])*(MEM[10]-MEM[0])); int result_b_up = ((MEM[6] -MEM[1])*(MEM[0]-i))-((MEM[5] -MEM[0])*(MEM[1]-j)); int result_b_down = ((MEM[11]-MEM[1])*(MEM[5]-MEM[0]))-((MEM[6]-MEM[1])*(MEM[10]-MEM[0])); result_a = float(result_a_up) / float(result_a_down); result_b = float(result_b_up) / float(result_b_down); } } if( (0 <= result_a && result_a <=1) && ((0 <= result_b && result_b <= 1)) && ((0 <= (result_a+result_b) && (result_a+result_b) <= 1)) ){ IMAGE[i][j][0] = (char)(float(MEM[2]) + (float(MEM[7])-float(MEM[2]))*a + (float(MEM[12])-float(MEM[2]))*b); IMAGE[i][j][1] = (char)(float(MEM[3]) + (float(MEM[8])-float(MEM[3]))*a + (float(MEM[13])-float(MEM[3]))*b); IMAGE[i][j][2] = (char)(float(MEM[4]) + (float(MEM[9])-float(MEM[4]))*a + (float(MEM[14])-float(MEM[4]))*b); } CUDA C int Col = block. Idx. y*block. Dim. y+ thread. Idx. y; int Row = block. Idx. x*block. Dim. x+ thread. Idx. x; int tid_in_grid = tid_in_block + threads_per_block * bid_in_grid; int result_a_up = (M[11]-M[1])*(Row-M[0]) - (M[10]-M[0])*(Col-M[1]); int result_b_up = (M[6] -M[1])*(M[0]-Row) - (M[5] -M[0])*(M[1]-Col); int result_down = (M[11]-M[1])*(M[5]-M[0]) - (M[6]-M[1])*(M[10]-M[0]); result_a = (float)result_a_up / (float)result_down; result_b = (float)result_b_up / (float)result_down; if((0 <= result_a && result_a <=1) && (0 <= result_b && result_b <= 1) && (0 <= (result_a+result_b) && (result_a+result_b) <= 1)){ IMAGEin[tid_in_grid] = (M[2] + (M[7]-M[2])*result_a + (M[12]-M[2])*result_b); IMAGEin[tid_in_grid + WIDTH*HEIGHTs] = (M[3] + (M[8]-M[3])*result_a + (M[13]-M[3])*result_b); IMAGEin[tid_in_grid + WIDTH*HEIGHTs*2] = (M[4] + (M[9]-M[4])*result_a + (M[14]-M[4])*result_b); IMAGEin[tid_in_grid + WIDTH*HEIGHTs*3] = 0; }
실험 결과(Multi-GPUs) (ms) 그래픽카드 수에 따른 실행시간 비교 (ms) 0. 18 0. 15986 C vs CUDA C 900. 000 0. 16 0. 14 700. 000 0. 12 600. 000 0. 07854 0. 1 0. 05743 0. 08 0. 06 Open. CL 0. 04555 0. 04 0. 03950 0. 03389 100. 000 3 4 5 6 7 에너지 소비 에너지 효율 6. 0000 4. 8400 4. 7847 4. 0362 4. 0000 47. 6 0. 15986 0. 000 Devices (m. J) CPU-D 300. 000 0. 03024 0 2 CUDA-D 400. 000 200. 000 1 CUDA-S 500. 000 0. 02 5. 0000 800. 85000 800. 000 5. 0170 4. 8288 2 4. 9374 1. 20 4. 5847 1. 06 1. 00 1. 01 1 3. 0000 0. 96 1. 00 0. 98 LOAD 2. 0000 LOAD 1 1. 0000 0. 0000 1 2 3 4 Device 5 6 7 0 1 2 3 4 Devices 5 6 7
실험 결과(Block 구성) 블록당 차원 수에 따른 실행시간 비교 (ms) 각 블록 크기에 따른 실행시간 비교 (ms) 2 12 10. 8194 10 1. 5 1. 0760 1 1. 0740 1. 0750 1. 0740 1. 0700 8 1. 0760 1. 0740 1. 0680 GPU 1. 0750 6 4 0. 5 2 0 1 x 256 2 x 128 4 x 64 8 x 32 16 x 16 32 x 8 1 4 450 400 350 1. 0704 16 64 10. 11 10 335. 4014 GPU 250 CPU 103. 7322 100 33. 1824 35. 1416 33. 1204 4 16 Block Size 64 256 1024 10. 13 9. 54 GPU 2 CPU 3. 23 1. 00 0 0 1 1024 6 4 45. 9792 50 256 7. 29 8 300 150 1. 1336 에너지 효율 12 459. 1210 200 1. 0684 Block Size 에너지 소비 500 1. 4832 0 64 x 4 128 x 2 256 x 1 Block Dimension (m. J) GPU 3. 3462 1 0. 73 4 16 64 Block Size 256 1024