Gene analysis Nucleotide BLAST http blast ncbi nlm

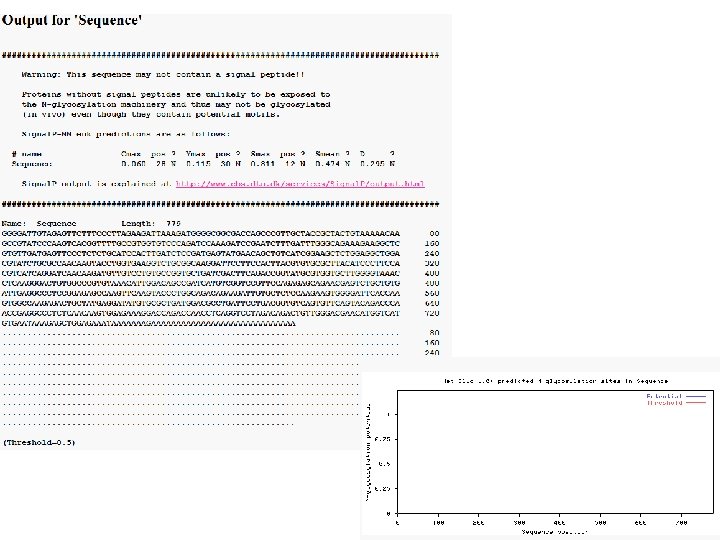
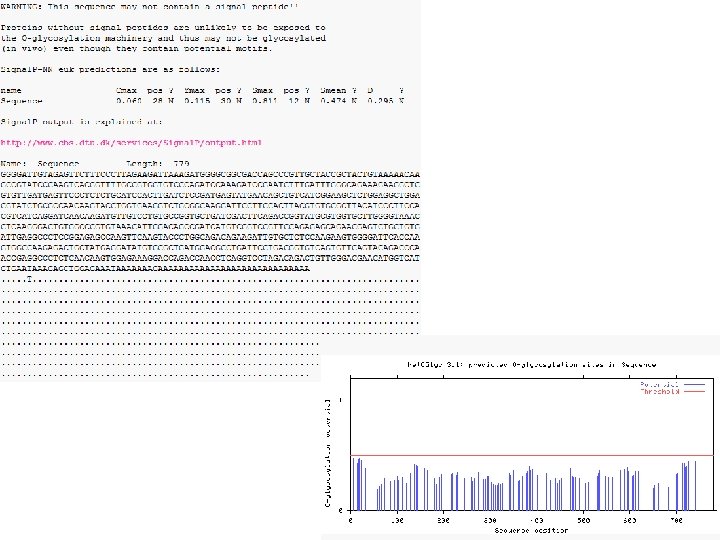
Gene analysis Nucleotide BLAST : http: //blast. ncbi. nlm. nih. gov/Blast. cgi - 유전자 염기서열을 가지고 데이터베이스에 등록되어 있는 서열과 비교하여 유사한 서열을 찾아줌 Protein BLAST : http: //blast. ncbi. nlm. nih. gov/Blast. cgi - 아미노산서열을 가지고 데이터베이스에 등록되어 있는 서열과 비교하여 domain 및 유사 서열 찾아줌 Blastx : http: //blast. ncbi. nlm. nih. gov/Blast. cgi - 유전자 염기서열을 아미노산 서열로 바꿔 유사 아미노산 서열을 찾아줌 Dnassist version 2. 2 program - 유전자 혹은 아미노산 서열 비교, ORF 찾을때, 제한효소 site 확인시, 물리적 특성 등 Clustal. W multiple alignment 1. 8 program - 유전자 혹은 아미노산 서열 비교 MEGA 3. 1 - 계통도 작성시 사용 Signal. P program : http: //www. cbs. dtu. dk/services/Signal. P/ - 신호서열을 찾아줌 Lipo. P 1. 0 server : http: //www. cbs. dtu. dk/services/Lipo. P/ - lipoprotein site 찾아줌 (그람 음성균만 해당) Motif scan prediction program : http: //myhits. isb-sib. ch/cgi-bin/motif_scan - 모티브들을 찾아줌 TMHMM server v. 2. 0 : http: //www. cbs. dtu. dk/services/TMHMM/ - transmembrane (막에 붙는 단백질) site 찾아줌 Net. NGlyc 1. 0 server : http: //www. cbs. dtu. dk/services/Net. NGlyc/ - N glycosilation site 찾을 때 사용 (진핵세포만 해당) Net. OGlyc 3. 1 server : http: //www. cbs. dtu. dk/services/Net. OGlyc/ - O glycosilation site 찾을 때 사용 (진핵세포만 해당) Oligo Analyzer 3. 1 : http: //eu. idtdna. com/analyzer/Applications/Oligo. Analyzer/ - primer 제작시 Tm, GC% 등 설정

AG 17 agarase - ORF ATGAAGATTAAATTTTTATCTGCAGCAATCGCTGCAAGCTTAGCATTGCCATTAAGTGCTGCTACCTTAGTCACCTCTTTTGAGGAAGCCGACTACA GCAGCTCTGAAAACAATACTGAATTCTTGGAAGTGTCTGGAGATGCCACTTCTGAAGTTTCAACTGAACAAGCTACCGATGGTAATCCATTAA AGCGTCTTTTGACGCGGCTTTCAAACCAATGGTTGTTTGGAACTGGGGAAGTTGGAACTGGGGCGCTGAAGATGTCAGTAGATGTTGTTAA CCCTAACGACACTGACGTCACCTTTGCTATTAAGCTAATTGATAGTGATATTCTTCCTGATTGGGTAGATGAGTCTCAAACCTCATTGGACTACTTTA CGGTTTCAGCTAATACCACGCAGACCTTTAGCTTTAACTTAAATGGCGGCAACGAGTTCCAAACTCATGGCGAAAACTTTAGTAAAGATAAAGTTAT CGGTGTGCAGTTCATGCTCTCTGAAAACGATCCTCAAGTGTTGTACTTTGACAACATTATGGTTGATGGCGAAACAGTCACTCCGCCACCAAGTGA TGGTGCAGTGAATACACAAACCGCGCCTGTAGCCACCTTAGCGCAAATCGAAGACTTTGAAACCATTCCAGATTACGACCTGATGGTGGGGT AAACGTTTCAACTACTACTGAGATTGTGACTAAAGGCGCTGCAGCAATGGCTGCCGAGTTTACTGCAGGTTGGAACGGTTTAGTGTTTGCAGGTAC TTGGAATTGGGCTGAACTAGGTGAACACACCGCAGTTGCCGTTGACGTTTCAAATACTAGCGATAGCAATATCTGGTTGTACTCACGTATCGAAGA TGTAAATAGCCAAGGCGAAACAGCGACTCGCGGCGTATTGGTTAAAGCTGGCGAATCGAAAACCATCTACACCAGCTTAAATGACAACCCTTCATT GCTTACTCAAGATGAGCGCGTGTCAGCTTTAGGTTTACGTGATATTCCAGCTGACCCAATGAGCGCTCAAAATGGCTGGGGTGATTTTGTTGCTTT AGACAAATCTCAAATTACCGCTATTCGTTACTTCATTGGCGAATTAGCCAGCGGTGAGACTAGCCAAACACTTGTGTTTGATAACATGCGTGTGATT AAAGACCTTAACCACGAATCAGCCTATGCAGAAATGACTGATGCTATGGGGCAAAACAACTTAGTCACTTATGCAGGTAAAGTTGCCAGCAAAGAA GAGTTAGCTAAGTGATCCGGAAATGGCTGTTTTGGGTGAGTTAACCAATCGCAATATGTACGGTGGTAACCCAGATTCGTCGCCAACTACA GACTGTGTGCTCGCTACGCCTCGTTTAACGCTTGTAAAGACGCTGATGGTAACTGGCAATTGGTAGACCCTGCTGGTAATGCGTTCTTCTCA ACCGGTGTTGATAACATTCGTTTGCAAGATACTTACACCATGACCGGCGTGTCGAGTGACGCCGAATCTGAGTCTGCACTTCGCCAGTCAATGTTT ACAGAAATTCCAAGTGATTATGTAAATGAAAACTATGGCCCTGTGCATAGTGGACCTGTTTCTCAAGGCCAAGCTGTAAGTTTTTACGCTAATAACTT AATTACCCGCCACGCTAGCGAAGACGTATGGCGAGACATTACTGTTAAGCGCATGAAAGACTGGGGCTTTAACACCTTAGGTAACTGGACCGATC CAGCGTTGTATGCAAACGGTGACGTTCCTTACGTGGCAAATGGTCAACCTCTGGTGCCGATCGTCTTCCCGTTAAACAAATTGGCAGCGGC TACTGGGGACCACTTCCTGATCCGTGGGATGCTAACTTTGCTACCAATGCCGCCACAATGGCTGCAGAGATCAAAGCTCAGGTTGAAGGCAACGA AGAGTACTTAGTGGGTATTTTTGTTGATAACGAAATGAGCTGGGGCAATGTCACTGATGTTGAAGGCTCTCGTTATGCGCAAACGCTAGCAGTGTT CAATACCGACGGCACTGATGCAACAACTAGCCCTGCTAAAAATAGCTTTATTTGGTTCTTAGAAAACCAGCGTTATACCGGTGGCATTGCTGACCTA AACGCAGCCTGGGGAACCGATTATGCGTCTTGGGATGCGCCCAGCGCAAGAGTTAGCTTATGTGGCATGGAAGCTGATATGCAGT TCCTTGGCAGTTTGCGTTCCAATACTTCAACACCGTAAACACGGCATTAAAAGCTGAGTTACCAAACCACTTGTACTTGGGCTCTCGCTTTGC AGATTGGGGACGTACTCCTGATGTAGTAAGTGCTGCTGCGGCTGTTGTTGATGAGTTACAACATCTACAAAGACAGTATTGCAGCTGCCGA TTGGGATGCTGATGCCTTAAATCAAATTGAAGCCATTGATAAGCCAGTAATTATTGGTGAGTTCCACTTCGGTGCGCTTGATAGCGGTTCGTTTGCA GAAGGTGTAGTAAATGCCACTTCGCAACAAGATCGTGCAGACAAAATGGTTAGCTTCTACGAATCAGTAAATGCCCATAAAAACTTTGTAGGTGCG CATTGGTTCCAATACATCGATTCACCATTAACGGGTCGTGCATGGGATGGCGAGAACTACAACGTTGGTTTTGTTAGCAATACTGACACGCCATATA CATTGATGACAGATGCTGCGCGTGAGTTTAACTGTGGTATGTACGGCACTGCTCTAGCTTAAGCAATGCTACTGAAGCTGCTTCGAGAGCCG GTGAGTTGTATACCGGTACCAATATTGGTGTTAGCCACTCTGGCCCAGAAGCGCCAGATCCAGGTGAGCCAGTTGATCCTCCAATTGATCCGCCA ACACCACCAACAGGTGGCGTAACTGGCGGTAGCGCAGGTTATCGCTACTAGGTTTGGCCGGCGTATTTTTACTAAGACGTCGTAA AGTGTAA
 ATGGTTGTTTGGAACTGGGGAAGTTGGAACTGGGGCGCTGAAGATGTCAGTAGATGTTGTTAACCCTAACGACACTGACGTCACCT TTGCTATTAAGCTAATTGATAGTGATATTCTTCCTGATTGGGTAGATGAGTCTCAAACCTCATTGGACTACTTTACGGTTTCAGCTAATACCA CGCAGACCTTTAGCTTTAACTTAAATGGCGGCAACGAGTTCCAAACTCATGGCGAAAACTTTAGTAAAGATAAAGTTATCGGTGTGCAGTTC ATGCTCTCTGAAAACGATCCTCAAGTGTTGTACTTTGACAACATTATGGTTGATGGCGAAACAGTCACTCCGCCACCAAGTGATGGTGCAG TGAATACACAAACCGCGCCTGTAGCCACCTTAGCGCAAATCGAAGACTTTGAAACCATTCCAGATTACGACCTGATGGTGGGGTAAA CGTTTCAACTACTACTGAGATTGTGACTAAAGGCGCTGCAGCAATGGCTGCCGAGTTTACTGCAGGTTGGAACGGTTTAGTGTTTGCAGGT ACTTGGAATTGGGCTGAACTAGGTGAACACACCGCAGTTGCCGTTGACGTTTCAAATACTAGCGATAGCAATATCTGGTTGTACTCACGTAT CGAAGATGTAAATAGCCAAGGCGAAACAGCGACTCGCGGCGTATTGGTTAAAGCTGGCGAATCGAAAACCATCTACACCAGCTTAAATGA CAACCCTTCATTGCTTACTCAAGATGAGCGCGTGTCAGCTTTAGGTTTACGTGATATTCCAGCTGACCCAATGAGCGCTCAAAATGGCTGG")
AG 17 agarase – ORF(찾기) ATGGTTGTTTGGAACTGGGGAAGTTGGAACTGGGGCGCTGAAGATGTCAGTAGATGTTGTTAACCCTAACGACACTGACGTCACCT TTGCTATTAAGCTAATTGATAGTGATATTCTTCCTGATTGGGTAGATGAGTCTCAAACCTCATTGGACTACTTTACGGTTTCAGCTAATACCA CGCAGACCTTTAGCTTTAACTTAAATGGCGGCAACGAGTTCCAAACTCATGGCGAAAACTTTAGTAAAGATAAAGTTATCGGTGTGCAGTTC ATGCTCTCTGAAAACGATCCTCAAGTGTTGTACTTTGACAACATTATGGTTGATGGCGAAACAGTCACTCCGCCACCAAGTGATGGTGCAG TGAATACACAAACCGCGCCTGTAGCCACCTTAGCGCAAATCGAAGACTTTGAAACCATTCCAGATTACGACCTGATGGTGGGGTAAA CGTTTCAACTACTACTGAGATTGTGACTAAAGGCGCTGCAGCAATGGCTGCCGAGTTTACTGCAGGTTGGAACGGTTTAGTGTTTGCAGGT ACTTGGAATTGGGCTGAACTAGGTGAACACACCGCAGTTGCCGTTGACGTTTCAAATACTAGCGATAGCAATATCTGGTTGTACTCACGTAT CGAAGATGTAAATAGCCAAGGCGAAACAGCGACTCGCGGCGTATTGGTTAAAGCTGGCGAATCGAAAACCATCTACACCAGCTTAAATGA CAACCCTTCATTGCTTACTCAAGATGAGCGCGTGTCAGCTTTAGGTTTACGTGATATTCCAGCTGACCCAATGAGCGCTCAAAATGGCTGG GGTGATTTTGTTGCTTTAGACAAATCTCAAATTACCGCTATTCGTTACTTCATTGGCGAATTAGCCAGCGGTGAGACTAGCCAAACACTTGT GTTTGATAACATGCGTGTGATTAAAGACCTTAACCACGAATCAGCCTATGCAGAAATGACTGATGCTATGGGGCAAAACAACTTAGTCACTT ATGCAGGTAAAGTTGCCAGCAAAGAAGAGTTAGCTAAGTGATCCGGAAATGGCTGTTTTGGGTGAGTTAACCAATCGCAATATGTA CGGTGGTAACCCAGATTCGTCGCCAACTACAGACTGTGTGCTCGCTACGCCTCGTTTAACGCTTGTAAAGACGCTGATGGTAACTG GCAATTGGTAGACCCTGCTGGTAATGCGTTCTTCTCAACCGGTGTTGATAACATTCGTTTGCAAGATACTTACACCATGACCGGCGTGTCG AGTGACGCCGAATCTGAGTCTGCACTTCGCCAGTCAATGTTTACAGAAATTCCAAGTGATTATGTAAATGAAAACTATGGCCCTGTGCATAG TGGACCTGTTTCTCAAGGCCAAGCTGTAAGTTTTTACGCTAATAACTTAATTACCCGCCACGCTAGCGAAGACGTATGGCGAGACATTACTG TTAAGCGCATGAAAGACTGGGGCTTTAACACCTTAGGTAACTGGACCGATCCAGCGTTGTATGCAAACGGTGACGTTCCTTACGTGGCAAA TGGTCAACCTCTGGTGCCGATCGTCTTCCCGTTAAACAAATTGGCAGCGGCTACTGGGGACCACTTCCTGATCCGTGGGATGCTAA CTTTGCTACCAATGCCGCCACAATGGCTGCAGAGATCAAAGCTCAGGTTGAAGGCAACGAAGAGTACTTAGTGGGTATTTTTGTTGATAAC GAAATGAGCTGGGGCAATGTCACTGATGTTGAAGGCTCTCGTTATGCGCAAACGCTAGCAGTGTTCAATACCGACGGCACTGATGCAACA ACTAGCCCTGCTAAAAATAGCTTTATTTGGTTCTTAGAAAACCAGCGTTATACCGGTGGCATTGCTGACCTAAACGCAGCCTGGGGAACCG ATTATGCGTCTTGGGATGCGCCCAGCGCAAGAGTTAGCTTATGTGGCATGGAAGCTGATATGCAGTTCCTTGGCAGT TTGCGTTCCAATACTTCAACACCGTAAACACGGCATTAAAAGCTGAGTTACCAAACCACTTGTACTTGGGCTCTCGCTTTGCAGATTGGGGA CGTACTCCTGATGTAGTAAGTGCTGCTGCGGCTGTTGTTGATGAGTTACAACATCTACAAAGACAGTATTGCAGCTGCCGATTGGG ATGCTGATGCCTTAAATCAAATTGAAGCCATTGATAAGCCAGTAATTATTGGTGAGTTCCACTTCGGTGCGCTTGATAGCGGTTCGTTTGCA GAAGGTGTAGTAAATGCCACTTCGCAACAAGATCGTGCAGACAAAATGGTTAGCTTCTACGAATCAGTAAATGCCCATAAAAACTTTGTAGG TGCGCATTGGTTCCAATACATCGATTCACCATTAACGGGTCGTGCATGGGATGGCGAGAACTACAACGTTGGTTTTGTTAGCAATACTGAC ACGCCATATACATTGATGACAGATGCTGCGCGTGAGTTTAACTGTGGTATGTACGGCACTGCTCTAGCTTAAGCAATGCTACTGAAG CTGCTTCGAGAGCCGGTGAGTTGTATACCGGTACCAATATTGGTGTTAGCCACTCTGGCCCAGAAGCGCCAGATCCAGGTGAGCCAGTTG ATCCTCCAATTGATCCGCCAACACCACCAACAGGTGGCGTAACTGGCGGTAGCGCAGGTTATCGCTACTAGGTTTGGCC GGCGTATTTTTACTAAGACGTCGTAAAGTG

Ag 17 agarase protein MKIKFLSAAIAASLALPLSAATLVTSFEEADYSSSENNTEFLEVSGDATSE VSTEQATDGNQSIKASFDAAFKPMVVWNWGSWNWGAEDVMSVDVVN PNDTDVTFAIKLIDSDILPDWVDESQTSLDYFTVSANTTQTFSFNLNGGN EFQTHGENFSKDKVIGVQFMLSENDPQVLYFDNIMVDGETVTPPPSDGA VNTQTAPVATLAQIEDFETIPDYLRPDGGVNVSTTTEIVTKGAAAMAAEFT AGWNGLVFAGTWNWAELGEHTAVAVDVSNTSDSNIWLYSRIEDVNSQG ETATRGVLVKAGESKTIYTSLNDNPSLLTQDERVSALGLRDIPADPMSAQ NGWGDFVALDKSQITAIRYFIGELASGETSQTLVFDNMRVIKDLNHESAY AEMTDAMGQNNLVTYAGKVASKEELAKLSDPEMAVLGELTNRNMYGG NPDSSPTTDCVLATPASFNACKDADGNWQLVDPAGNAFFSTGVDNIRL QDTYTMTGVSSDAESESALRQSMFTEIPSDYVNENYGPVHSGPVSQGQ AVSFYANNLITRHASEDVWRDITVKRMKDWGFNTLGNWTDPALYANGD VPYVANGWSTSGADRLPVKQIGSGYWGPLPDPWDANFATNAATMAAEI KAQVEGNEEYLVGIFVDNEMSWGNVTDVEGSRYAQTLAVFNTDGTDAT TSPAKNSFIWFLENQRYTGGIADLNAAWGTDYASWDAMRPAQELAYVA GMEADMQFLAWQFAFQYFNTVNTALKAELPNHLYLGSRFADWGRTPD VVSAAAAVVDVMSYNIYKDSIAAADWDADALNQIEAIDKPVIIGEFHFGAL DSGSFAEGVVNATSQQDRADKMVSFYESVNAHKNFVGAHWFQYIDSPL TGRAWDGENYNVGFVSNTDTPYTLMTDAAREFNCGMYGTDCSSLSNA TEAASRAGELYTGTNIGVSHSGPEAPDPGEPVDPPIDPPTPPTGGVTGG GGSAGWLSLLGLAGVFLLRRRKV
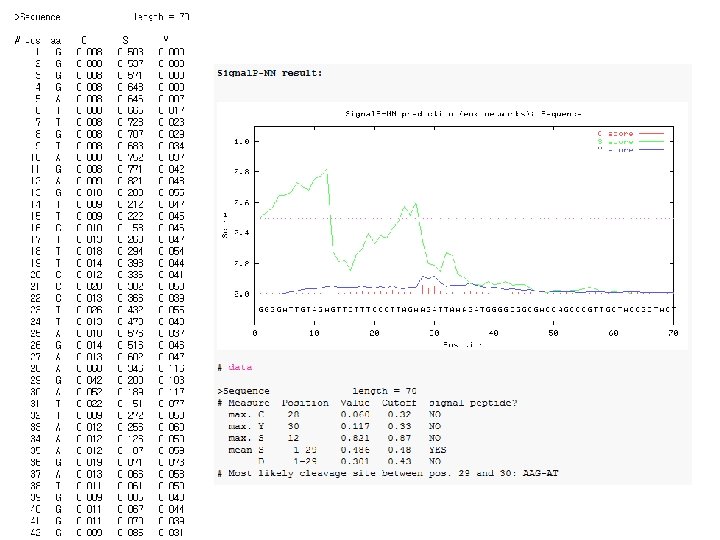
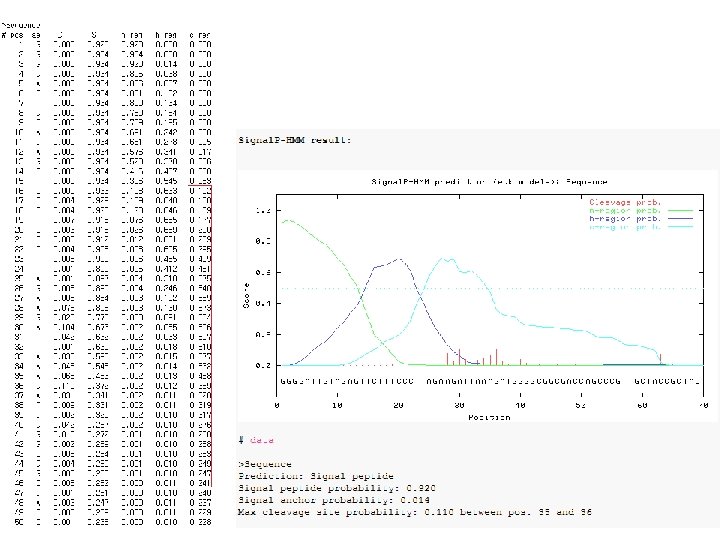
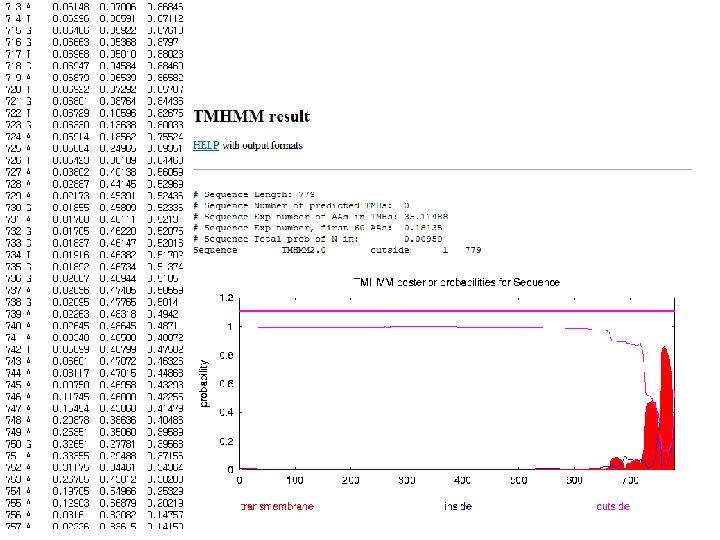
 and hidden Markov models (HMM) trained on")
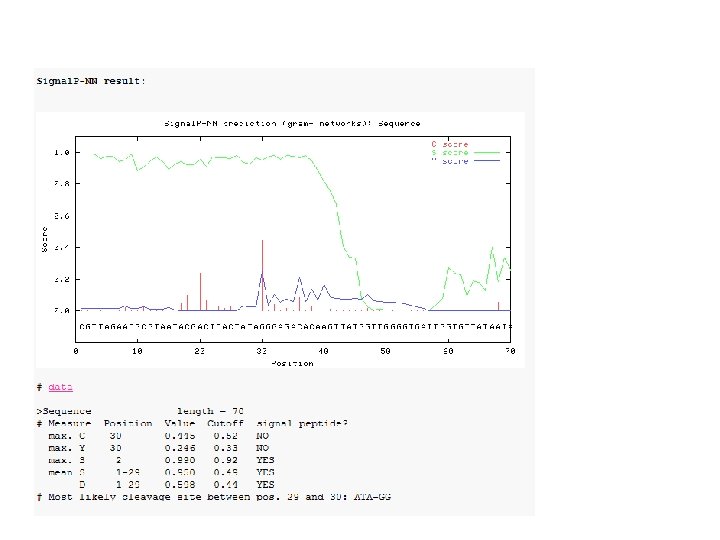
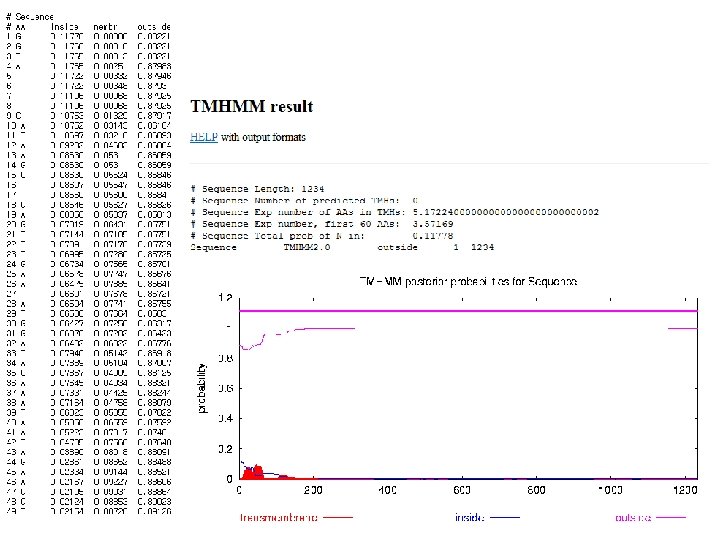
AG 17 agarase -Using neural networks (NN) and hidden Markov models (HMM) trained on Gram-negative bacteria

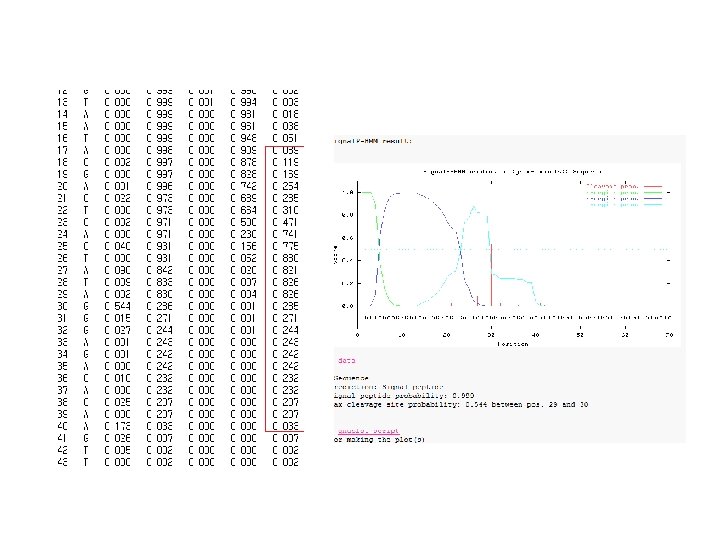
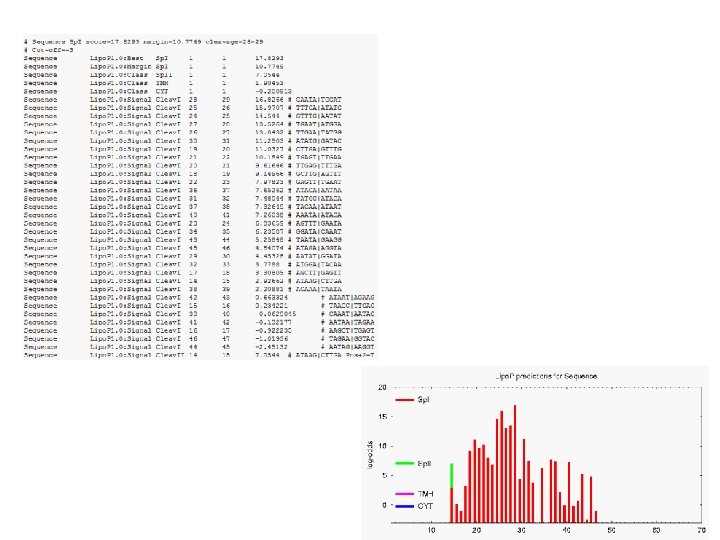
Ag 17 –lipoprotein site The output format is essentially in GFF format. The default (long) output format looks like this: # ANIA_NEIGO Sp. II score=29. 6052 margin=11. 2327 cleavage=18 -19 Pos+2=G # Cut-off=-3 ANIA_NEIGO Lipo. P 1. 0: Best Sp. II 1 1 29. 6052 ANIA_NEIGO Lipo. P 1. 0: Margin Sp. II 1 1 11. 2327 ANIA_NEIGO Lipo. P 1. 0: Class Sp. I 1 1 18. 3725 ANIA_NEIGO Lipo. P 1. 0: Class CYT 1 1 -0. 200913 ANIA_NEIGO Lipo. P 1. 0: Signal Cleav. II 18 19 29. 6052 FALAA|CGGEQ Pos+2=G ANIA_NEIGO Lipo. P 1. 0: Signal Cleav. I 24 25 18. 0333 GGEQA|AQAPA ANIA_NEIGO Lipo. P 1. 0: Signal Cleav. I 20 21 15. 9259 LAACG|GEQAA ANIA_NEIGO Lipo. P 1. 0: Signal Cleav. I 26 27 12. 0794 EQAAQ|APAET ANIA_NEIGO Lipo. P 1. 0: Signal Cleav. I 25 26 11. 4077 GEQAA|QAPAE ANIA_NEIGO Lipo. P 1. 0: Signal Cleav. I 27 28 9. 40252 QAAQA|PAETP # # #

AG 31 agarase full sequence ORF CGTTAGAACGCGTAATACGACTCACTATAGGGAGACACAAGTTATGGTTGGGGTGATTGGTGTTATAATAATGGAAACCG ACGTTATATGCGTATGGGTGTAAACTGGATTAGTCCAAAACATTTTGAGTATTATATTGATGGTGAGTTAGAGTGAT GTATTATAATGCAATTGCCACTAATTACAACGGAACTTGGCAATACACATATTTTAATTCTATGAATTGGAATGTAAATGGA TATAATCTTCCTACTAACAACGGATCTGGATATACAGATGTAACTACTTATGCTACATCTAATGCATACGATTTTGAAAAAT TAAAGGAAGCATCTAATGCATCTAACGGTTTTAATGTAATTGATCCGGCTTGGTTCCAAGGGGGAGATGATAGTGATACA GATGGAAATGGAGTAACACAAGAGGCTAGAGGATTCACTAAAGAATTAGATATTATTATTAATATGGAATCACAAACGTGG TTAACAGCTTCTACACCATCACAAAGTGATTTAGAAAACCCAGCGAAAAATCAAATGAAAGTAGATTGGGTACGTGTTTAC AAACCTGTATCATCTAATCCAGGTTCAGATGTAGCGGTACAAAGCGTCTCTTTATCACCTGCTAATTTAACTATGTCAGAA GGAGAGACGAGTAACTTAACAGGTAGAGTGCTGCCTTCGAATGCTACAATCCAAACAATTGCTTTTACTTCTAATAATACA AATGTAGTTTCTGTTAATCAGGCTTACTAACTGCAAACGGAATTGGTACAGCAATAATTACAGCTACATCTACAGAC GGTGGTTATACTGCAACTTCTAATATTACTGTAGAGGCTGAAGATGTTGGAGGTCCAATAAGCTCTTTAGAAATTGAAGCT GATGATTTCTCATCAACAGGCGGTACATTTAATGACGGTGTTGTTCCTTTTGGTGCAAATCATCAATTGGTGTTAATT ATATTAATGCTGGTGATTACATGGAATATGTAGTCGCAATTGCTGAAATGGGAGACTACTCTCTTATCAAATATCTAC TCCAAGTGATAATGCTAAAATTGCATGTTGATGGTAATTTAGTAGCAGATGATAATGTTCAAAACAATGGACAGTG GGATGCATACCAAGCATTAACTGCTTCTAATAATTTATCGCTAACAACTGGTAATCATACAATTAAAATTGAAGCTTCAGGC AGCAATGATTGGCAATGGAATCTTGATAAAATGAATTTAGAAAAATTAGGTTCAGGAACGAATCCTGAAGAACCAACGCCT CCTTTAGCCGAAGATTTTGTAATTCAAGCGGAAGACTATAATGAAACAAGTGGTAGTTTTAATGACGGTTTTGTCCCTTTT GGTGTTAACGCATCTGCAAATGGAATTATGTTAATGCAGAAGATTGGGCGGATTATGAAGTTTATCTTCCAGAGGCA GGTACATTTAACGTAACCTACACAATTGCAACGCCAAGCGATAATGCACAAATTGTAGTCTCCCTATAGTGAGTC GTATTACGCGTTCTAGCGACAATATGTACAATCACTAGGAATTCGCGGCCGCCTG

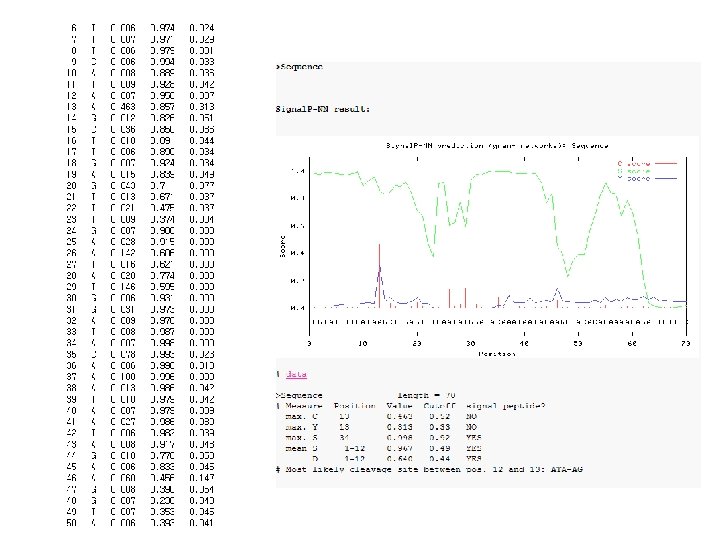
ag-31 -Lipo. P

AG 52 agarase full sequence ORF GGTATTTTCATAAGCTTGAGTTTGAATATGGATACAAATAATAGAAGGTACACACAAAAGA GATTGTTTCATCTAGGGCCTGTTTATCTTTCGATGATTAAATTCACAAAAGTCACTCGCACT AGTTAAAGAAGCATATCTACATTAATTTGCATGGAGATTTTATATGAATATATTAAAACTACT ATCCTGTTCTACTTGCGCAATACTCTGCACAGCAACACATGCTGCAGATTGGGACGCATA TAGTATTCCGGCTTCTGCTGGATCAGGTAAAACATGGCAATTACAAACTGTTTCCGACCAA TTTAACTACCAAGCCGGTACTTCAAATAAACCGGCAGCATTTACCAATCGTTGGAATGCTT CGTATATTAATGCTTGGGCCTGGTGATACTGAATTCAGGTCATTCCTACAC TACTGGTGGTGCGTTAGGCCTTCAGGCAACTGAAAAAGCAGGAACAAATAAAGTGCTTGC AGGAATTGTTTCTTCAAAAGCAACTTTTACATACCCACTTTATCTTGAGGCAATGGTAAAAC CGAGTAATAACACTATGGCTAATGGTGTATGGATGTTGAGCTCTGATTCAACTCAGGAAAT TGATGCGATGGAGGCATACGGCAGTGATCGTGTAGGGCAAGAGTGGTTTGACCAACGTA TGCACGTAAGTCACCATGTTTTTATACGTGAGCCATTTCAAGATTACCAAAAGATGC AGGCTCTTGGGTATACAATAACGGCGAAACATACCGAAATTTCGTCGCTACGGTGT TCATTGGAAGGACGCGTGGAACCTAGATTACTATATTGATGGTGTATTAGTTCGCAGCGT TTCAGGTCCTAATATAATTGATCCTGAAGGCTATACCGGTGGCACAGGGCTAAGTAAACC AATGCACATCCTTTTAGATATGGAACATCAACCTTGGCGTGATGTAAAACCAAATTCAGCC GAGCTGATTCAAAAGTATATTTTGGATTGACTGGATACGTGTCTACAAAGCAA ACTAAGTCATTCTAAAATATTTGTAATATTAGGTTTTATTGCTTCTCGTTATACGACACGGA GCAATAAACTTTAAGGTCCCCAAAACTACTTAATGCGGCTATTACAGCCGCATTAAGTATA ATTAACCTGAACTCTGGATAGTAAATCTCGAGCAGCTATTGACGCGTGAATTCTCTC CCTATAGTGAGTCGTA
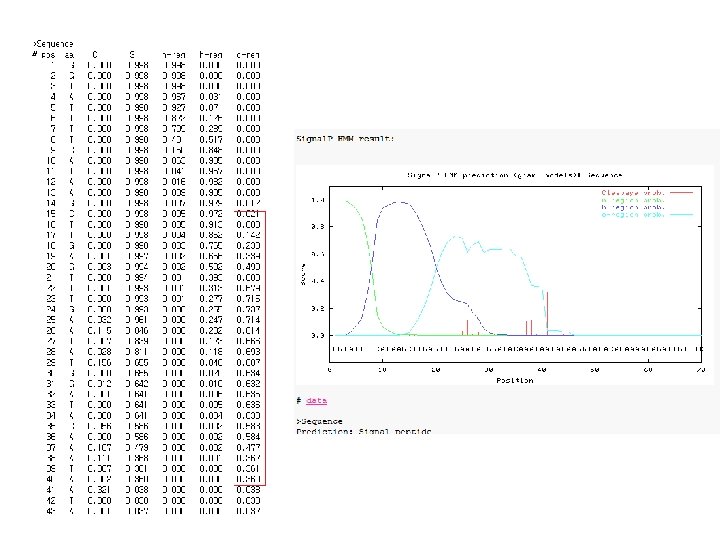

전복 QM protein - full sequence ORF GGGGATTGTAGAGTTCTTTCCCTTAGAAGATTAAAGATGGGGCGGCGACCAGCCCGTTGCTACCGCTACTGTAAAAA CAAGCCGTATCCCAAGTCACGGTTTTGCCGTGGTGTCCCAGATCCAAAGATCCGAATCTTTGATTTGGGCAGAAAGA AGGCTCGTGTTGATGAGTTCCCTCTCTGCATCCACTTGATCTCCGATGAGTATGAACAGCTGTCATCGGAAGCTCTGG AGGCTGGACGTATCTGCGCCAACAAGTACCTGGTGAAGGTCTGCGGCAAGGATTCCACTTACGTGTGCGCTTA CATCCCTTCCACGTCATCAGGATCAACAAGATGTTGTCCTGTGCCGGTGCTGATCGACTTCAGACCGGTATGCGTGG TGCTTGGGGTAAACCTCAAGGGACTGTGGCCCGTGTAAACATTGGACAGCCGATCATGTCGGTCCGTTCCAGAGAG CAGAACGAGTCTGCTGTGATTGAGGCCCTCCGGAGAGCCAAGTTCAAGTACCCTGGCAGAAGATTGTGCTCTC CAAGAAGTGGGGATTCACCAAGTGGCCAAGAGACTGCTATGAGGATATGTGCGCTGATGGACGCCTGATTCCTGAC GGTGTCAGTGTTCAGTACAGACCCAACCGAGGCCCTCTCAACAAGTGGAGAAAGGACCAACCTCAGGTC Cta g. ACAGACTGTTGGGACGAACATGGTCATGTGAATAAAGAGCTGGAGAAATAAAAAAAGAAAAAAAAAAA GDCRVLSLRRLKMGRRPARCYRYCKNKPYPKSRFCRGVPDPKIRIFDLGRKK ARVDEFPLCIHLISDEYEQLSSEALEAGRICANKYLVKVCGKDSFHLRVRLHPF HVIRINKMLSCAGADRLQTGMRGAWGKPQGTVARVNIGQPIMSVRSREQNE SAVIEALRRAKFKYPGRQKIVLSKKWGFTKWPRDCYEDMCADGRLIPDGVSV QYRPNRGPLNKWRKDQTNLRS

전복 alginate lyase - ORF ATGGACATTCCCATTACAAAACACTGGGATGGTGGTTTTCGGACTTCTGTGAACCTATTACTCA AACCATGCATTCCTGGAAAGCGCATGTCATCTTTGACCATCACGTCGATACGCTAGACATCTGGGTT GCTGATGTTCAGCAAACTCTGAATGGAGGTAAAGAGTTTGTCCTGGTCAACAAGGCATCTTATGGCG AGCAGAAGGCTGGCGACAAACTGTGAAACTAATTGGACGTGTCAACGGTGACATCGTTCCAAA AGGCCGGTTCTACATTGAAGGCATGGACGGCCCGGTATCAGCTACCGAGAAACCCATCAGACATACAAACCGGGCACGCCGACAACGTCTAGCCATGTCACAGGCAAAGTTCTTTATGAATATTATGGAT TCGATCCGAGTGATTACAAAAAGGGCATAACTGTGCTACAACATGGAGGCTTCGATGAAGACTCTGG CTCCGTTGTCCTTGACCCTGCCGGTACCGGGGAACATGTCCTCAAAGTGTTCTACGAGAAGGGACA CTATATCAAAGTTCGGGGCCACCGTGGGATTCAGTTCTACTGGACCCCTATCCCCAAACGACG CTGACGTTGAGCTACGACATCTACTTCGACCCCAACTTTGACTGGGTTAAGGGAGGCAAGCTTCCGG GTCTGTGGGGGAGGGTCCCAAACCCTGTTCTGGGGGACGTCACAACGAGGAATGTTTCTCAACACG CTTCATGTGGAGGACTGGTGGGGAACTGTACGCCTACATCCCCTCTGGACAACGCGCCG ACTTCTGCACTAAGAACATTTGCAACTTCGACTACGGTAACTCTTtag
- Slides: 22