Freeing Speech Common Voice and Deep Speech Why
 Speech Common Voice and Deep Speech")


































 Speech")
- Slides: 45
Free(ing) Speech Common Voice and Deep Speech
Why? Common Voice Deep Speech
Why?
How many languages have production quality, open speech recognition models?
Just one, English.
Why?
Despite the existence of various open STT engines ZERO LANGUAGES have the 10 k hours of open data needed for a production quality model.
Libri. Speech The largest open English corpus is Libri. Speech which is about 1 k hours
Formosa Grand Challenge Corpus The largest open Mandarin corpus is the Formosa Grand Challenge corpus which is about 400 hours
For Celtic languages. . . The availability of data sets of any size, free or at cost , drops off significantly
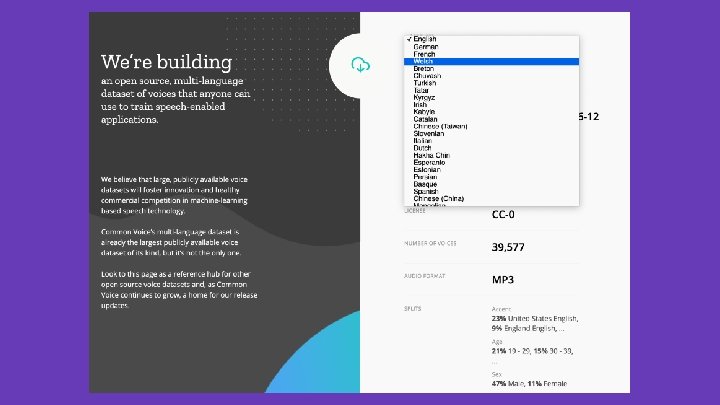
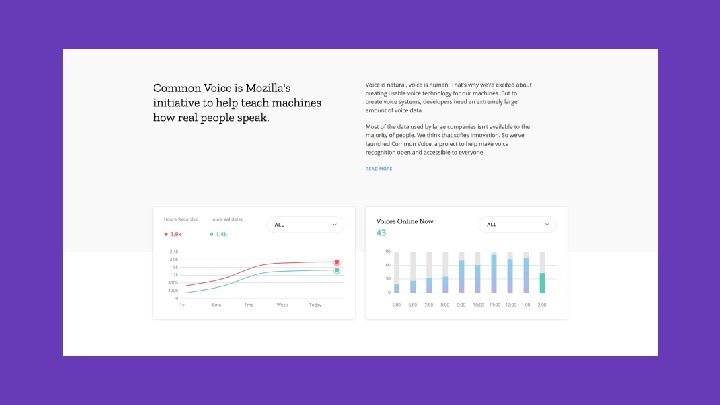
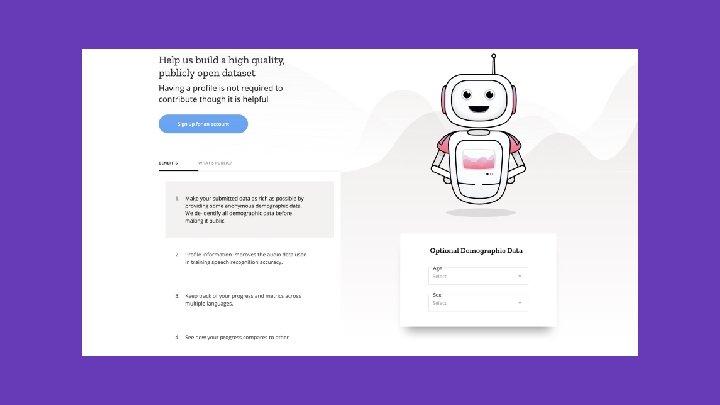
Common Voice
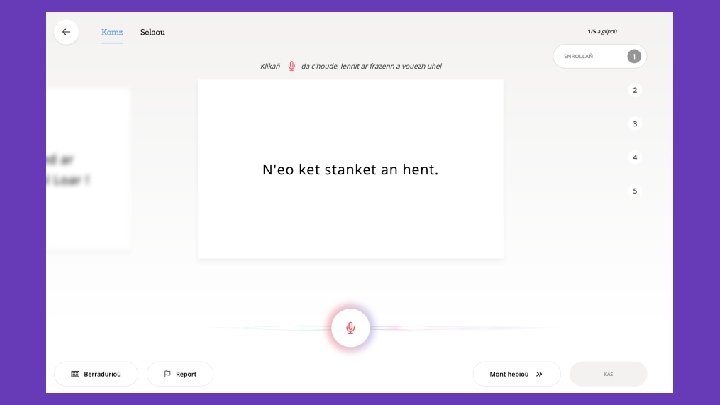
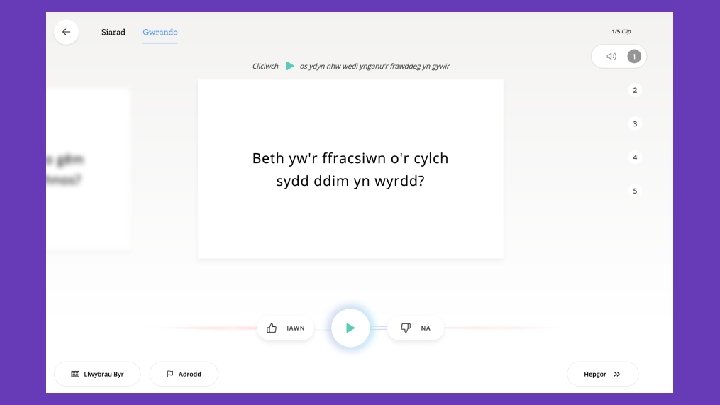
Collect
Validate
Distribute
And there’s more. . .
And there’s still more. . .
Deep Speech
Simple
A design principle we decided upon from the beginning is that the engine should work for ALL LANGUAGES the only requirement being that one have training data.
Perfection is achieved, not when there is nothing more to add, but when there is NOTHING LEFT TO TAKE AWAY -Antoine de Saint. Exupéry
More controversially, we decided that training a new language should not require LINGUISTIC KNOWLEDGE
Deep Speech Architecture Softmax Layer Feedforward Layer Recurrent Layer Feedforward Layers Input Features
Open
Deep Speech source code is released under Mozilla Public License 2. 0
Deep Speech modelsare released under Mozilla Public License 2. 0
Ubiquitous
Currently we support nine different Programming Languages
At the same time we also support nine different Platforms
Why? Common Voice Deep Speech
Why? Question: How many languages have production quality, open speech recognition models? Answer: Just one, English.
Common Voice ● Collect ● Validate ● Distribute
Deep Speech ● Simple ● Open ● Ubiquitous
Free(ing) Speech