First Chapter Introduction Data warehouse Prepared By Dr

First Chapter Introduction, Data warehouse Prepared By Dr. Maher Abuhamdeh
, consists of")
Database • A database system, also called a database management system (DBMS), consists of a collection of interrelated data, known as a database, and a set of software programs to manage and access the data.

Software • The software programs provide mechanisms for defining database structures and data storage; for specifying and managing concurrent, shared, or distributed data access; and for ensuring consistency and security of the information stored despite system crashes or attempts at unauthorized access.

A relational database • A relational database is a collection of tables, each of which is assigned a unique name. Each table consists of a set of attributes (columns or fields) and usually stores a large set of tuples (records or rows). and their relationships.
 • Each tuple in a relational table represents an object")
A relational database (continue) • Each tuple in a relational table represents an object identified by a unique key and described by a set of attribute values. A semantic data model, such as an entityrelationship (ER) data model, is often constructed for relational databases. An ER data model represents the database as a set of entities.

Example for LG company • The company is described by the following relation tables: customer, item, employee, and branch. The headers of the tables described

Relational schema for a relational database, LG company • customer (cust ID, name, address, age, occupation, annual income, credit information, category, . . . ) • item (item ID, brand, category, type, price, place made, supplier, cost, . . . ) • employee (empl ID, name, category, group, salary, commission, . . . ) • branch (branch ID, name, address, . . . ) • purchases (trans ID, cust ID, empl ID, date, time, method paid, amount) • items sold (trans ID, item ID, qty) works at (empl ID, branch ID)

• Relational data can be accessed by database queries written in a relational query language (e. g. , SQL) or with the assistance of graphical user interfaces. • CEO asked his managers “Show me a list of all items that were sold in the last quarter Q 2 2015”

Data Warehouses • Suppose that LG company is a successful international company with branches around the world. Each branch has its own set of databases. The CEO of LG has asked his managers to provide him an analysis of the company’s sales per item type per branch for the second quarter 2015
 • This is a difficult task, particularly since the relevant data")
Without Data warehouse(DW) • This is a difficult task, particularly since the relevant data are spread out over several databases physically located at numerous sites.

With DW • If LG had a data warehouse, this task would be easy

What is a data warehouse • DW is a repository of information collected from multiple sources, stored under a unified schema, and usually residing at a single site. • Data warehouses are constructed via a 1 - process of data cleaning 2 - data integration 3 - data transformation 4 - data loading 5 - periodic data refreshing

Typical framework of a data warehouse for LG

A data cube for LG
 • A data cube for summarized sales")
A data cube for LG (Cont. ) • A data cube for summarized sales data of LG is presented in Figure above. The cube has three dimensions: • address (with city values Chicago, New York, Toronto, Vancouver). • time (with quarter values Q 1, Q 2, Q 3, Q 4). • item(with item type values home entertainment, computer, phone, security). The aggregate value stored in each cell of the cube is sales amount (in thousands).
 • For example, the total sales for")
A data cube for LG (Cont. ) • For example, the total sales for the first quarter, Q 1, for the items related to security systems in Vancouver is $400, 000, as stored in cell (Vancouver, Q 1, security). Additional cubes may be used to store aggregate sums over each dimension, corresponding to the aggregate values obtained using different SQL groupbys(e. g. , the total sales amount per city and quarter, or per city and item , or per quarter and item, or per each individual dimension).
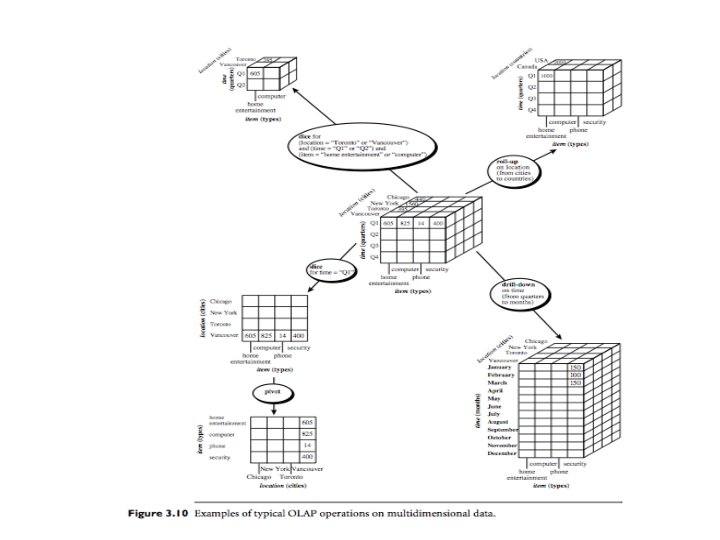
 • Examples of OLAP operations include drilldown")
A data cube for LG (Cont. ) • Examples of OLAP operations include drilldown and roll-up, which allow the user to view the data at differing degrees of summarization, as illustrated in above Figure For instance, we can drill down on sales data summarized by quarter to see data summarized by month. Similarly, we can roll up on sales data summarized by city to view data summarized by country.

What is a Data Warehouse? • Defined in many different ways, but not rigorously. – A decision support database that is maintained separately from the organization’s operational database – Support information processing by providing a solid platform of consolidated, historical data for analysis. • “A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decision-making process. ”—W. H. Inmon • Data warehousing: – The process of constructing and using data warehouses 18

Data Warehouse—Subject-Oriented • Organized around major subjects, such as customer, product, sales • Focusing on the modeling and analysis of data for decision makers, not on daily operations or transaction processing • Provide a simple and concise view around particular subject issues by excluding data that are not useful in the decision support process 19

Data Warehouse—Integrated • Constructed by integrating multiple, heterogeneous data sources – relational databases, flat files, on-line transaction records • Data cleaning and data integration techniques are applied. – Ensure consistency in naming conventions, encoding structures, attribute measures, etc. among different data sources • E. g. , Hotel price: currency, tax, breakfast covered, etc. – When data is moved to the warehouse, it is converted. 20

Data Warehouse—Time Variant • The time horizon for the data warehouse is significantly longer than that of operational systems – Operational database: current value data – Data warehouse data: provide information from a historical perspective (e. g. , past 5 -10 years) • Every key structure in the data warehouse – Contains an element of time, explicitly or implicitly – But the key of operational data may or may not contain “time element” 21

Data Warehouse—Nonvolatile • A physically separate store of data transformed from the operational environment • Operational update of data does not occur in the data warehouse environment – Does not require transaction processing, recovery, and concurrency control mechanisms – Requires only two operations in data accessing: • initial loading of data and access of data 22

Differences between Operational Database Systems and Data Warehouses • Users and system orientation: An OLTP system is customer-oriented and is used for transaction and query processing by clients, and information technology professionals. An OLAP system is market-oriented and is used for data analysis by knowledge workers, including managers, executives, and analysts January 30, 2022 Data Mining: Concepts and Techniques 23

Differences between Operational Database Systems and Data Warehouses • Data content: An OLTP system manages current data that, typically, are too detailed. An OLAP system manages large amounts of historic data, provides facilities for summarization and aggregation. January 30, 2022 Data Mining: Concepts and Techniques 24

Differences between Operational Database Systems and Data Warehouses • Database design: An OLTP system usually adopts an entityrelationship (ER) data mode. and an application-oriented database design. An OLAP system typically adopts either a star or a snowflake model January 30, 2022 Data Mining: Concepts and Techniques 25

Differences between Operational Database Systems and Data Warehouses § View: An OLTP system focuses mainly on the current data within an enterprise or department, without referring to historic data. OLAP system often spans multiple versions of a database schema OLAP systems also deal with information that produce from different organization. January 30, 2022 Data Mining: Concepts and Techniques 26

Differences between Operational Database Systems and Data Warehouses § Access patterns: The access patterns of an OLTP system consist mainly of short, atomic transactions. Such a system requires concurrency control and recovery mechanisms. However, accesses to OLAP systems are mostly read-only operations(because most data warehouses store historic rather than up-to-date information), although many could be complex queries January 30, 2022 Data Mining: Concepts and Techniques 27

OLTP vs. OLAP 28

Why a Separate Data Warehouse? • High performance for both systems – DBMS— tuned for OLTP: access methods, indexing, concurrency control, recovery – Warehouse—tuned for OLAP: complex OLAP queries, multidimensional view, consolidation • Different functions and different data: – missing data: Decision support requires historical data which operational DBs do not typically maintain – data consolidation: DS requires consolidation (aggregation, summarization) of data from heterogeneous sources – data quality: different sources typically use inconsistent data representations, codes and formats which have to be reconciled • Note: There are more and more systems which perform OLAP analysis directly on relational databases 29

A multi-dimensional data model • A data warehouse is based on a multidimensional data model which views data in the form of a data cube

Data cube • A data cube, such as sales, allows data to be modeled and viewed in multiple dimensions • Suppose LG company create a sales data warehouse with respect to dimensions – Time – Item – Location

3 D Data cube Example

Data cube • A data cube, such as sales, allows data to be modeled and viewed in multiple dimensions • Suppose LG create a sales data warehouse with respect to dimensions – Time – Item – Location – Supplier

4 D Data cube Example
 relative")
Dimensions and Hierarchies • A cell in the cube may store values (measurements) relative to the combination of the labeled dimensions cit y Sales of DVDs in NY in August NY DIMENSIONS PRODUCT LOCATION TIME category region year product DVD product country month August state city store quarter month week day 36

Common OLAP Operations • Roll-up: move up the hierarchy – e. g given total sales per city, we can roll-up to get sales per state PRODUCT LOCATION TIME • Drill-down: move down the hierarchy – more fine-grained aggregation – lowest level can be the detail records (drill-through) category region year product country quarter state city month week day store 37

Slice and Dice • Slice and Dice: select and project on one or more dimensions pr od uc t customers store customer = “Smith” 38

Slice and Dice • Slice: Performa a selection on one dimension of the given cube Slice resulting in a sub cube Dice: defines a sub cube by performing a selection on two or more dimensions 39
: aggregate on selected dimensions – usually 2 dims (cross-tabulation) 40")
Pivoting • Pivoting (Rotate): aggregate on selected dimensions – usually 2 dims (cross-tabulation) 40

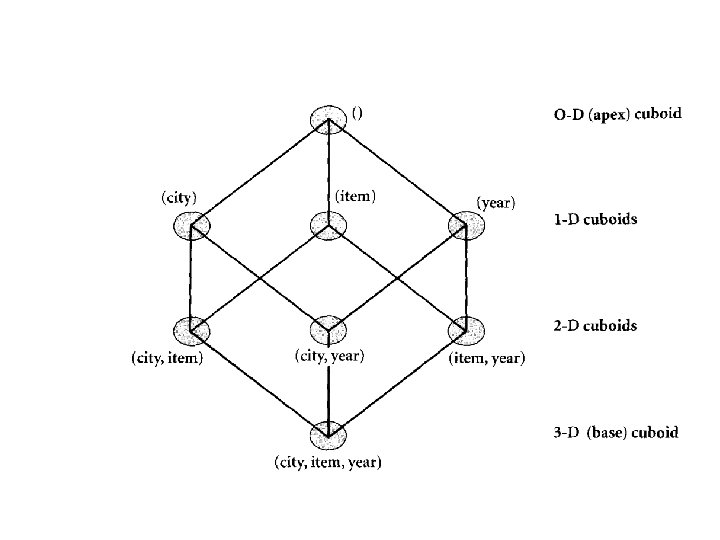
The compute cube operators Suppose that you want to create a data cube for LG sales that contains the following: city, item, year, and sales in Jordan Dinar. You want to be able to analyze the data, with queries such as the following: “Compute the sum of sales, grouping by city and item. ” “Compute the sum of sales, grouping by city. ” “Compute the sum of sales, grouping by item. ”

What is the total number of cuboids, or group-by’s, that can be computed for this data cube? Taking the three attributes, city, item, and year, as the dimensions for the data cube, and sales in dollars as the measure, the total number of cuboids, or group by’s, that can be computed for this data cube is 2 the power 3 wihich is equal 8. The possible group-by’s are the following: {(city, item, year), (city, item), (city, year), (item, year), (city), (item), (year), () }. /g, where. / means that the group-by is empty (i. e. , the dimensions are not grouped). These group-by’s form a lattice of cuboids for the data cube,

Conceptual Modeling of Data Warehouses – Star schema – Snowflake schema – Fact constellations

Conceptual Modeling of Data Warehouses • Star schema: A fact table in the middle connected to a set of dimension tables • It contains: – A large central table (fact table) – A set of smaller attendant tables (dimension table), one for each dimension

Star schema

Conceptual Modeling of Data Warehouses • Snowflake schema: A refinement of star schema where some dimensional hierarchy is further splitting (normalized) into a set of smaller dimension tables, forming a shape similar to snowflake • However, the snowflake structure can reduce the effectiveness of browsing, since more joins will be needed

Snowflake schema

Conceptual Modeling of Data Warehouses • Fact constellations: Multiple fact tables share dimension tables, viewed as a collection of stars, therefore called galaxy schema or fact constellation

Fact constellations

A three tier - Data warehouse architecture

Multi-Tiered Architecture other Metadata sources Operational DBs Extract Transform Load Refresh Monitor & Integrator Data Warehouse OLAP Server Serve Analysis Query Reports Data mining Data Marts Data Sources Data Storage OLAP Engine Front-End Tools 52

Data warehouse & data marts • A data warehouse collects information about subjects that span the entire organization, such as customers, items, sales, assets, and personnel, and thus its scope is enterprisewide. • A data mart, is department subset of the data warehouse that focuses on selected subjects, and thus its scope is department wide.
- Slides: 53