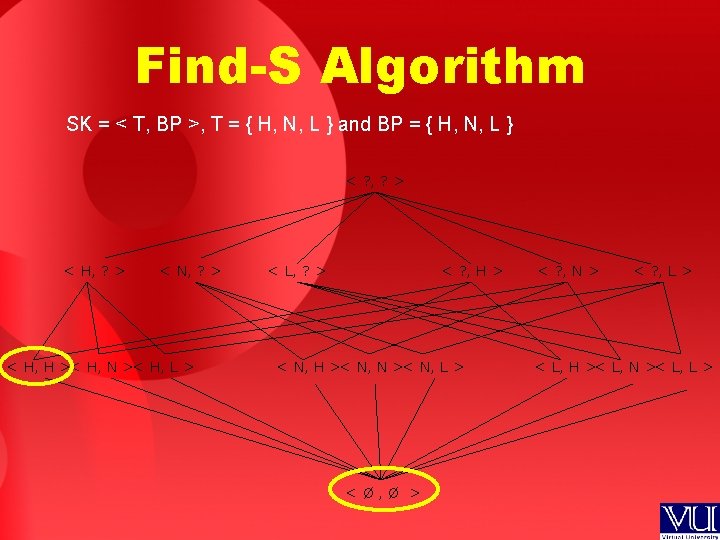
FindS Algorithm FINDS finds the most specific hypothesis
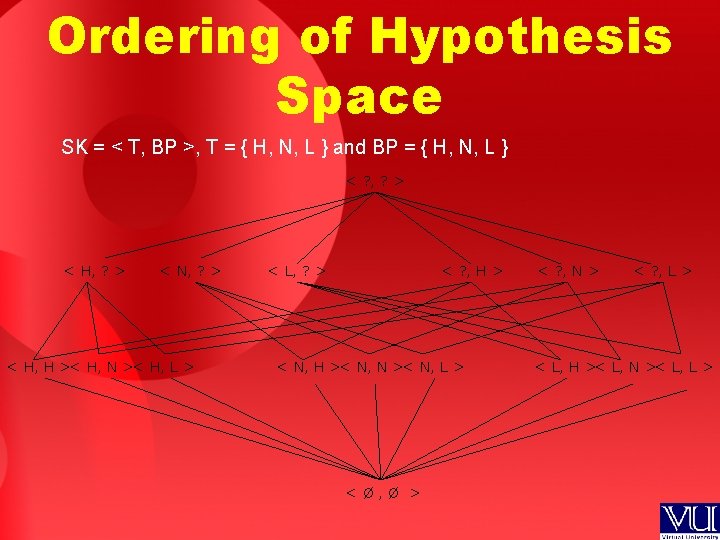







 • Version space is a set of all the hypotheses that")




")



- Slides: 19
Find-S Algorithm • FIND-S finds the most specific hypothesis possible within the version space given a set of training data • Uses the general-to-specific ordering for searching through the hypotheses space
Find-S Algorithm Initialize hypothesis h to the most specific hypothesis in H (the hypothesis space) For each positive training instance x (i. e. output is 1) For each attribute constraint ai in h If the constraint ai is satisfied by x Then do nothing Else Replace ai in h by the next more general constraint that is satisfied by x Output hypothesis h
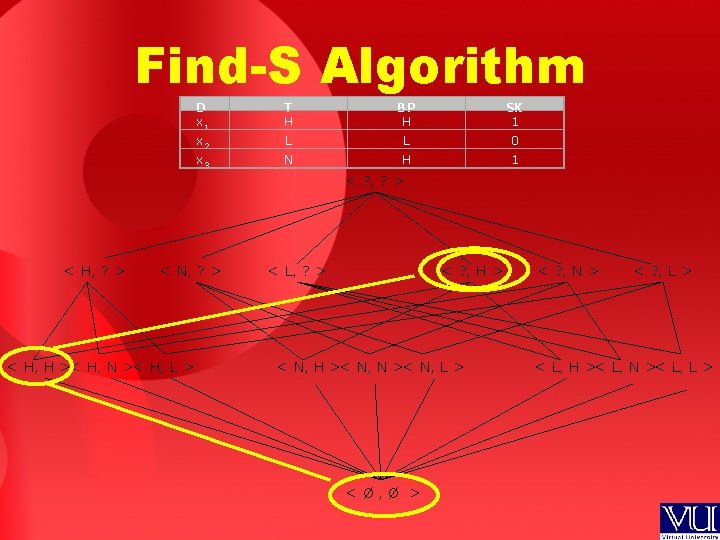
Find-S Algorithm To illustrate this algorithm, let us assume that the learner is given the sequence of following training examples from the SICK domain: D T BP SK x 1 H H 1 x 2 L L 0 x 3 N H 1 The first step of FIND-S is to initialize hypothesis h to the most specific hypothesis in H: h=<Ø, Ø>
Find-S Algorithm First training example is positive: D x 1 T H BP H SK 1 But h = < Ø , Ø > fails over this first instance Because h(x 1) = 0, since Ø gives us 0 for any attribute value Since h = < Ø , Ø > is so specific that it doesn’t give even one single instance as positive, so we change it to next more general hypothesis that fits this particular first instance x 1 of the training data set D to h=<H, H>
Find-S Algorithm D T BP SK x 1 H H 1 x 2 L L 0 Upon encountering the second example; in this case a negative example, the algorithm makes no change to h. In fact, the FIND-S algorithm simply ignores every negative example So the hypothesis still remains: h = < H , H >
Find-S Algorithm D T BP SK x 1 H H 1 x 2 L L 0 x 3 N H 1 Final Hypothesis: h = < ? , H > What does this hypothesis state? This hypothesis will term all the future patients which have BP = H as SICK for all the different values of T
Candidate-Elimination Algorithm • Although FIND-S does find a consistent hypothesis • In general, however, there may be more hypotheses consistent with D; of which FIND-S only finds one • Candidate-Elimination finds all the hypotheses in the Version Space
Version Space (VS) • Version space is a set of all the hypotheses that are consistent with all the training examples • By consistent we mean h(xi) = c(xi) , for all instances belonging to training set D
Version Space Let us take the following training set D: D T BP SK x 1 H H 1 x 2 L L 0 x 3 N N 0 Another representation of this set D: BP H - - 1 N - 0 - L 0 - - L N H T
Version Space Is there a hypothesis that can generate this D: BP H - - 1 N - 0 - L 0 - - L N H T One of the consistent hypotheses can be h 1 = < H, H > BP H 0 0 1 N 0 0 0 L N H T
Version Space There are other hypotheses consistent with D, such as h 2 = < H, ? > BP H 0 0 1 N 0 0 1 L N H T There’s another hypothesis, h 3 = < ? , H > BP H 1 1 1 N 0 0 0 L N H T
Version Space • Version space is denoted as VS H, D = {h 1, h 2, h 3} • This translates as: Version space is a subset of hypothesis space H, composed of h 1, h 2 and h 3, that is consistent with D • In other words version space is a group of all hypotheses consistent with D, not just one hypothesis we saw in the previous case
Candidate-Elimination Algorithm • Candidate Elimination works with two sets: – Set G (General hypotheses) – Set S (Specific hypotheses) • Starts with: – G 0 = {< ? , ? >} considers negative examples only – S 0 = {< Ø , Ø >} considers positive examples only • Within these two boundaries is the entire Hypothesis space
Candidate-Elimination Algorithm • Intuitively: – As each training example is observed one by one • The S boundary is made more and more general • The G boundary set is made more and more specific • This eliminates from the version space any hypotheses found inconsistent with the new training example – At the end, we are left with VS
Candidate-Elimination Algorithm Initialize G to the set of maximally general hypotheses in H Initialize S to the set of maximally specific hypotheses in H For each training example d, do If d is a positive example Remove from G any hypothesis inconsistent with d For each hypothesis s in S that is inconsistent with d Remove s from S Add to S all minimal generalization h of s, such that h is consistent with d, and some member of G is more general than h Remove from S any hypothesis that is more general than another one in S If d is a negative example Remove from S any hypothesis inconsistent with d For each hypothesis g in G that is inconsistent with d Remove g from G Add to G all minimal specializations h of g, such that h is consistent with d, and some member of S is more specific than h Remove from G any hypothesis that is less general than another one in G
Candidate-Elimination Algorithm D T BP SK x 1 H H 1 x 2 L L 0 x 3 N H 1 G 0 = {< ? , ? >} most general S 0 = {< Ø, Ø >} most specific