fast NLP fast NLP fast NLP fast Data








: Aggressive self-glorification and a manipulative whitewash. negative Best indie of the")

![在fast. NLP中用Bert做文本分��共需要几步 ? data_bundle = IMDBLoader(). process(‘imdb/’) bert_embed = Bert. Embedding(data_bundle. vocabs['words'], model_dir_or_name='en-base') model](https://slidetodoc.com/presentation_image_h2/16c29658c3f44765c9dd1722a8a276d0/image-15.jpg "在fast. NLP中用Bert做文本分��共需要几步 ? data_bundle = IMDBLoader(). process(‘imdb/’) bert_embed = Bert. Embedding(data_bundle. vocabs['words'], model_dir_or_name='en-base') model")
:")

:")


 dataset. set_target('target’) for")


: def __init__(self,")
")


 with open('.")



![在fast. NLP中用做中文序列�注�共需要几步 ? data_bundle = Chinese. NERLoader(). process('MSRA-NER/') char_embed = Static. Embedding(data_bundle. vocabs['chars'], model_dir_or_name='cn-char')](https://slidetodoc.com/presentation_image_h2/16c29658c3f44765c9dd1722a8a276d0/image-33.jpg "在fast. NLP中用做中文序列�注�共需要几步 ? data_bundle = Chinese. NERLoader(). process('MSRA-NER/') char_embed = Static. Embedding(data_bundle. vocabs['chars'], model_dir_or_name='cn-char')")
![Text Preprocess Index Embed Encode Decode Train def generate_bigram(instance): chars = instance['chars'] next_chars =](https://slidetodoc.com/presentation_image_h2/16c29658c3f44765c9dd1722a8a276d0/image-35.jpg "Text Preprocess Index Embed Encode Decode Train def generate_bigram(instance): chars = instance['chars'] next_chars =")

")
: chars =")
")





- Slides: 45
fast. NLP�什么
fast. NLP是什么
fast. NLP是什么? fast是什么? 数据 Data. Set 模型 Model �失函数与�价指 � Loss, Metric �化算法 Optimizer 参数学� Trainer
fast. NLP是什么 SGD Adam. W Ada. Grad Cross-entropy NLL. . Accuracy Span. F 1 Rouge … Optimizer Loss Metric Data. Set. Iter Data Tester Trainer Sampler Biaffine Star-Trans Text. CNN … Model Data. Loader Random. Sampler Data. Set Bucket. Sampler Vocabulary … … Embedding Encoder Decoder GLOVE ELMO BERT … LSTM Transformer CNN … CRF MLP …
文本分� 数据(情感分� ): Aggressive self-glorification and a manipulative whitewash. negative Best indie of the year , so far. positive It 's everything you 'd expect -- but nothing more. neutral
Bi. LSTM+MLP 模型�构 : he W 1 h 1 likes W 2 h 2 label size it W 3 h 3 . W 4 h 4 input embedding Bi. LSTM pooling Encoder module MLP decoder module label output
在fast. NLP中用Bert做文本分��共需要几步 ? data_bundle = IMDBLoader(). process(‘imdb/’) bert_embed = Bert. Embedding(data_bundle. vocabs['words'], model_dir_or_name='en-base') model = Bi. LSTMMLP(bert_embed, len(data_bundle. vocabs[‘target’])) Trainer(data_bundle. datasets[‘train’], model, loss=Cross. Entropy. Loss(), device=0, batch_size=32, dev_data=data_bundle. datasets['dev‘], metrics=Accuracy. Metric()). train() 只比把大象装�冰箱 多一步
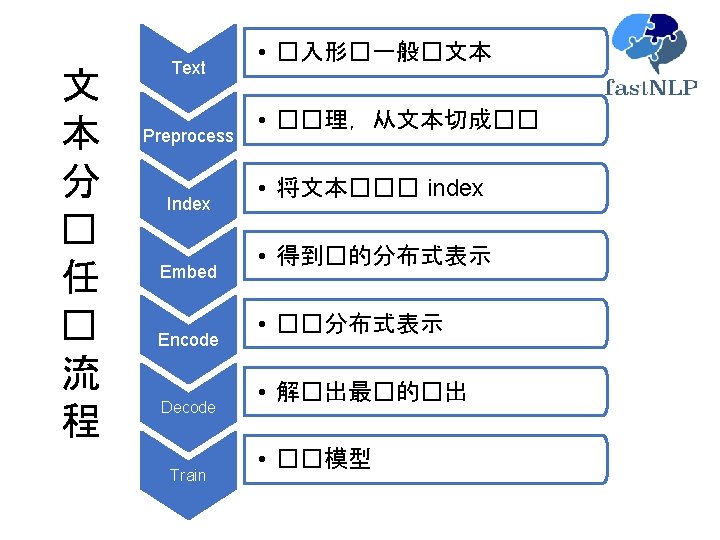
Text Preprocess Index Embed Encode Decode Train fast. NLP. core. Data. Set 示例(情感分� ): Aggressive self-glorification and a manipulative whitewash. negative Best indie of the year , so far. positive It 's everything you 'd expect -- but nothing more. neutral instance 1 raw_words 1 target 1 instance 2 raw_words 2 target 2 … … …. . 人�在理解数据�, 一般是通�一个一个 的sample去理解,即 通�行的方式 批�理更喜�以 列的方式�行� 取与�理 Batch 1
Text Preprocess Index Embed Encode Decode Train fast. NLP. core. Data. Set Field 1 Field 2 …… Instance …… …… Data. Set以列作�存�方式
Text Preprocess Index Embed Encode Decode Train fast. NLP. core. Data. Set 示例(情感分� ): Aggressive self-glorification and a manipulative whitewash. negative dataset = Data. Set() with open('train. txt', 'r') as f: for line in f: if line: parts = line. strip(). split('t') dataset. append(Instance(raw_words=parts[0], target=parts[1])) # 以行��位�取 # �理�以列��位 dataset. raw_words. split() # 将�一列的每一行内容按空格切分成独立的 word print(dataset[0]) �出 { 'raw_words': ['Aggressive', 'self-glorification', 'and', 'a', 'manipulative', 'whitewash', '. ’] type=list, 'target': negative type=str }
Text Preprocess Index Embed Encode fast. NLP. core. Vocabulary 当前的Data. Set raw_words target [‘Aggressive’, ‘self-glorification’, ‘and’, ‘a’, ‘manipulative’, ‘whitewash’, ’. ’] ‘negative’ [‘Best’, ‘indie’, ‘of’, ‘the’, ’year’] ‘positive’ … … 神�网�需要的 Data. Set(需要index) words target [2, 100, 245, 3, 50, 30, 10] 1 [3, 6, 101, 8, 19] 4 … … 使用Vocabulary来�� Decode Train
Text Preprocess Index Embed Encode Decode Train fast. NLP. core. Vocabulary 当前的Data. Set raw_words target [‘Aggressive’, ‘self-glorification’, ‘and’, ‘a’, ‘manipulative’, ‘whitewash’, ’. ’] ‘negative’ [‘Best’, ‘indie’, ‘of’, ‘the’, ’year’] ‘positive’ … … vocab = Vocabulary(). from_dataset(dataset, field_name='raw_words') vocab. index_dataset(dataset, field_name='raw_words', new_field_name='words') �理后的 Data. Set raw_words target [‘Aggressive’, ‘self-glorification’, ‘and’, ‘a’, ‘manipulative’, ‘whitewash’, ’. ’] [2, 100, 245, 3, 50, 30, 10] ‘negative’ [‘Best’, ‘indie’, ‘of’, ‘the’, ’year’] [3, 6, 101, 8, 19] ‘positive’ … …
fast. NLP. core. Data. Set. Iter 在�行 mini-batch-SGD的�候,每次取出 batch_size的数据,并做padding dataset. set_input('words') dataset. set_target('target’) for batch_x, batch_y in Data. Set. Iter(dataset, batch_size=32, num_workers=1, as_numpy=True): """ batch_x: {"words": (batch_size, max_len)的矩� } batch_y: {"target": (batch_size, )的向量} """ # 可以是pytorch的迭代或者tensorflow的迭代
Text Preprocess Index Embed Encode Decode Train �建模型 �� ���的 Embedding glove word 2 vec Char. Embedding ELMO Bert 50 d 100 d cnn small base 100 d 200 d lstm meidium large 300 d transformer large wwm … … … ��太多,且 Embedding之� tokenize的方式有很大差异 glove_embed = Static. Embedding(vocab, model_dir_or_name='en-glove-6 b-50’) glove_embed = Static. Embedding(vocab, model_dir_or_name='en-glove-840 b-300') word 2 vec_embed = Static. Embedding(vocab, model_dir_or_name='en-word 2 vec-300') tencent_embed = Static. Embedding(vocab, model_dir_or_name='cn-tencent')
Text Preprocess Index Embed Encode Decode Train �建模型 # 同�使用两种 embedding embed = Stack. Embedding([glove_embed, word 2 vec_embed]) # 使用character embedding和word embedding一�容易 char_embed = CNNChar. Embedding(vocab) embed = Stack. Embedding([char_embed, glove_embed]) Contextual Embedding: 一行代�切� ELMO,BERT elmo_embed = Elmo. Embedding(vocab, model_dir_or_name='en-original') bert_embed = Bert. Embedding(vocab, model_dir_or_name='en-base’) embed = Stack. Embedding([glove_embed, elmo_embed, bert_embed]) �里的 Embedding和pytorch的Embedding是一�,所以可以与其它 pytorch代�混合 使用,也可以�独 使用�里的 Embedding
Text Preprocess Index Embed Encode Decode Train �建模型 class Bi. LSTMMLP(nn. Module): def __init__(self, init_embed, num_classes, hidden_dim=256, num_layers=1, nfc=128): super(Bi. LSTMSentiment, self). __init__() self. embed = init_embed self. lstm = LSTM(input_size=self. embedding_dim, hidden_size=hidden_dim, num_layers=num_layers, bidirectional=True) self. mlp = MLP(size_layer=[hidden_dim* 2, nfc, num_classes]) fast. NLP的embedding def forward(self, words): 与pytorch的module可 x_emb = self. embed(words) output, _ = self. lstm(x_emb) 以直接嵌入使用 output = self. mlp(torch. max(output, dim=1)[0]) return {C. OUTPUT: output} model = Bi. LSTMMLP(glove_embed, 3) model = Bi. LSTMMLP(elmo_embed, 3) # 使用elmo model = Bi. LSTMMLP(bert_embed, 3) # 使用Bert model = Bi. LSTMMLP(stack_embed, 3) # 使用多种embedding
Text Preprocess Index Embed Encode Decode Train Loss, Metric与Optimizer loss = Cross. Entropy. Loss() metric = Accuracy. Metric() optimizer = Adam(model. parameters(), lr=2 e-3) 参数学� trainer = Trainer(dataset, model, batch_size=32, loss=loss, metrics=metric, optimizer=optimizer) trainer. train()
Text Preprocess Index Embed Encode Decode Train fast. NLP. core. callback ���程中可能需要加入一些 trick,比如learning rate warm-up, gradient clipping, 或者tensorboard�����程等。 on_train_begin() on_epoch_begin() on_batch_begin() callback可以通�����的方法 来在���程中某个�点做相� 的操作。 ���程是可以定制化的。 on_loss_begin() on_backward_end() on_batch_end() on_valid_begin() on_valid_end() on_epoch_end() on_train_end()
Text Preprocess Index Embed Encode Decode Train fas. NLP. core. callback 代�示例 : gradient_clip = Gradient. Clip. Callback(clip_value = 5) # 梯度裁剪 lr_warmup = Warmup. Callback(warmup=0. 1) # 学�率的 warmup callbacks = [gradient_clip, lr_warmup] trainer = Trainer(dataset, model, batch_size=32, loss=loss, metrics=metric, optimizer=optimizer, callbacks=callbacks) trainer. train()
Text Preprocess Index Embed Encode Decode Train 所有代� dataset = Data. Set() with open('. . /test. txt', 'r') as f: for line in f: if line: parts = line. strip(). split('t') dataset. append(Instance(raw_words=parts[0], target=parts[1])) dataset. raw_words. split() dataset. set_input('words') dataset. set_target('target’) model = Model(stack_embed, 3) # 使用多种embedding vocab = Vocabulary(). from_dataset(dataset, field_name='raw_words') vocab. index_dataset(dataset, field_name='raw_words', new_field_name='words') loss = Cross. Entropy. Loss() metric = Accuracy. Metric() optimizer = Adam(model. parameters(), lr=2 e-3) target_vocab = Vocabulary(padding=None, unknown=None). from_dataset( dataset, field_name='target') vocab. index_dataset(dataset, field_name='target', new_field_name='target’) gradient_clip = Gradient. Clip. Callback(clip_value = 5) # 梯度裁剪 lr_warmup = Warmup. Callback(warmup=0. 1) # 学�率的 warmup callbacks = [gradient_clip, lr_warmup] glove_embed = Static. Embedding(vocab, model_dir_or_name='en-glove-6 b-50') elmo_embed = Elmo. Embedding(vocab, model_dir_or_name='en-original') stack_embed = Stack. Embedding([glove_embed, elmo_embed]) trainer = Trainer(dataset, model, batch_size=32, loss=loss, metrics=metric, optimizer=optimizer, callbacks=callbacks) trainer. train() class Bi. LSTMMLP(nn. Module): def __init__(self, init_embed, num_classes, hidden_dim=256, num_layers=1, nfc=128): super(Bi. LSTMSentiment, self). __init__() self. embed = init_embed self. lstm = LSTM(input_size=self. embedding_dim, bidirectional=True, hidden_size=hidden_dim, num_layers=num_layers, ) self. mlp = MLP(size_layer=[hidden_dim* 2, nfc, num_classes]) def forward(self, words): x_emb = self. embed(words) output, _ = self. lstm(x_emb) output = self. mlp(torch. max(output, dim=1)[0]) return {C. OUTPUT: output}
Bi. LSTM+CRF 模型�构 : 复 W 1 h 1 label 旦 W 2 h 2 label 大 W 3 h 3 label 学 W 4 h 4 label input embedding encoder module Bi. LSTM CRF decoder module
在fast. NLP中用做中文序列�注�共需要几步 ? data_bundle = Chinese. NERLoader(). process('MSRA-NER/') char_embed = Static. Embedding(data_bundle. vocabs['chars'], model_dir_or_name='cn-char') bi_embed = Static. Embedding(data_bundle. vocabs['bigrams'], model_dir_or_name='cn-bigram') model = CNBi. LSTMCRFNER(char_embed, num_classes=len(data_bundle. vocabs['target']), bigram_embed= bi_embed) Trainer(data_bundle. datasets['train'], model, loss=None, batch_size=32, metrics=Span. FPre. Rec. Metric(data_bundle. vocabs['target'], encoding_type='bioes'), num_workers=1, dev_data=data_bundle. datasets['dev'], device=0). train()
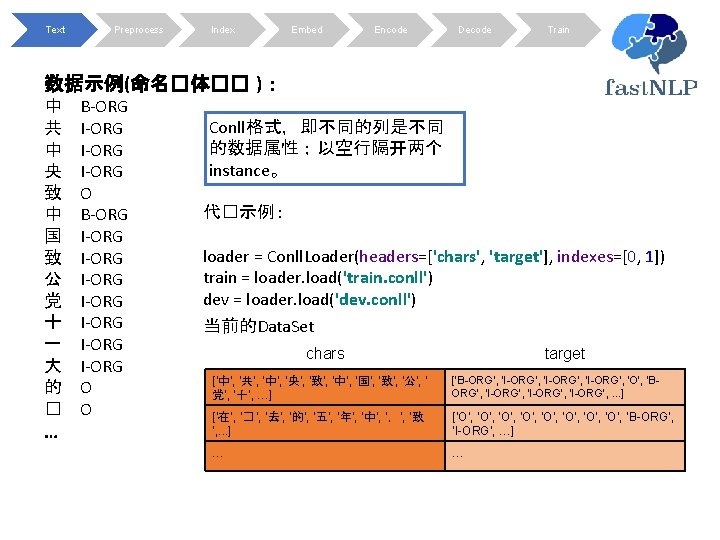
Text Preprocess Index Embed Encode Decode Train def generate_bigram(instance): chars = instance['chars'] next_chars = chars[1: ] + ['<eos>'] bigrams = [c 1+c 2 for c 1, c 2 in zip(chars, next_chars)] return bigrams for dataset in [train, dev]: # 将tag从BIO�型�� BIOES dataset. apply_field(lambda tags: iob 2 bioes(tags), field_name='target’, new_field_name='target') # 增加一个bigram dataset. apply(generate_bigram, new_field_name='bigrams') # 增加一列表示序列的�度 dataset. add_seq_len('chars') chars target bigrams seq_len ['中', '共', '中', '央', '致', '中', ' 国', '致', '公', '党', ‘十‘, …] ['B-ORG', ‘I-ORG', 'I-ORG', ‘EORG', 'O', 'B-ORG', . . . ] [‘中共’, ‘共中’, ‘中央’, ‘央致’, ‘ 致中’, ‘中国', ‘国致', …] 40 [‘在’, ‘� ’, ‘去’, ‘的’, ‘五’, ‘年’, ‘ 中’, ‘,’, ‘致‘, . . . ] [‘O’, ‘O’, ‘B-ORG’, ‘I-ORG‘, …] [‘在� ’, ‘�去 ’, ‘去的’, ‘的五’, ‘ 五年’, ‘年中’, ‘中,’, . . . ] 23 … …
Text Preprocess Index Embed Encode Decode Train # 建立�表,�� index vocabs = {} for field_name in [‘chars’, ‘bigrams’]: vocabs[field_name] = Vocabulary(). from_dataset(train, field_name=field_name) vocabs[field_name]. index_dataset(train, dev, field_name=field_name) target_vocab = Vocabulary(padding=None, unknown=None). from_dataset(train, field_name='target') target_vocab. index_dataset(train, field_name='target’) Index之后的Data. Set chars target bigrams seq_len [9, 226, 9, 467, 518, 9, 5, 518, 75, 167, 179, 6, 15, …] [4, 1, 1, 5, 0, 4, 1, 1, 1, 5, 0, 0, 0, …] [1026, 1735, 93, 64482, 88303, 3, 30021, 12881, …] 40 [0, 0, 4, 1, 5, 0, 8, 7, 9, …] [0, 0, 4, 1, 5, 0, 8, 7, 9, 0, …] [6183, 653, 3059, 6868, 4826, 2695, 47, 4621, 12881, . . ] 23 … …
Text Preprocess Index Embed Encode Decode Train # 随机初始化两个embedding char_embed = Static. Embedding(char_vocab, model_dir_or_name='cn-char') bigram_embed = Static. Embedding(bigram_vocab, model_dir_or_name=‘cn-bigram') # �建模型, Bi. LSTM+CRF class CNBi. LSTMCRFNER(nn. Module): def __init__(self, char_embed, bigram_embed, tag_vocab , encoding_type='bioes'): super(). __init__() self. char_embed = char_embed self. bigram_embed = bigram_embed self. lstm = LSTM(self. char_embed_dim+self. bigram_embed_dim, 50, num_layers=1, bidirectional=True, batch_first=True) self. fc = nn. Linear(100, len(tag_vocab)) allowed_trans = allowed_transitions(tag_vocab. idx 2 word, encoding_type= encoding_type, include_start_end=True) self. crf = Conditional. Random. Field(len(tag_vocab), include_start_end_trans=True, allowed_transitions=allowed_trans)
Text Preprocess Index Embed Encode Decode def forward(self, chars, bigrams, seq_len, target=None): chars = self. char_embed(chars) bigrams = self. bigram_embed(bigrams) chars = torch. cat((chars, bigrams), dim=-1) feats, _ = self. lstm(chars, seq_len) logits = F. log_softmax(self. fc(feats), dim=-1) mask = seq_len_to_mask(seq_len) if target is None: pred, _ = self. crf. viterbi_decode(logits, mask) return {‘pred’: pred} else: loss = self. crf(logits, target, mask). mean() return {'loss': loss} model = CNBi. LSTMCRFNER(char_embed, bigram_embed, target_vocab) Train
Text Preprocess Index Embed Encode Decode Train # �置�入与目� train. set_input('chars', 'bigrams', 'seq_len', 'target') dev. set_input('chars', 'bigrams', 'seq_len') dev. set_target('target') trainer = Trainer(train, model, batch_size=32, dev_data=dev, sampler= Bucket. Sampler(), metrics=Span. FPre. Rec. Metric(target_vocab, encoding_type='bioes')) trainer. train()
Data. Set. Loader conll 2003 Onte. Notes NER ��多种任�的数据��理。 MSRA-NER SNLI 从Data. Set. Loader中�取�入的数 据即可�行��和��。 data_bundle = Conll 2003 Data. Loader(). process('c onll 2003/') print(data_bundle) Conll 2003: In total 3 datasets: train has 14041 instances. dev has 3250 instances. test has 3453 instances. In total 2 vocabs: words has 30291 entries. target has 17 entries. MNLI RTE Matching QNLI Quora Yelp_p Yelp_f Text classification sst-2 IMDB CNN/Daily. Mail Newsroom Summarization The New York Times Annotated Corpus DUC …
Model char_cnn Elmo NER Bert 提供多种模型的��参考。 以上的模型,我�都会尽力�� 到�文所�道的 performance。 ESIM CNTN DIIN Matching Mw. AN … char_cnn dpcnn Text classification HAN … LEAD 3 ORACLE Summarization BERTSUM … …
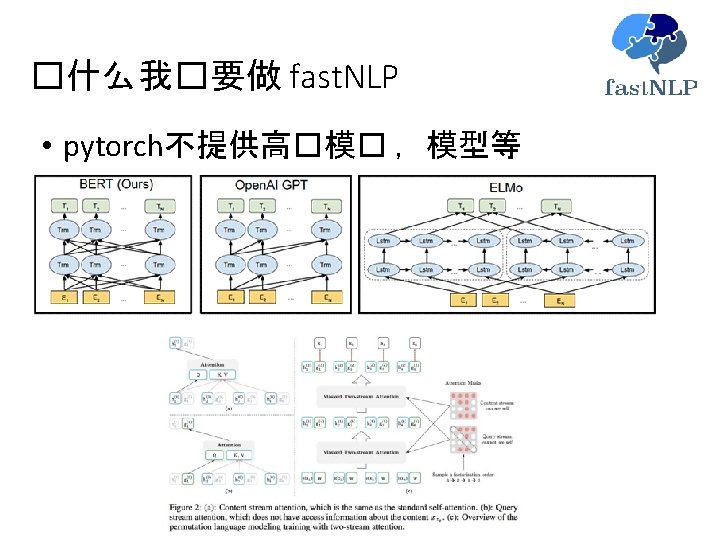
�什么 fast. NLP