Fast and Compact Retrieval Methods in Computer Vision



































 Architecture • Network of binary stochastic units • Hinton &")


")
")
")












- Slides: 54
Fast and Compact Retrieval Methods in Computer Vision Part II • • A. Torralba, R. Fergus and Y. Weiss. Small Codes and Large Image Databases for Recognition. CVPR 2008 A. Torralba, R. Fergus, W. Freeman. 80 million tiny images: a large dataset for non-parametric object and scene recognition. TR Presented by Ken and Ryan
Outline • Large Datasets of Images • Searching Large Datasets – Nearest Neighbor – ANN: Locality Sensitive Hashing • Dimensionality Reduction – Boosting – Restricted Boltzmann Machines (RBM) • Results
Goal • Develop efficient image search and scene matching techniques that are fast and require very little memory • Particularly on VERY large image sets Query
Motivation • Image sets – Vogel & Schiele: 702 natural scenes in 6 cat – Olivia & Torralba: 2688 – Caltech 101: ~50 images/cat ~ 5000 – Caltech 256: 80 -800 images/cat ~ 30608 • Why do we want larger datasets?
Motivation • Classify any image • Complex classification methods don’t extend well • Can we use a simple classification method?
Thumbnail Collection Project • Collect images for ALL objects – List obtained from Word. Net – 75, 378 non-abstract nouns in English
Thumbnail Collection Project • Collected 80 M images • http: //people. csail. mit. edu/torralba/tinyimages
How Much is 80 M Images? • One feature-length movie: – 105 min = 151 K frames @ 24 FPS • For 80 M images, watch 530 movies • How do we store this? – 1 k * 80 M = 80 GB – Actual storage: 760 GB
First Attempt • Store each image as 32 x 32 color thumbnail • Based on human visual perception • Information: 32*32*3 channels =3072 entries
First Attempt • Used SSD++ to find nearest neighbors of query image – Used first 19 principal components
Motivation Part 2 • • Is this good enough? SSD is naïve Still too much storage required How can we fix this? – Traditional methods of searching large datasets – Binary reduction
Locality-Sensitive Hash Families
LSH Example
Binary Reduction Gist vector Lots of pixels Binary reduction 80 million images? 164 GB 320 MB 512 values 32 bits
Gist “The ‘gist’ is an abstract representation of the scene that spontaneously activates memory representations of scene categories (a city, a mountain, etc. )” A. Oliva and A. Torralba. Modeling the shape of the scene: a holistic representation of the spatial envelope. Int. Journal of Computer Vision, 42(3): 145– 175, 2001.
Gist
Gist vector http: //ilab. usc. edu/siagian/Research/Gist. html
Querying Query Image Dataset
Querying » ? 1
Querying » ? 6
Querying
Boosting • Positive and negative image pairs train the discovery of the binary reduction. 150 K pairs 80% negatives & =1 & = -1
Boost. SSC xi • Similarity Sensitive Coding • Weights start uniformly N values Weight
Boost. SSC Feature vector x from image i n • For each bit m: – Choose the index n that minimizes a weighted error across entire training set Binary reduction h(x) m N values M bits
Boost. SSC • Weak classifications are evaluated via regression stumps: n xi xj If xi and xj are similar, we should get 1 for most n’s. • We need to figure out a, b, and T for each n. N values
Boost. SSC n n n xi xj • Try a range of threshold T: – Regress f across entire training set to find each a and b. – Keep the T that fits the best. • Then, keep the n that causes the least weighted error. N values
Boost. SSC xi xj m n N values M bits
Boost. SSC xi xj • Update weights. – Affects future error calculations n N values Weight
Boost. SSC • In the end, each bit has an n index and a threshold. xi M bits N values
Boost. SSC
Restricted Boltzmann Machine (RBM) Architecture • Network of binary stochastic units • Hinton & Salakhutdinov, Nature 2006 Parameters: w: b: h: v: Symmetric Weights Biases Hidden Units Visible Units
Multi-Layer RBM Architecture
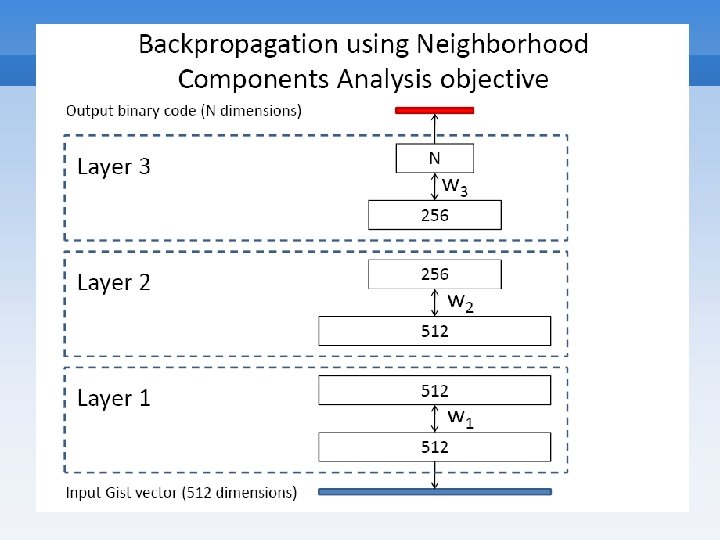
Training RBM Models • Two phases 1. Pre-training • Unsupervised • Use Contrastive Divergence to learn weights and biases • Gets parameters in the right ballpark 2. Fine-tuning • Supervised • No longer stochastic • Backpropogate error to update parameters • Moves parameters to local minimum
Greedy Pre-training (Unsupervised)
Greedy Pre-training (Unsupervised)
Greedy Pre-training (Unsupervised)
Neighborhood Components Analysis • Goldberger, Roweis, Salakhutdinov & Hinton, NIPS 2004 Output of RBM W are RBM weights
Neighborhood Components Analysis • Goldberger, Roweis, Salakhutdinov & Hinton, NIPS 2004 Assume K=2 classes
Neighborhood Components Analysis • Goldberger, Roweis, Salakhutdinov & Hinton, NIPS 2004 Pulls nearby points of same class closer
Neighborhood Components Analysis • Goldberger, Roweis, Salakhutdinov & Hinton, NIPS 2004 Pulls nearby points of same class closer Goal is to preserve neighborhood structure of original, high-dimensional space
Experiments and Results
Searching • Bit limitations: – Hashing scheme: • Max. capacity for 13 M images: 30 bits – Exhaustive search: • 256 bits possible
Searching Results
Label. Me Retrieval
Examples of Web Retrieval • 12 neighbors using different distance metrics
Web Images Retrieval
Conclusion • Efficient searching for large image datasets • Compact image representation • Methods for binary reductions – Locality-Sensitive Hashing – Boosting – Restricted Boltzmann Machines • Searching techniques