Exchange 2003 Exchange 201020132016 Shared infrastructure with redundant


















 is redundancy of solution components within a datacenter Site Resilience (SR)")

 §")


 Database")
 disks for system partition (OS; Exchange binaries, transport queues, logs)")







 in each DAG split symmetrically between two")



- Slides: 41
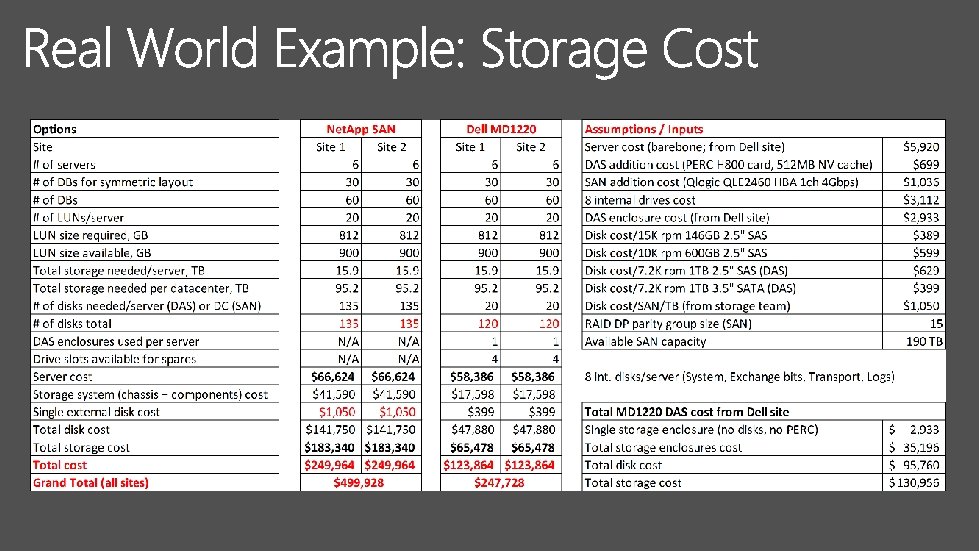
Exchange 2003 Exchange 2010/2013/2016 Shared infrastructure with redundant hardware components Commodity building blocks with software controlled redundancy New architecture and design principles How much disk performance Exchange database needs? I/O Meter
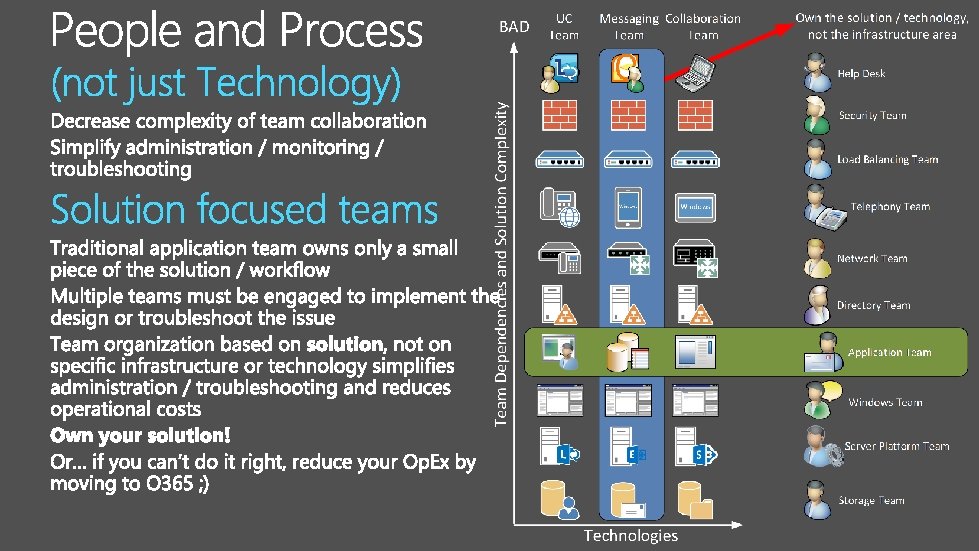
In modern Exchange world software, not hardware, powers and controls the solution Reduce complexity, simplify the solution Decrease the number of system dependencies to improve availability and lower the risks Use native capabilities where possible as it makes the design simpler Deploy redundant solution components to increase availability and protect the solution Avoid failure domains: do not group redundant solution components into blocks that could be impacted by a single failure Enable and enhance user experience Provide functionality and access that is required or expected by the end users Provide large low cost mailboxes Use Exchange as a single data repository Increase value with Lync and Share. Point integration Build a bridge to the cloud – ensure feature rich cloud integration and co-existence Optimize People and Process, not just Technology Decrease complexity of team collaboration by leveraging solution / workload focused teams Simplify / optimize administration / monitoring / troubleshooting process Reduce / minimize total cost of the ownership (TCO) for the solution Use commodity hardware and leverage native product capabilities Implement storage solution that minimizes cost, complexity, and administrative overhead
Failures *do* happen! Critical system dependencies decrease availability Deploy Multi-role servers Avoid intermediate and extra components (e. g. SAN; network teaming; archiving servers) Simpler design is always better: KISS Redundant components increase availability Multiple database copies Multiple balanced servers Failure domains combining redundant components decrease availability Examples: SAN; Blade chassis; Virtualization hosts Software, not hardware is driving the solution Exchange powered replication and managed availability Redundant transport and Safety Net Load balancing and proxying to the destination Availability principles: DAG beyond the “A” http: //blogs. technet. com/b/exchange/archive/2011/09/16/dag-beyond-the-a. aspx
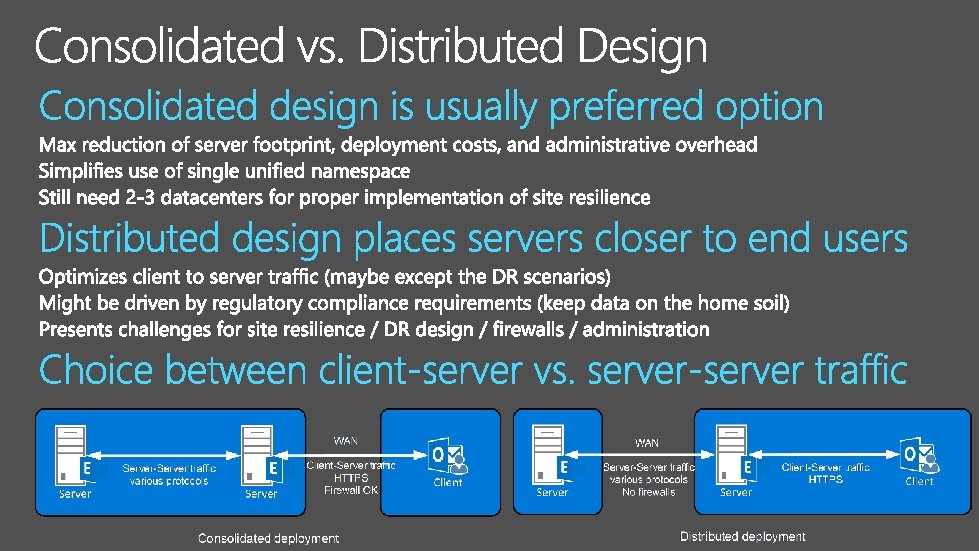
Classical shared infrastructure design introduces numerous critical dependency components Relying on hardware requires expensive redundant components Failure domains reduce availability and introduce significant extra complexity
Scale the solution out, not in; more servers mean better availability Nearline SAS storage: provide large mailboxes by using large low cost drives Exchange I/O reduced by 93% since Exchange 2003 Exchange 2013/2016 database needs ~10 IOPS; single Nearline SAS disk provides 70+ IOPS; single 2. 5” 15 K rpm SAS disk provides 230+ IOPS 3+ redundant database copies eliminate the need for RAID and backups Redundant servers eliminate the need for redundant server components (e. g. NIC teaming or MPIO)
Google, Microsoft, Amazon, Yahoo! use commodity hardware for 10+ years already Not only for messaging but for other technologies as well (started with search, actually) Inexpensive commodity server and storage as a building block Easily replaceable, highly scalable, extremely cost efficient Software, not hardware is the brain of the solution Photo Credit: Stephen Shankland/CNET
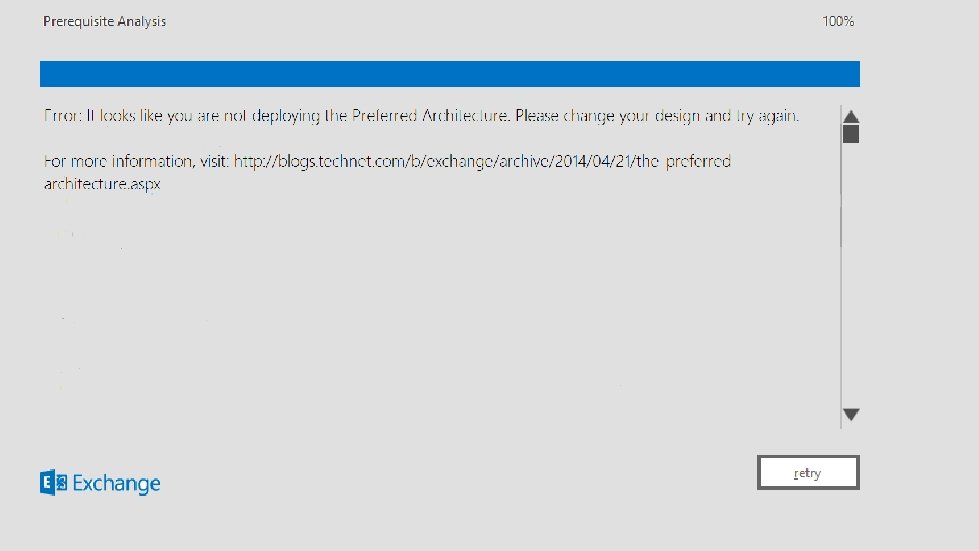
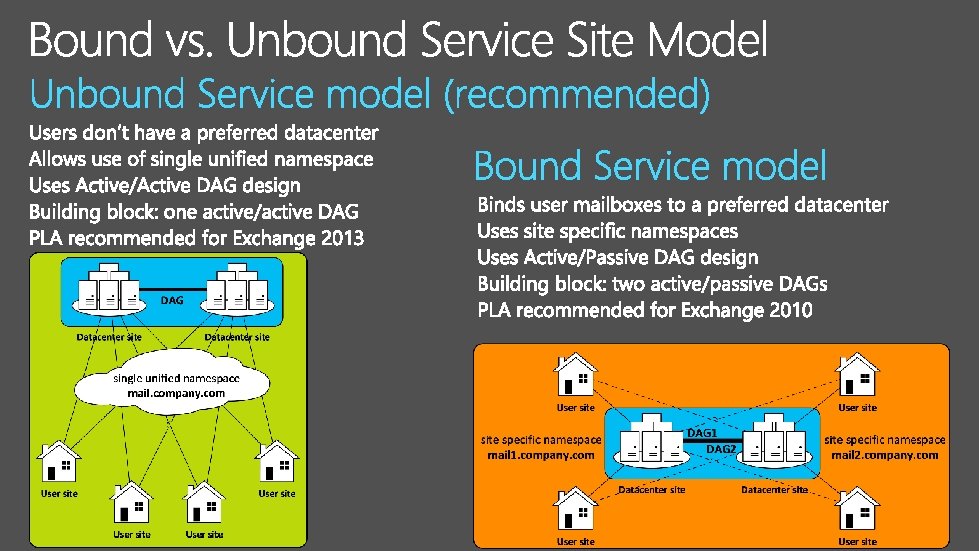
Exchange Preferred Architecture: reference architecture from Exchange product group Exchange Product Line Architecture: Tightly scoped reference architecture offering from Microsoft Consulting Services Based on deployment best practices and customer experience Structured design based on detailed rule sets to avoid common mistakes and misconceptions Follows cornerstone design principles: § § § § § 4 database copies across 2 sites; witness in 3 rd site Unbound Service Site model (single namespace) Multi-role servers DAS storage with NL SAS or SATA JBOD L 7 load balancing (no session affinity) Large low cost mailboxes (25/50 GB standard mailbox size) Enable access for all internal / external clients System Center for monitoring Exchange Online Protection for messaging hygiene http: //blogs. technet. com/b/exchange/archive/2014/04/21/the-preferred-architecture. aspx
DAG size is important because DAG is the building block General guidance is to prefer larger DAG size Larger DAGs provide better availability and load balancing § § Larger DAGs, however, have disadvantages too § § http: //aka. ms/partitioned-cluster-networks § Scalability planning due to growth also impacts the decision §
Stretching your DAG Don’t multiply complexities http: //aka. ms/partitioned-cluster-networks
Still itching to use three sites? How are the users connected? With CAS role decoupled from MBX (logically! Not physically) it doesn’t matter… unless…
Goal: Provide symmetric database copy layout to ensure even load distribution http: //blogs. technet. com/b/exchange/archive/2010/09/10/3410995. aspx Server 3 Failure Server 6 Failure
New capability in Exchange 2013: DAG without a Cluster Administrative Access Point (a. k. a. IP-less DAG) http: //blogs. technet. com/b/scottschnoll/archive/2014/02/25/database-availability-groups-and-windows-server-2012 -r 2. aspx http: //blogs. technet. com/b/timmcmic/archive/2015/04/29/my-exchange-2013 -dag-has-gone-commando. aspx Recommended and preferred model, default in Exchange 2016 Advantages: reduced complexity § § § Disadvantages: § § Useful Powershell cmdlets: Get-Cluster -Name DAG 01 | select * Get-Cluster. Node -Cluster DAG 01 [-Name SVR 01] | select * Get-Cluster. Network -Cluster DAG 01 [-Name DAGNetwork 01] | select * Get-Cluster. Quorum -Cluster DAG 01 | fl Get-Cluster. Group -Cluster DAG 01 Move-Cluster. Group -Cluster DAG 01 -Name "Cluster Group" -Node SVR 01 Get-Cluster. Log –Cluster DAG 01
High Availability (HA) is redundancy of solution components within a datacenter Site Resilience (SR) is redundancy across datacenters providing a DR solution Both HA and SR are based on native Exchange data replication Each database exists in multiple copies, one of them active Data is shipped to passive copies via transaction log replication over the network It is possible to use dedicated isolated network for Exchange data replication Network requirements for replication: Each active passive database replication stream generates X bandwidth The more database copies, the more bandwidth is required Exchange natively encrypts and compresses replication traffic Pros and cons for dedicated replication network => Not recommended Replication network can help isolating client traffic from replication traffic Replication network must be truly isolated along the entire data transfer path: having separate NICs but sharing the network path after the first switch is meaningless Replication network requires configuring static routes and eliminating cross talk; this leads to extra complexity and increases risk of human error If server NICs are 10 Gbps capable, it’s easier to have a single network for everything No need for network teaming: think of a NIC as JBOD
SAN DAS FC SAS SATA § § § § § RAID JBOD (RBOD) § §
Conceptually similar replication – goal is to introduce redundant copy of the data Software, not hardware powered Application aware replication Enables each server and associated storage as independent isolated building block Exchange 2013 is capable of automatic reseed using hot spare (no manual actions besides replacing the failed disk!) Finally, cost factor: RAID 1/0 requires 2 x storage (you still want 4 database copies for Exchange availability)!
Exchange mailboxes will grow but they don’t consume that much on Day 1 The desire not to pay for full storage capacity upfront is understood However, inability to provision more storage and extend capacity quickly when needed is a big risk Successful thin provisioning requires significant operational maturity and process excellence unseen in the wild Microsoft guidance and best practice is to use thick provisioning with low cost storage Incremental provisioning model can be considered a reasonable compromise
Exchange continuous replication is a native transactional replication (based on transaction data shipping) Database itself is not replicated (transaction logs are played back to target database copy) Each transaction is checked for consistency and integrity before replay (hence physical corruption cannot propagate) Page patching is automatically activated for corrupted pages Replication data stream can be natively encrypted and compressed (both settings configurable, default is cross site only) In case of data loss Exchange automatically reseeds or resynchronizes the database (depending on type of loss) If hot spare disk is configured, Exchange automatically uses it for reseeding (like RAID rebuild does)
Two mirrored (RAID 1) disks for system partition (OS; Exchange binaries, transport queues, logs) One hot spare disk Nine or more RBOD disks (single disk RAID-0) for Exchange databases with collocated transaction logs Four database copies collocated per disk, not to exceed 2 TB database size
There are servers that can house more than 12 LFF disks (up to 16 with rear bay) There already DAS enclosures available that provide 720 TB capacity in a single 4 U unit (90 x 8 TB drives)! Scalability limits: still 100 database copies / server This means no more than 25 drives @ 4 databases/disk or 50 drives @ 2 databases/disk
Exchange Native Data Protection: 3+ highly available database copies Lagged copy to protect from unlikely scenarios (logical corruption, admin error) Replay Lag Manager with automatic copy conversion What will you do with your tapes? Self Service Recovery to restore items from Recoverable Items – Deletions Single Item Recovery to protect items in Recoverable Items and restore them administratively via mailbox search Large mailboxes can accommodate large “dumpster” – no need for archive mailbox or 3 rd party archiving
Introduces additional critical solution component complexity and overhead Uses shared infrastructure concept and brings failure domains Consolidated roles is a guidance since Exchange 2010 – and now there is only a single role in Exchange 2016! Deploying multiple Exchange servers on the same host would create failure domain Hypervisor powered high availability is not needed with proper Exchange DAG designs No real benefits from Virtualization as Exchange provides equivalent benefits natively at the application level Could still make sense for small deployments helping consolidate workloads – but be careful with failure domains!
10+ years ago archiving enabled offloading Exchange data to the lower cost storage With large mailboxes on commodity storage it does not make sense anymore Single data repository is better than multiple solutions and lots of PST files There’s still in-place archive a. k. a. online archive which is just a second mailbox available in online mode Only needed based on client performance considerations or when you cannot extend mailbox capacity Outlook 2013+ has the magic slider = no impact from large OST file 1 K 20 K 100 K 1 M items in critical path folders (client has impact too) – are you stubbing? Retention is to help users delete their data when it is no longer needed Retention tags and retention policies Compliance is to prevent users from deleting sensitive data that might be requested by legal Litigation Hold, In-Place Hold to protect and preserve data at rest (in the mailbox) Data Loss Prevention (DLP) to protect data in transit Unified Compliance Center to combine Exchange/Lync and Share. Point together for e. Discovery
In today’s world, users access Exchange mailboxes from many clients and devices Cumulative client concurrency can be over 100% Penalty factors are measured in units of load created by a single Outlook client Some clients generate more server load than a baseline Outlook client Penalty factor should be calculated as weighted average across all types of clients Individual penalty factors are provided for illustration purpose only and should be adjusted based on internal test results, client configurations, vendor guidance and other relevant factors Penalty factor for BES 5 is based on performance benchmarking guide published by Blackberry at http: //aka. ms/bes 5 performance Penalty factor for Good is based on data published on Good Portal at http: //aka. ms/goodperformance Continue to monitor system utilization closely and adjust sizing model as necessary as you scale out
Four or more physical servers (collocated roles) in each DAG split symmetrically between two datacenter sites Four database copies (one lagged with lag replay manager) for HA and SR on DAS storage with JBOD; minimized failure domains Unbound Service site model with single unified load balanced namespace and Witness in the 3 rd datacenter
§ § § § There are many Exchange design options in the wild Not everything that is supported is recommended PA formulates cornerstone design principles Exchange On-Premises PLA presents a structured design Custom Design based on strict rules Exchange On-Premises PA/PLA is based on field experience recommended best practices and Office 365 practice Aligning with PA/PLA provides Exchange On-Premises best co-existence with the cloud PA / PLA Design and simplifies Hybrid deployment If you cannot follow the PA principles Exchange Online and PLA rules, you are not mature Public Cloud (Office 365) enough to run Exchange – MOVE TO Office 365!
E-mail: Profile: Social: borisl@microsoft. com https: //www. linkedin. com/in/borisl https: //www. facebook. com/lokhvitsky