EPIC Architecture Explicitly Parallel Instruction Computing Yangyang Wen
 Yangyang Wen CDA 5160 --Advanced Computer Architecture I")















![Introducing the Token Bit IA-64 ld. s r 8=a[ ] instr 1 instr 2](https://slidetodoc.com/presentation_image_h2/25734a0e470573e577b74caaf27ce2c7/image-18.jpg "Introducing the Token Bit IA-64 ld. s r 8=a[ ] instr 1 instr 2")




![Software Pipelining Example For(I=0; I<1000; I++) x[I]=x[I]+s; Loop: Ld f 0, 0(r 1) Add](https://slidetodoc.com/presentation_image_h2/25734a0e470573e577b74caaf27ce2c7/image-23.jpg "Software Pipelining Example For(I=0; I<1000; I++) x[I]=x[I]+s; Loop: Ld f 0, 0(r 1) Add")





- Slides: 28
EPIC Architecture (Explicitly Parallel Instruction Computing) Yangyang Wen CDA 5160 --Advanced Computer Architecture I University of Central Florida
Outline l What is EPIC? l EPIC Philosophy l Architectural Features Supporting EPIC l Intel’s IA-64 Architectural Features l IA-64’s Key Technologies l Summary and Reference
Traditional Architectures: Limited Parallelism Original Source Code Sequential Machine Hardware Code Compiler parallelized code multiple functional units Execution Units Available the execution units are not used efficiently Today’s Processors often 60% Idle
EPIC Architecture: Explicit Parallelism Original Source Code Better Parallel machine Code Compiler EPIC Compiler Views Wider Scope Hardware Get more efficient use of execution resources Increases Parallel Execution multiple functional units . . .
What is EPIC ? EPIC means Explicitly Parallel Instruction computing, and EPIC architecture provides features that allow compilers to take a proactive role in enhancing Instruction level parallelism( ILP) without unacceptable hardware complexity.
EPIC’s Performance
EPIC Design Philosophy l EPIC permits the compiler have advanced features to enhance ILP: predication, speculation. l EPIC can design the plan of execution (POE) at compile-time and communicate the POE to the hardware. l EPIC must have massive hardware resources for parallel execution
Introducing IA-64 l IA-64 comes from Intel and is the first 64 -bit architecture for Intel. l The first instance of a commercially available EPIC ISA. l The first architecture to bring ILP features to general-purpose microprocessors.
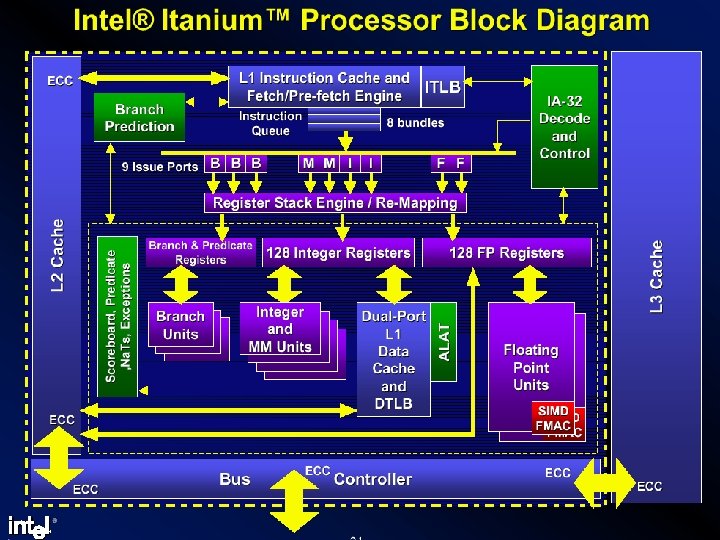
IA-64’s Architectural Basics l l l l Explicit Parallelism Enhanced ILP Compiler-oriented Extremely large physical memory A huge virtual address space for applications 64 -bit computation Extremely large register files
IA-64’s Key Technologies l Instructions Bundling l Predication l Control Speculation l Data Speculation l Software pipelining
Instruction Bundling 128 -bit bundle 41 -bits 127 Insrtruction 2 Instruction 1 0 Instruction 0 Template Uses a form of VLIW architecture l Three Instructions are combined into a 128 -bit instruction l Parallel Instructions are executed in groups l Template bits decode and route instructions and mark the end of groups of parallel instructions. l
ILP Bottlenecks l Branches – Deal with branch, take predication. – Branch mispredications cause 20% to 30% loss in processor performance. l Memory latency – Latency is the time it takes to get data from memory. The longer it takes you to access memory to get code and data, the longer the CPU sits idle. – For memory latency, it's the loads that are the big problem, not the stores.
Predication If A>B S+=A else S+=B end if If A>B Predicate S+=A The predication is wrong Throw away S+=A S+=B *P=S S+=B (a) Traditional predication Branching is a major cause of lost performance. (b) IA-64 predication
EPIC Predication Process Branch Candidate Instructions are marked with ID Instructions are packed into bundles Processor executes both paths in parallel Compiler finds what insts to execute in parallel Processor checks predication and stores correct results
Predication Benefits l Reduce branches l Reduce mispredication penalties l Reduce critical paths
Control Speculation Traditional Architectures instr 1 instr. . . 2 br Barrier Load a[ ] use Elevating the load above a branch is not possible IA-64 Architectures ld. s r 8=a[ ] instr 1 instr 2 br chk. s r 8 use Allows elevation of load, even above a branch Memory latency is a major performance bottleneck
Introducing the Token Bit IA-64 ld. s r 8=a[ ] instr 1 instr 2 br chk. s r 8 use ; Exception Detection Propagate Exception ; Exception Delivery When elevate ld, give an exception detection l If the load address is valid, it’s normal. l If the load address is invalid, compiler sets token bit , and jumps out of this path. l If the code goes to chk. s, and the chk. s detects the token bit, jumps to fix-up code, executes the load. l
Data Speculation Traditional Architectures instr 1 instr 2. . . store IA-64 ALAT Barrier load use Can’t elevate the load, so prevents from reordering insts Chk. a load. a instr 1 instr 2 store load. c use Allows the compiler to elevate the load , even it isn’t sure if the memory reference overlaps.
Advanced Load Address Table: ALAT ld. a reg# =. . . chk. a reg#? reg # Address reg #. . . Address store l. When ALAT elevate ld. a, insert l. When store, remove overlap address records in ALAT l. When chk. a, if no address is found , there is a conflict, and jumps to fix-up code to reexecute the code
Speculation Benefits l Reduces impact of memory latency l Study demonstrates performance improvement of 80% when combined with predication l Greatest improvement to code with many cache accesses l Scheduling flexibility enables new levels of performance headroom
Software Pipelining vs. • Overlap the execution of different loop iterations • Get more iterations in same amount of time
Software Pipelining Example For(I=0; I<1000; I++) x[I]=x[I]+s; Loop: Ld f 0, 0(r 1) Add f 0, f 1 Sd f 0, 0(r 1) Add r 1, 8 Subi r 2, 1 Benz loop Loop: SD Add Subi Ld Benz f 2, -4(r 1) f 2, f 0, f 1 r 2, 1 f 0, 4(r 1) loop Software pipelining
Software Pipelining Advantages l Traditionally performed through loop unrolling l less code compared loop unrolling, increased regularity l Smaller code means fewer cache misses l Especially useful for integer code with small number of loop iterations
Software Pipelining disadvantages l. Requires many additional instructions to manage the loop l. Without hardware support the overhead may greatly increase code size ltypically only used in special technical computing applications
IA-64 Features Supporting Software Pipelining l Full predication l Circular Buffer of General and FP Registers l Loop Branches Decrement RRBs (register rename bases)
Summary l Predication removes branches – Parallel compares increase parallelism – Benefits complex control flow: large databases l Speculation reduces memory latency impact – IA-64 removes recovery from critical path – Benefits applications with poor cache locality: server applications, OS l S/W pipelining support with minimal overhead enables broad usage – Performance for small integer loops with unknown trip counts as well as monster FP loops
Reference l M. S. Schlanker, "EPIC: Explicitly Parallel Instruction Computing", Computer, vol. ? , No. ? , pp 37 --45, 2000. l Jerry Huck et al. , "Introducing the IA-64 Architecture", Sept - Oct. 2000, pp. 12 -23 l Carole Dulong “The IA-64 Architecture at Work”, Computing Practices