Emergence of GPU systems for general purpose high






 By late 1990’s, graphics")
 From GPU Gems 2, Copyright")
 floating point operations. People")
 Brief History GPU Computing General-purpose computing on graphics processing units")
")
 First GPU for high performance computing")
 • Data parallel single instruction")

 GK 104 chip with 1536 cores A lot")

 • 14")
 • 13 streaming multiprocessor (SMXs, extreme) •")
 • Architecture and programming model introduced in NVIDIA in")

- Slides: 21
Emergence of GPU systems for general purpose high performance computing ITCS 4145/5145 © Barry Wilkinson GPUIntro. ppt Nov 4, 2013
Titan Supercomputer Oak Ridge National Laboratory in Oak Ridge, Tenn World’s fastest computer on TOP 500 list Nov 2012 – May 2013 Down to No 2 June 2013* 18, 688 NVIDIA Tesla K 20 X GPUs (each having 2688 cores) 20 petaflops Upgraded from Jaguar supercomputer. 10 times faster and 5 times more energy efficient than 2. 3 petaflops Jaguar system while occupying the same floor space. http: //nvidianews. nvidia. com/Releases/NVIDIA-Powers-Titan-World-s-Fastest-Supercomputer-For-Open-Scientific-Research-8 a 0. aspx#source=pr 2 No 1: Tianhe-2 (Milky. Way-2) – 3, 120, 000 cores (Intel Xeon E 5 -2692 with Intel Xeon Phi coprocessors)
Tesla K 20 GPU Computing modules Kepler architecture. Introduced November 2012 K 20 – 2496 thread processors (cores) K 20 X – 2688 thread processors (cores) 2013: K 40 – 2880 thread processors K 20 2496 FP 32 cores, 832 FP 64 cores Wattage 225 watts GFLOPs: Single Precision: 3519 - 4106 Double Precision: 1173 3
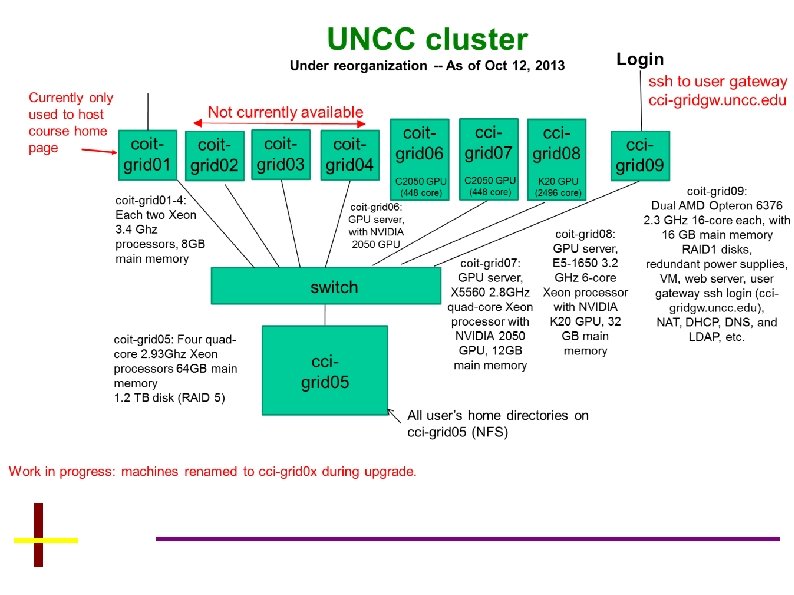
UNC-C CUDA Teaching Center 2010: NVIDIA Corp. selected UNCCharlotte Department of Computer Science to be a CUDA Teaching Center, kindly providing GPU equipment and TA support. Donated C 2050 used in coit-grid 06 2011: NVIDIA kindly provided 50 GTX 480 GPU cards valued at $15, 000 as continuing support for the CUDA Teaching Center. 2012: NVIDIA donates a K 20, used in cci-grid 08. 2013 NVIDIA Teaching Center status renewed. Our course materials are posted on NVIDIA’s corporate site next to those from Stanford, and other top schools. 4
http: //developer. nvidia. com/cuda-training 5
CPU-GPU architecture evolution 1970 s - 1980 s Co-processors -- very old idea appeared in 1970 s and 1980 s -- floating point coprocessors attached to microprocessors that did not then have floating point capability. Coprocessors simply executed floating point instructions that were fetched from memory. Graphics cards -- Around same time, hardware support for displays, especially with increasing use of graphics and PC games. Led to graphics processing units (GPUs) attached to CPU to create video display. Early designs Co-processor CPU Memory CPU Graphics card Display 7 2013: Xeon Phi processor with 60 cores is described as a co-processor although connected thro a PCIe interface in a similar fashion to recent GPU cards.
Pipelined programmable GPU Dedicated pipeline (late 1990 s-early 2000 s) By late 1990’s, graphics chips needed to support 3 -D graphics, especially for games and graphics. APIs such as Direct. X and Open. GL. Generally had a pipeline structure with individual stages performing specialized operations, finally leading to loading frame buffer for display. Individual stages may have access to graphics memory for storing intermediate computed data. Input stage Vertex shader stage Graphics memory Geometry shader stage Rasterizer stage Frame buffer Pixel shading stage 8
Example -- Ge. Force 6 Series Architecture (2004 -5) From GPU Gems 2, Copyright 2005 by NVIDIA Corporation 9
General-Purpose GPU designs High performance pipelines call for high-speed (IEEE) floating point operations. People tried to use GPU cards to speed up scientific computations Known as GPGPU (General-purpose computing on graphics processing units) -- Difficult to do with specialized graphics pipelines, but possible. ) By mid 2000’s, recognized that individual stages of graphics pipeline could be implemented by a more general purpose processor core (although with a data-parallel paradigm) a 10
Graphics Processing Units (GPUs) Brief History GPU Computing General-purpose computing on graphics processing units (GPGPUs) GPUs with programmable shading Nvidia Ge. Force GE 3 (2001) with programmable shading Direct. X graphics API Open. GL graphics API Hardware-accelerated 3 D graphics S 3 graphics cardssingle chip 2 D accelerator Atari 8 -bit IBM PC Professional Playstation computer Graphics Controller text/graphics chip card 1970 1980 1990 Source of information http: //en. wikipedia. org/wiki/Graphics_Processing_Unit 2000 2010
1993 NVIDIA products Tesla Kepler K 20 GPU has 2496 thread processors Maxwell (2013) C 2050 GPU has 448 thread Kepler processors (2011) NVIDIA Corp. a leader in GPUs for high performance computing: Fermi NVIDIA's first GPU with general purpose processors Established by Jen. Hsun Huang, Chris Malachowsky, Curtis Priem NV 1 1995 Tesla C 870, S 870, C 1060, S 1070, C 2050, … Ge. Force 400 series GTX 460/465/470/475/ 480/485 Quadro GT 80 Ge. Force 200 series Ge. Force 8800 GTX 260/275/280/285/295 Ge. Force 8 series Ge. Force 2 series Ge. Force FX series Ge. Force 1 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010
NVIDIA GT 80 chip/Ge. Force 8800 card (2006) First GPU for high performance computing as well as graphics Unified processors that could perform vertex, geometry, pixel, and general computing operations Could now write programs in C rather than graphics APIs. Single-instruction multiple thread (SIMT) prog. model 13
Evolving GPU design: NVIDIA Fermi architecture (announced Sept 2009) • Data parallel single instruction multiple data operation (“Stream” processing) • Up to 512 cores (“stream processing engines”, SPEs, organized as 16 SPEs, each having 32 SPEs) • 3 GB or 6 GB GDDR 5 memory • Many innovations including L 1/L 2 caches, unified device memory addressing, ECC memory, … • First implementation: Tesla 20 series (single chip C 2050/2070, 4 chip S 2050/2070) 3 billion transistor chip? Number of cores limited by power considerations, C 2050 has 448 cores. * Whitepaper NVIDIA’s Next Generation CUDA Compute Architecture: Fermi, NVIDIA, 2008 14
GPU performance gains over CPUs T 12 GT 200 G 80 G 70 NV 30 NV 40 3 GHz Dual Core P 4 3 GHz Core 2 Duo Source © David Kirk/NVIDIA and Wen-mei W. Hwu, 2007 -2009 ECE 498 AL Spring 2010, University of Illinois, Urbana-Champaign 3 GHz Xeon Quad Westmere 15
NVIDIA Kepler architecture and GPUs (2012+) GK 104 chip with 1536 cores A lot of major new features over earlier Fermi architecture K 10/GK 104 1536 cores K 20/GK 110 2496 cores K 40/GK 180 2880 cores CUDA Computer Capability 3. 0 see next http: //www. tomshardware. com/news/Nvid 16 ia-Kepler-GK 104 -Ge. Force-GTX-670680, 14691. html
NVIDA GPUs Stream processing -- Term used to denote processing of a stream of instructions operating in a data parallel fashion. Stream Processors (SPs) – theeexecution cores that will execute the stream. Each stream processor has compute resources such as register file, instruction scheduler, … Streaming multiprocessors (SMs) -- groups of streaming processors that shares control logic and cache.
NVIDIA C 2050 (as on coit-grid 06. uncc. edu and cci-grid 07) • 14 streaming multiprocessor (SMs) • Each streaming multiprocessor has 32 streaming processor (SPs) • So 448 streaming processor (cores) Apparently Fermi was originally intended to have 512 cores (16 SM) but design got too hot. 18
NVIDIA K 20 (as on coit-grid 08) • 13 streaming multiprocessor (SMXs, extreme) • Each streaming multiprocessor has 192 streaming processor (SPs) • So 2496 streaming processor (cores) Actually 15 SMs (2880 core) fabricated on chip to improve yield. 19
CUDA (Compute Unified Device Architecture) • Architecture and programming model introduced in NVIDIA in 2007 • Enables GPUs to execute programs written in C. • Within C programs, call SIMT “kernel” routines that are executed on GPU. • CUDA syntax extension to C identify routine as a Kernel. • Very easy to learn although to get highest possible execution performance requires understanding of hardware architecture. • Version 3 introduced 2009 • Version 4 introduced 2011 – significant additions including “unified virtual addressing” – a single address space across GPU and host. • Most recent version 5. 5 introduced July 2013 • We will go into CUDA in detail shortly and have programming 20
Questions