ELATSIC SCALING RDBMS scales vertically as compared to








ELATSIC SCALING: • RDBMS scales vertically as compared to the horizontal scaling of No. SQL. DBA SPECIALISTS: • RDBMS requires highly trained specialists to efficiently manage data. No. SQL requires less management, automatic repair and simpler data models. BIG DATA: • RDBMS has constraints on data volume as compared to No. SQL, which was built on the foundation of Big Data.

THE BAD SUPPORT and MATURITY: • No. SQL lacks the advantage of a high level of support as compared to RDBMS. • No. SQL is a relatively new technology with less firmly rooted organization supporting them. ADMINISTRATION: • A RDBMS administrator has a well defined industry standard role leading to much efficient management. On the other hand, No. SQL has no predefined roles for an administrator.

KEY CONCEPTS REPLICA SETS
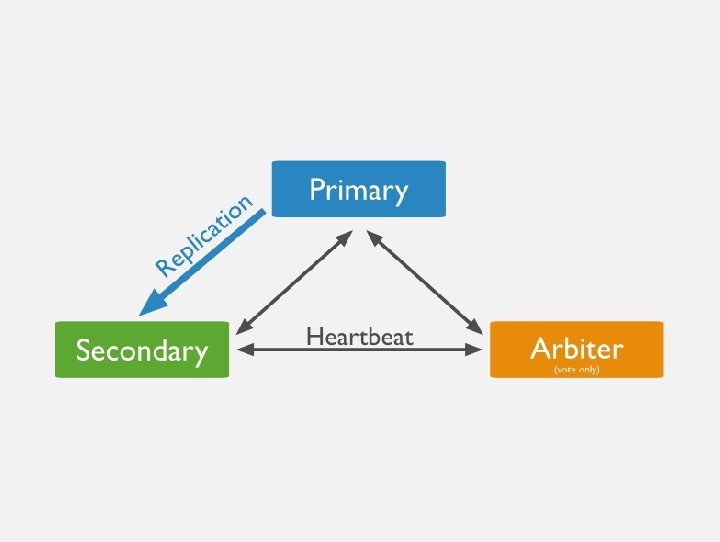

KEY CONCEPTS REPLICA SETS SHARDING
")
PRIMARY DATA ( integers 0 -100 )
 Shard key ( 0 > x <=")
PRIMARY DATA ( integers 0 -100 ) Shard key ( 0 > x <= 50) Shard key ( 50 > x <= 100) SHARDED DATA SHARD 1 ( integers 0 -50 ) SHARD 2 ( integers 51 -100 )

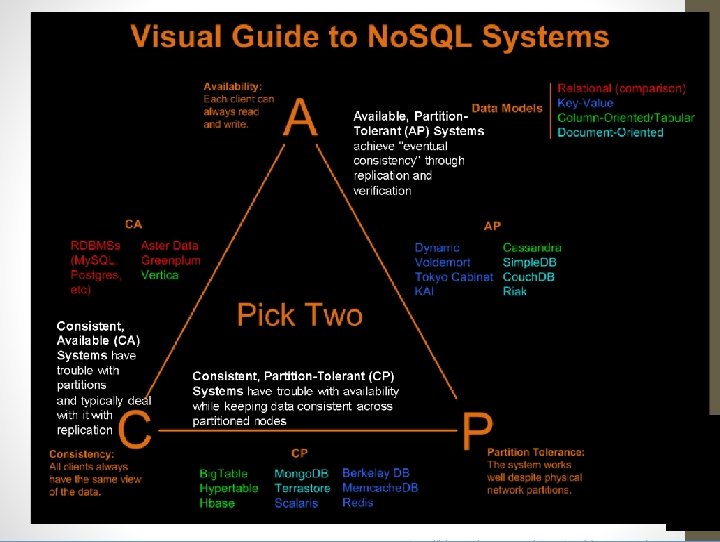
KEY CONCEPTS REPLICA SETS SHARDING CAP THEOREM
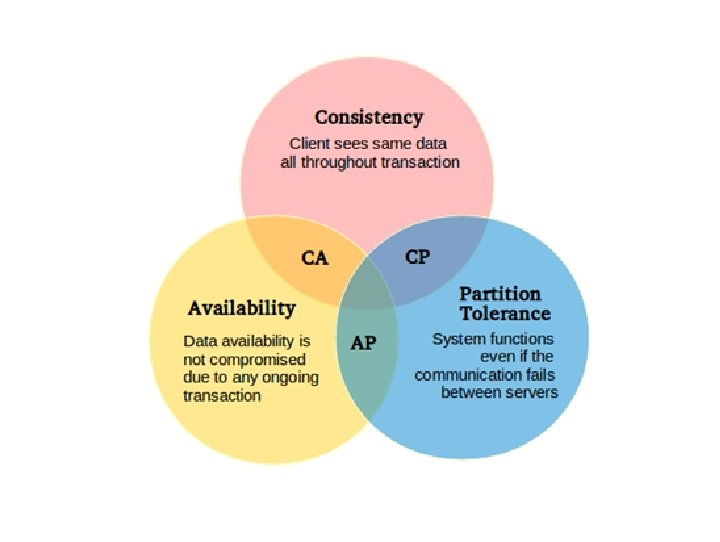

CAP THEOREM If you cannot limit the number of faults and requests can be directed to any server and you insist on serving every request you receive, then you cannot possibly be consistent. INTERPRETATION: You must always give something up: Consistency, Availability or Tolerance to Failure and Reconfiguration


WHAT IS mongo. DB ? OPEN SOURCE DATABASE

WHAT IS mongo. DB ? OPEN SOURCE DATABASE DOCUMENT ORIENTED NOSQL DATABASE

WHAT IS mongo. DB ? OPEN SOURCE DATABASE DOCUMENT ORIENTED NOSQL DATABASE DEVELOPED BY Mongo. DB INC. IN C++

WHAT IS mongo. DB ? OPEN SOURCE DATABASE DOCUMENT ORIENTED NOSQL DATABASE DEVELOPED BY Mongo. DB INC. IN C++ BSON – (JSON based-B stands for Binary )

KEY FEATURES OF mongo. DB DYNAMIC SCHEMA – No DDL

KEY FEATURES OF mongo. DB DYNAMIC SCHEMA HIGH PERFORMANCE

KEY FEATURES OF mongo. DB DYNAMIC SCHEMA HIGH PERFORMANCE RICH QUERY LANGUAGE WITH API SUPPORT

KEY FEATURES OF mongo. DB DYNAMIC SCHEMA HIGH PERFORMANCE RICH QUERY LANGUAGE WITH API SUPPORT HIGH AVAILABILITY – REPLICA SETS
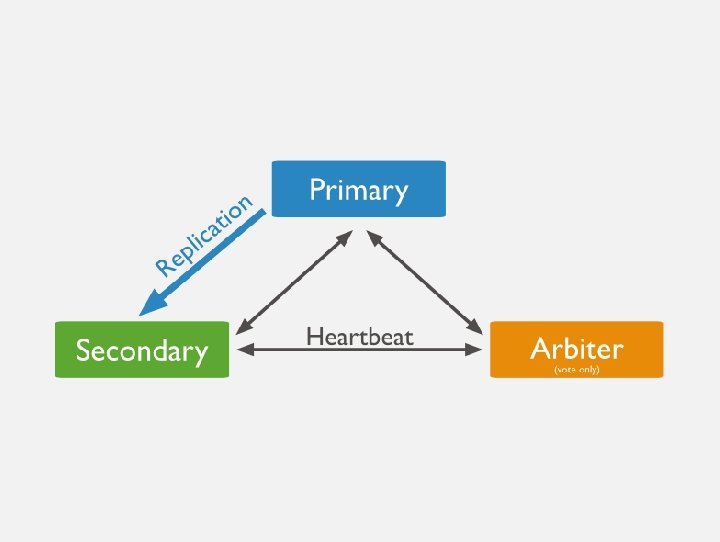

KEY FEATURES OF mongo. DB DYNAMIC SCHEMA HIGH PERFORMANCE RICH QUERY LANGUAGE WITH API SUPPORT HIGH AVAILABILITY – REPLICA SETS HORIZONTAL SCALABILITY – AUTO SHARDING

KEY FEATURES OF mongo. DB DYNAMIC SCHEMA HIGH PERFORMANCE RICH QUERY LANGUAGE WITH API SUPPORT HIGH AVAILABILITY – REPLICA SETSSCALABILITY – AUTO HORIZONTAL SHARDING EASY INTEGRATION OF DATA – NO ERD DIAGRAM

Mongo. DB ARCHITECTURE MONGOD: A Mongo DB instance MONGOS: Query Router MONGO: Interactive Shell There can be multiple Mongods using the same Mongos ( query router ) OR one Local MONGOS for every client to reduce network latency.
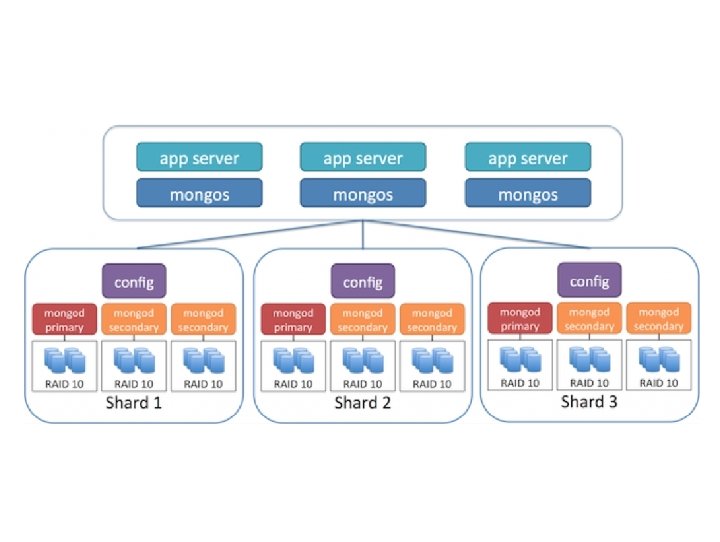

CONSISTENCY OF DATA • All read operations issued to the primary of replica set are consistent with last write operation. • Reads to primary have strict consistency (creates Oplog) • Reads to secondary have eventual consistency. (uses Oplog) • Failure occurs before the secondary nodes are updated.

Mongo. DB HIERARCHY DATABASES COLLECTIONS DOCUMENTS

Mongo. DB TERMINOLOGY

CREATE OPERATION SQL Schema Statements CREATE TABLE users ( id MEDIUMINT NOT NULL AUTO_INCREMENT, user_id Varchar(30), age Number, status char(1), PRIMARY KEY (id) ) Mongo. DB Schema Statements db. users. insert( { user_id: "abc 123", age: 55, status: "A" } ) However, you can also explicitly create a collection: db. create. Collection("users")

ALTER OPERATION ALTER TABLE users ADD SQL DATETIME Schema Statements join_date ALTER TABLE users DROP COLUMN join_date db. users. update( Mongo. DB Schema Statements { }, { $set: { join_date: new Date() } }, { multi: true } ) db. users. update( { }, { $unset: { join_date: "" } }, { multi: true } )
 Statements SELECT * FROM users db.")
READ OPERATION SQL SELECT Statements Mongo. DB find() Statements SELECT * FROM users db. users. find() SELECT id, user_id, status FROM users db. users. find( { }, { user_id: 1, status: 1 } ) SELECT user_id, status FROM users db. users. find( { }, { user_id: 1, status: 1, _id: 0 } ) SELECT * FROM users WHERE status = "A" db. users. find( { status: "A" } )

SELECT * FROM users WHERE status = "A" AND age = 50 db. users. find( { status: "A", age: 50 } ) SELECT * FROM users WHERE status = "A" OR age = 50 db. users. find( { $or: [ { status: "A" } , { age: 50 } ] } ) SELECT * FROM users WHERE age db. users. find( > 25 { age: { $gt: 25 } } ) SELECT * FROM users WHERE age db. users. find( < 25 { age: { $lt: 25 } } ) SELECT * FROM users WHERE age db. users. find( > 25 AND age <= 50 { age: { $gt: 25, $lte: 50 } } )

SELECT * FROM users WHERE status = "A" ORDER BY user_id DESC db. users. find( { status: "A" } ). sort( { user_id: -1 } ) SELECT COUNT(*) FROM users db. users. count() or db. users. find(). count() SELECT COUNT(user_id) FROM users db. users. count( { user_id: { $exists: true } } ) or db. users. find( { user_id: { $exists: true } } ). count() SELECT COUNT(*) FROM users WHERE age > 30 db. users. count( { age: { $gt: 30 } } ) or db. users. find( { age: { $gt: 30 } } ). count() SELECT DISTINCT(status) FROM users db. users. distinct( "status" )

UPDATE OPERATION UPDATE `users` SET `status` = ‘A’ WHERE `age` > ’ 18’;
 Delete a single document or all documents that match")
DELETE OPERATION db. collection. remove() Delete a single document or all documents that match a specified filter. db. collection. delete. One() Delete at most a single document that match a specified filter even though multiple documents may match the specified filter. db. collection. delete. Many() Delete all documents that match a specified filter. db. users. remove({“name”: ”bob”}) db. users. delete. One({“name”: ”bob”}) db. users. delete. Many({“age” : {$gt : 50}})

AGGREGATION PIPELINE
 We have 26 Mongo. DB servers split into")
David Mytton – CEO( Server. Density) We have 26 Mongo. DB servers split into 6 different replica sets. The main database uses sharding across 3 replica sets with 15 members in total with the remaining servers in smaller, task specific replica sets. As a server monitoring application we receive a large amount of incoming data which goes into Mongo. DB. In April 2011 this was 3. 5 TB (for 1 month), and we're processing billions of documents every month. This is the live database for our application and we get response times of around 40 ms (for the entire app) and usually less than 5 ms for Mongo queries on their own. Update Aug 2015: We now are processing over 350 TB of data per month through Mongo. DB on the same size sharded cluster as before, but with significantly larger specs - 4 TB of SSDs and 256 GB RAM per node (costly). We're about to upgrade to Mongo. DB 3 which should allow us to reduce the hardware requirements by about 40%, due to optimisations in the query planner and new compression functionality.

SUMMARY • No. Sql built to address a distributed database system • • Sharding Replication • CAP Theorem: consistency, availability and partition tolerant • Mongo. DB • • • Document oriented data , schema-less. Provides query consistent reads on primary sets. Lacks transactions , joins.
- Slides: 45