Dot product of vectors The projection of the















. •")



 • We need: – One entry for each word in the")
 Dj, tfj Index terms df computer 3 D 7, 4 database")
 • TF and IDF for each token can be computed in")
 to find the limited")










 by retrieving all docs")




- Slides: 46
Dot product of vectors: The projection of the vector A into the vector B. By Wikipedia.
http: //blog. christianperone. com/2013/09/machine-learning-cosine-similarity-for-vector-space-models-part-iii/
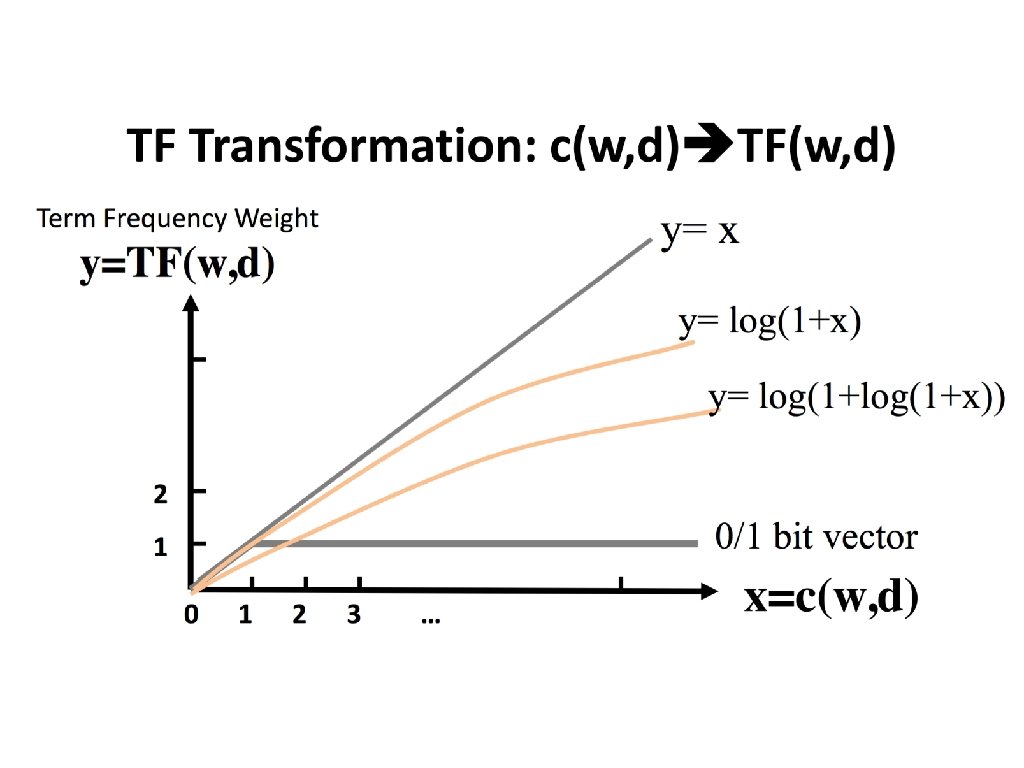
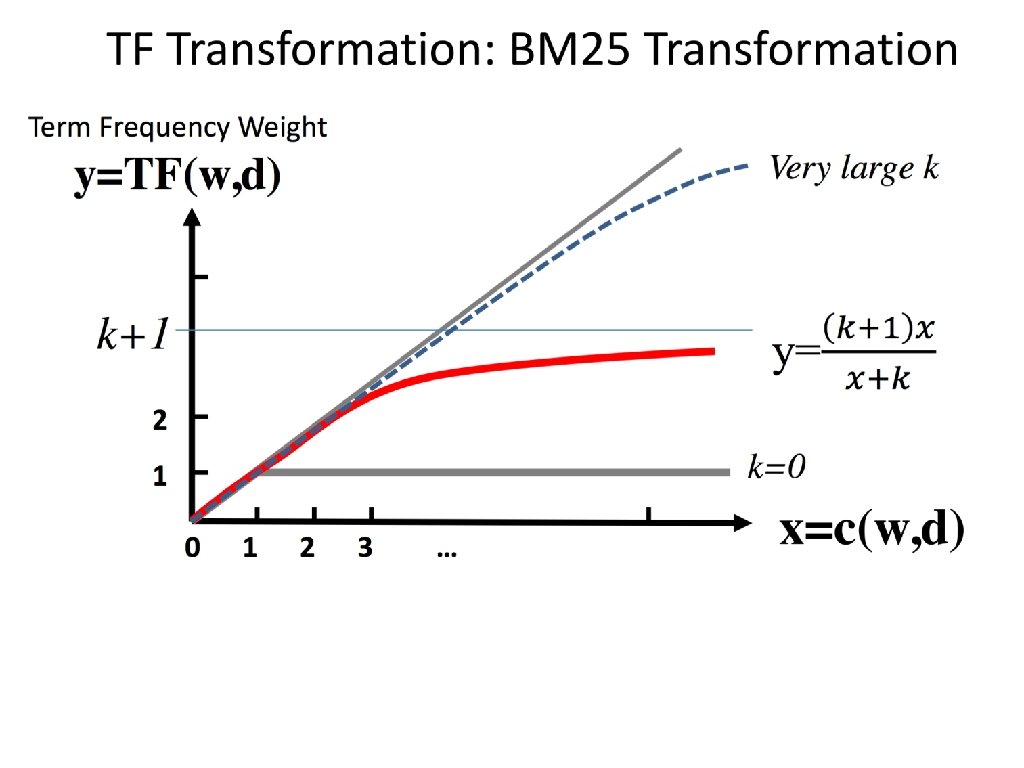
Weighting term frequency: tf • What is the relative importance of – 0 vs. 1 occurrence of a term in a doc – 1 vs. 2 occurrences – 2 vs. 3 occurrences … • Unclear: while it seems that more is better, a lot isn’t proportionally better than a few
Effect of idf on ranking • Does idf have an effect on ranking for one-term queries, like – i. Phone • idf has no effect on ranking one term queries – idf affects the ranking of documents for queries with at least two terms – For the query capricious person, idf weighting makes occurrences of capricious count for much more in the final document ranking than occurrences of person. 16
Comments on Vector Space Models • Simple, mathematically based approach. • Considers both local (tf) and global (idf) word occurrence frequencies. • Provides partial matching and ranked results. • Tends to work quite well in practice despite obvious weaknesses. • Allows efficient implementation for large document collections.
Problems with Vector Space Model • Missing semantic information (e. g. word sense). • Missing syntactic information (e. g. phrase structure, word order, proximity information). • Assumption of term independence (e. g. ignores synonomy). • Lacks the control of a Boolean model (e. g. , requiring a term to appear in a document). – Given a two-term query “A B”, may prefer a document containing A frequently but not B, over a document that contains both A and B, but both less frequently.
Practical Implementation • Based on the observation that documents containing none of the query keywords do not affect the final ranking • Try to identify only those documents that contain at least one query keyword • Actual implementation of an inverted index
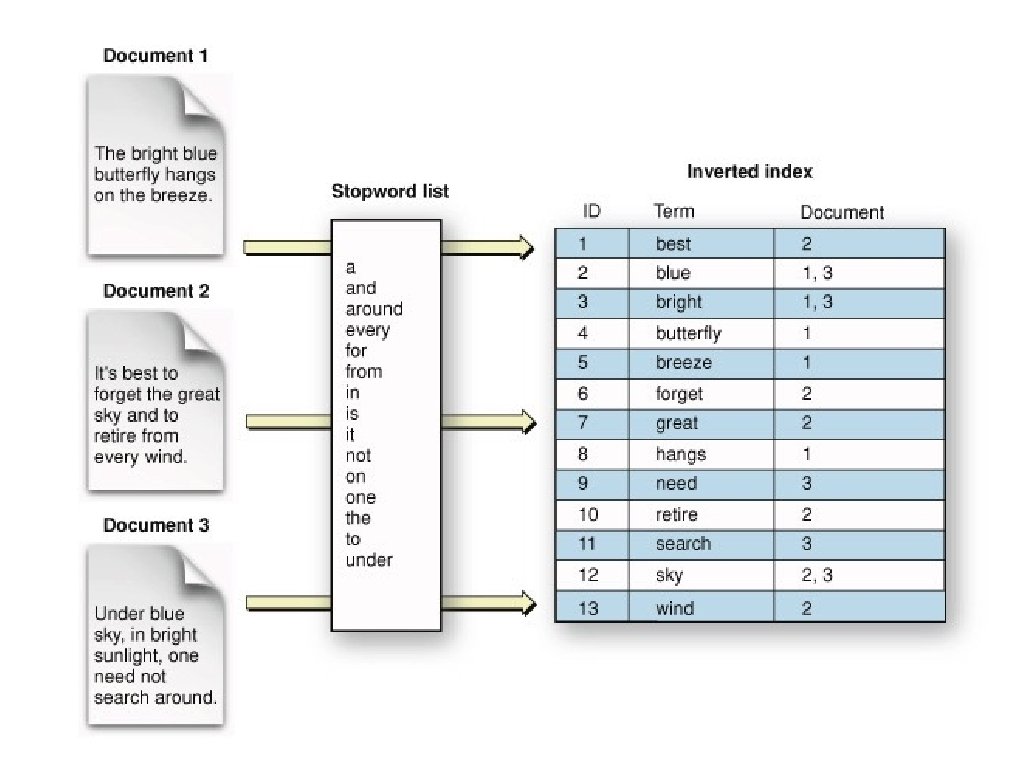
Step 1: Preprocessing • Implement the preprocessing functions: – For tokenization – For stop word removal – For stemming • Input: Documents that are read one by one from the collection • Output: Tokens to be added to the index – No punctuation, no stop-words, stemmed
Step 2: Indexing • Build an inverted index, with an entry for each word in the vocabulary • Input: Tokens obtained from the preprocessing module • Output: An inverted index for fast access
Step 2 (cont’d) • We need: – One entry for each word in the vocabulary – For each such entry: • Keep a list of all the documents where it appears together with the corresponding frequency TF – For each such entry, keep the total number of occurrences in all documents: • IDF
Step 2 (cont’d) Dj, tfj Index terms df computer 3 D 7, 4 database 2 D 1, 3 4 D 2, 4 1 D 5, 2 ··· science system Index file lists
Step 2 (cont’d) • TF and IDF for each token can be computed in one pass • Cosine similarity also required document lengths • Need a second pass to compute document vector lengths – Remember that the length of a document vector is the square-root of sum of the squares of the weights of its tokens. – Remember the weight of a token is: TF * IDF – Therefore, must wait until IDF’s are known (and therefore until all documents are indexed) before document lengths can be determined. • Do a second pass over all documents: keep a list or hashtable with all document id-s, and for each document determine its length.
Step 3: Retrieval • Use inverted index (from step 2) to find the limited set of documents that contain at least one of the query words. • Incrementally compute cosine similarity of each indexed document as query words are processed one by one. • To accumulate a total score for each retrieved document, store retrieved documents in a hashtable, where the document id is the key, and the partial accumulated score is the value. • Input: Query and Inverted Index (from Step 2) • Output: Similarity values between query and documents
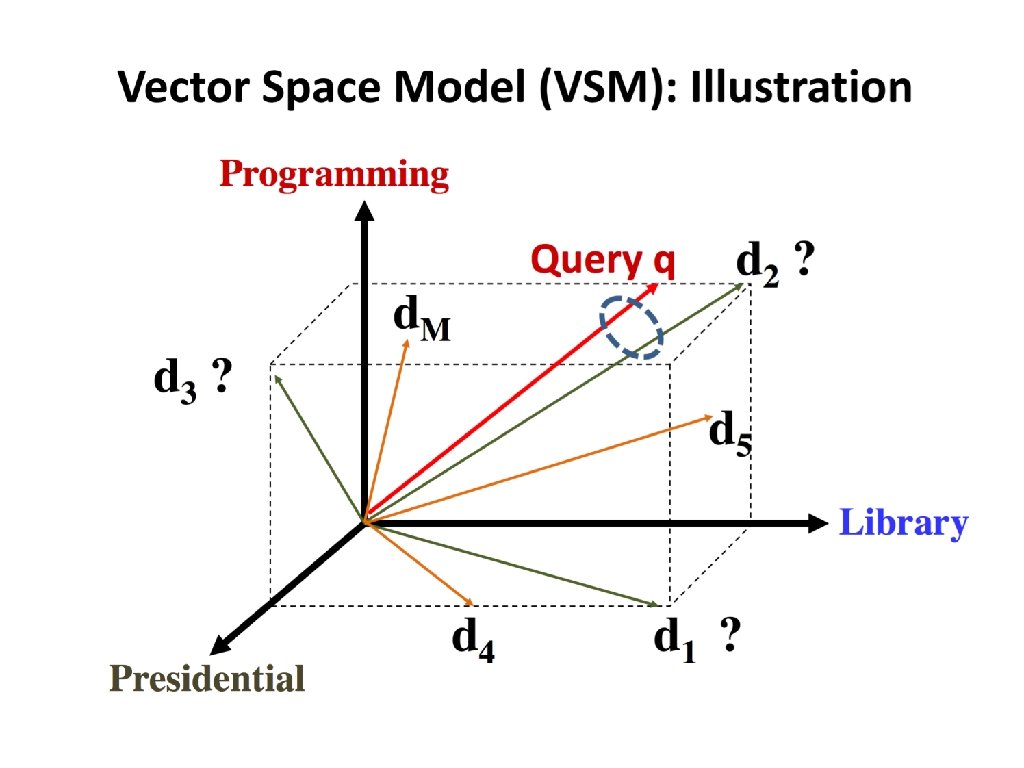
Sec. 6. 3 Queries as vectors • Key idea 1: Do the same for queries: represent them as vectors in the space • Key idea 2: Rank documents according to their proximity to the query in this space • proximity = similarity of vectors • proximity ≈ inverse of distance • Recall: We do this because we want to get away from the you’re-either-in-or-out Boolean model. • Instead: rank more relevant documents higher than less relevant documents
Step 4: Ranking • Sort the hashtable including the retrieved documents based on the value of cosine similarity – sort {$retrieved{$b} �$retrieved{$a}} keys %retrieved • Return the documents in descending order of their relevance • Input: Similarity values between query and documents • Output: Ranked list of documented in reversed order of their relevance
Summary – vector space ranking • Represent the query as a weighted tf-idf vector • Represent each document as a weighted tf-idf vector • Compute the )cosine( similarity score for the query vector and each document vector • Rank documents with respect to the query by score • Return the top K (e. g. , K = 10) to the user
Difficulties with gauging Relevancy • Relevancy, from a human standpoint, is: – Subjective: Depends upon a specific user’s judgment. – Situational: Relates to user’s current needs. – Cognitive: Depends on human perception and behavior. – Dynamic: Changes over time. 35
Unranked retrievaluation: Precision and Recall • Precision: fraction of retrieved docs that are relevant = P(relevant|retrieved) • Recall: fraction of relevant docs that are retrieved = P(retrieved|relevant) Relevant Not Relevant Retrieved tp fp Not Retrieved fn tn • Precision P = tp/(tp + fp) • Recall R = tp/(tp + fn)
Another View Space of all documents Relevant + Retrieved Not Relevant + Not Retrieved
Trade-offs Returns relevant documents but misses many useful ones too The ideal Precision 1 0 Recall 1 Returns most relevant documents but includes lot of junk 39
Why not just use accuracy? • How to build a 99. 9999% accurate search engine on a low budget…. Snoogle. com Search for: 0 matching results found. • People doing information retrieval want to find something and
Precision/Recall • You can get high recall (but low precision) by retrieving all docs for all queries! • Recall is a non-decreasing function of the number of docs retrieved • In a good system, precision decreases as either number of docs retrieved or recall increases – A fact with strong empirical confirmation
Difficulties in using precision/recall • Should average over large corpus/query ensembles • Need human relevance assessments – People aren’t reliable assessors • Assessments have to be binary – Nuanced assessments? • Heavily skewed by corpus/authorship – Results may not translate from one domain to another
F-Measure • Harmonic mean of recall and precision ' • ממוצע הרמוני הוא "ההפכי של הממוצע החשבוני של ההפכיים • נוטה להמעיט בערך מספרים גדולים ולהגדיל ערכם של מספרים קטנים • Beta controls relative importance of precision and recall – Beta = 1, precision and recall equally important – Beta = 5, recall five times more important than precision
F 1 and other averages Combined Measures 100 Minimum Maximum Arithmetic Geometric Harmonic 75 50 25 0 0 25 50 75 Precision (Recall fixed at 70%) 100
https: //www. freebase. com/m/017 kb 5