Distributed Systems NFS Operating Systems Course The Hebrew

Distributed Systems: NFS Operating Systems Course The Hebrew University Spring 2015

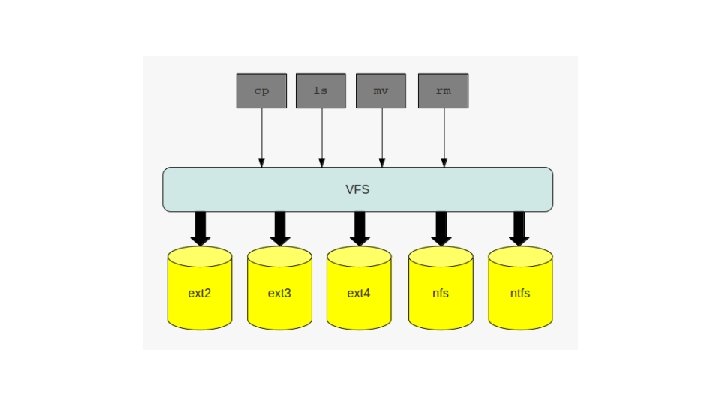
Prelude VFS - Virtual File System. ● An abstraction layer over a concrete file system ● Specifies interface between kernel and FS ● Client application may access several FS using the same interface o (ext 3 - local, NFS - remote, FAT 32 - disk device)

NFS Networked File System pros? cons? difficulties? log to any cs workstation and your files will magically ‘appear’ there

Mount/Unmount ● Mount - The root dir of the mounted FS is identified with a leaf dir in the local FS o /mnt/fs is the mounting point ● Unmount - Unlink the mounted FS

Transparency vnode representation A file’s vnode contains the server indication, which may be local or remote: NFS client is invoked to do an RPC to the appropriate NFS server

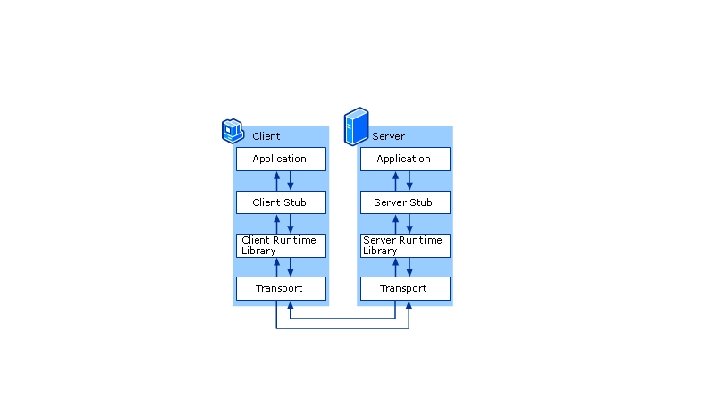
RPC - Remote Procedure Call ● The process should be as simple as local procedure call ● Client call a function. . . [magic+some time]. . . the function returns. ● RPC system consist of mainly two components: o stub generator o run-time library
; foo(arg 1); … foo(arg 1, arg 2,")
Let’s assume a server’s interface: interface{ foo(); foo(arg 1); … foo(arg 1, arg 2, arg 3); };
 Client Stub: ● Create message")
Stub Generator User: foo(arg 1, arg 2, arg 3) Client Stub: ● Create message buffer ● Marshall arguments ● Send buffer (using the run-time lib. )
 Server Stub: ● Unpack message (unmarshall) ● Call the actual function")
Stub Generator (II) Server Stub: ● Unpack message (unmarshall) ● Call the actual function ● Package the results ● Send the reply
 Client Stub: ● Wait for reply ● Unpack returned code and")
Stub Generator (III) Client Stub: ● Wait for reply ● Unpack returned code and other args (unmarshall) ● Return the caller User: [ Happily continues to execute code]
![Run-Time Library [Out of the scope] Does the actual communication Routing, sending, waiting, receiving](http://slidetodoc.com/presentation_image_h/170fd7674ae728f26f3bb378ca669846/image-12.jpg "Run-Time Library [Out of the scope] Does the actual communication Routing, sending, waiting, receiving")
Run-Time Library [Out of the scope] Does the actual communication Routing, sending, waiting, receiving etc. . .

NFS Concept

NFSv 2 ● Sun Microsystems 86 ● Main goal: Simple and fast server recovery ● one server down makes many clients unhappy

NFSv 2 - Fast Recovery, Stateless ● The server does not track anything that the clients do. ● The protocol is designed to deliver in each request all the information that is needed in order to complete the request. ● [no open file table for each client, no file pointer, etc. ]
, and able to optimize")
Stateful ● Server is aware of sessions (communication with clients), and able to optimize it. ● File descriptor ● Cache ● Which client opened which file ● What happens on failure?

Stateful - Failure ● FD lost, tables are lost, cached blocks lost. . ● We will need a long and tedious protocol to resolve these issues ● But how stateless servers are better?

Stateless - Objectives ● Operations must be self contained. ● Idempotent operations - if an operation is repeated, it will produce the same result. e. g. read the next 146 bytes - is not idempotent read 146 bytes at offset 700 - is idempotent [what happens if because of network problems the first request was sent twice? ]

NFSv 3 - Protocol

NFS Versions

The Crux - File Handles ● FH uniquely describes a file or directory that particular operation will operate upon ● Thus many requests include an FH ● A file unique identifier (FH) = volume identifier + inode number + generation number

The Crux - File Handles ● volume identifier - which file system the request refers to, i. e. partition, e. g. nfs: //store 05/z/cbio/elkana ● inode number ● generation number - an incrementing index identifying the number of reusages

FH Usage Example NFSPROC_GETATTR expects: file handle returns: attributes NFSPROC_SETATTR expects: file handle, attributes returns: nothing NFSPROC_LOOKUP expects: directory file handle, name of file/directory to look up returns: file handle

From Protocol To FS

From Protocol To FS

From Protocol To FS

Failure ● ● ● Failure - Request Lost, Server Down, Reply Lost Client sets timer and retries request Idempotency idempotent getattr()? Idempotent write()? Idempotent mkdir()?

NFS problems ● P 1: READ requests throughout the file? it is sloooow! o S 1: cache the file ● P 2: WRITE is also slow o S 2: write buffer ● P 3: cache consistency! o o o e. g. bob and marley work on the same song S’ 3: flush on close consistency S’’ 3: GETATTR and attribute caching scalability? : ( locks maintenance?

Close-up: v 2 vs v 3 ● FH - fixed 32 bit, variable up to 64 bit ● limited RW to 8192 bytes, UDP implementation limits to IP datagram (65535) ● attributes return on every ATTR call ● async WRITE operation

Close-up v 4. 1 p. NFS

Real World Problem, one NFS to all!?

facebook stats -8/10

FB Photos Dist. “Hot” + “Warm” photos Popularity Items sorted by popularity

Haystack • Object store for sharing photos on Facebook • Data is written once, read often, never modified, and rarely deleted • Storage system designed because traditional filesystems perform poorly under the workload • Multiplied over billions of photos and petabytes of data, • Accessing metadata becomes the throughput bottleneck

Haystack - Goals 1. High throughput and Low latency - Log structured file system, all metadata in main memory minimizing disk accesses per I/O 2. Fault-tolerance - replicating each photo in geographically distinct locations 3. Cost-effectiveness - custom designing the filesystem for photo storing application 4. Simplicity - restricting the design to well-known straightforward techniques

1 st Generation: NFS-Based

1 st Generation: NFS-Based • • • User's browser first sends an HTTP request to the web server. For each photo the web server constructs a URL to the location from which to download the data. If image is cached, content delivery network (CDN) responds immediately with the photo. Else CDN contacts Facebook's photo store server using the URL. The photo store server extracts the volume and full path to the file, reads the data over NFS, and returns the result to the CDN.

1 st Generation: NFS-Problems 3 disk operations were needed to fetch an image: • one to read directory metadata into memory • one to load the inode into memory • one to read the file contents. Actually before optimizing the directory sizes, the directory blockmaps were too large to be cached, and 10 disk operations might be needed to fetch the image!

Haystack Architecture 40

Haystack Architecture • • Haystack system keeps all the metadata in main memory. Goal: dramatically reduce memory used for filesystem metadata. Problem: Storing single photo per file results in more filesystem metadata than could be reasonably cached Solution: Store millions of photos in a single file and therefore maintains very large files

Haystack Architecture • • • The Haystack Store capacity is organized into physical volumes. Physical volumes are further grouped into logical volumes. Photo is written to all corresponding physical volumes for redundancy. The Haystack Directory maintains the logical to physical mapping along with other application metadata, such as the logical volume where each photo resides and the logical volumes with free space. The Haystack Cache functions as an internal CDN, another level of caching to back up the CDN.

Haystack Architecture When the browser requests a photo: • the web server uses the Directory to construct a URL • Each Store machine manages multiple physical volumes. • Each volume holds millions of photos. • A physical volume is simply a very large file (100 GB) saved as "/haystack-logical volume. ID". • Haystack is a log-structured append-only object store.

Haystack Architecture • • • A Store machine access a photo quickly using only the id of the logical volume and file offset at which the photo resides. Keystone of the Haystack design: – retrieving the filename, offset, and size for a particular photo without needing disk operations. A Store machine keeps: – open file descriptors - for each physical volume – in-memory mapping - photo ids to the FS metadata (i. e. , file, offset and size in bytes) – Each photo stored in the file is called a needle.
- Slides: 44