Distributed Information Systems CSCI 5533 Presentation ID 19
 Presentation ID: 19 Query Processing In Distributed Multi -")
Distributed Information Systems (CSCI 5533) Presentation ID: 19 Query Processing In Distributed Multi - DBMS Submitted to: Dr. Liaw, Morris Submitted by: Kumar, Manoj

Distributed Multi-DBMS

Overview of Multi-DBMS • It’s a layer of software • Individual Query Processor

Reasons for Query Processing Being complex in Multi-DBMS than in Distributed DBMS • 1. Difference in Capability of Component DBMSs • 2. Complexity of Cost function • 3. Difficulty in Moving Data between DBMSs • 4. Local Optimization capability of each DBMS may be different

Autonomy Issues • 1. Communication Autonomy • 2. Design Autonomy • 3. Execution Autonomy

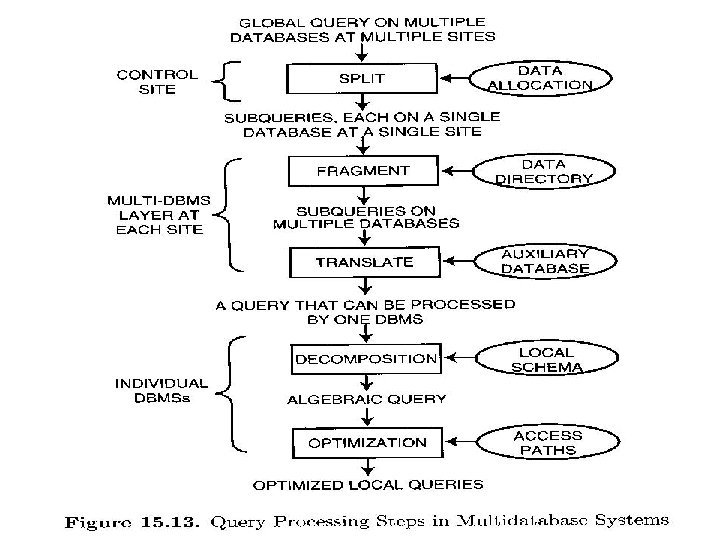
• Architecture Of Distributed Multi-DBMS poses certain challenges too. Data is not only distributed across multiple sites but also across multiple databases which are individually managed.

• Only 2 parties involve in case of Distributed DBMS – Control site – Local sites • In Distributed Multi-DBMS 3 parties participate – Multi-DBMS layer at control site – Multi-DBMS layer at sites that process query – Component DBMS

Query Processing Layers in Distributed Multi-DBMS After Query is received at a site …. Step 1: Split the query into subqueries based on data distribution across multiple sites - Global Directory (Data Allocation Info. ) - this site is CONTROL SITE

• Step 2: Subquery is sent to the site where it needs to be processed • Step 3: Multi-DBMS layer at each site further “fragments” the query • Step 4: Each subquery is Translated to respective DBMS language

– In order to facilitate translation, Auxiliary database is used. – Auxiliary database maintains extensive information about global query language and individual query languages used by DBMSs • Step 5: Query submitted to Component DBMSs are processed

– Decomposition – Optimization – Execution

• Questions ? ?
- Slides: 13