Direct Cache Access for High Bandwidth Network IO

Direct Cache Access for High Bandwidth Network I/O Authors: Ram Huggahalli Ravi Iyer Scott Tetrick Presented by Cao Zhang

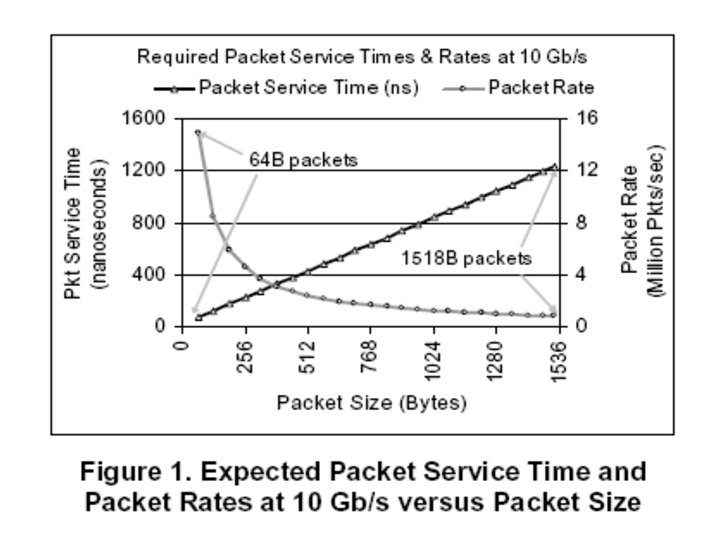
Introduction Ø Recent I/O technologies such as PCI-Express and 10 Gb Ethernet enable unprecedented levels of I/O bandwidth in mainstream platforms Ø Memory latency alone can limit processors from matching 10 Gb inbound network I/O traffic Ø A platform-wide method called Direct Cache Access (DCA) to deliver inbound I/O data directly into processor caches

Basic Processor, Memory and I/O Interaction

I/O Interactions From A Cache Perspective

TCP/IP Example

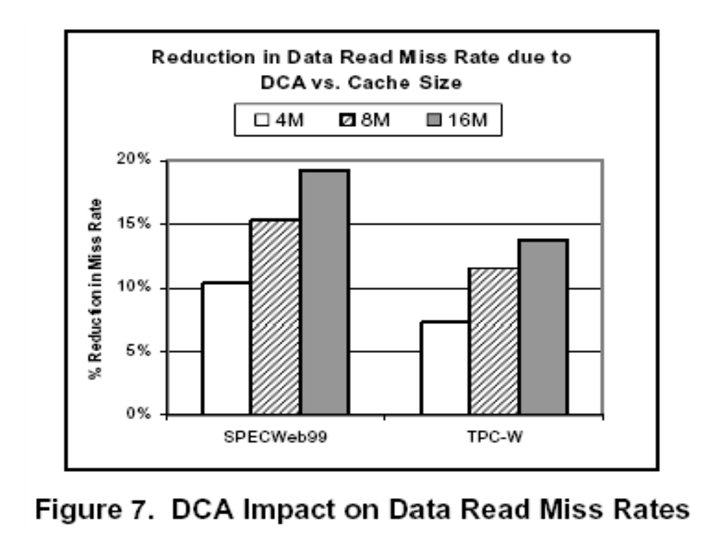
Memory Access Profiles of Benchmarks Ø NTTTCP Ø SPECweb 99 Ø TPC-W Ø TPC-C Evaluation Methodology Ø CASPER cache simulation fed by memory access traces Ø Simulated 4 MB, 8 MB, and 16 MB caches, all configured a 64 -byte line size and 8 -way set associative

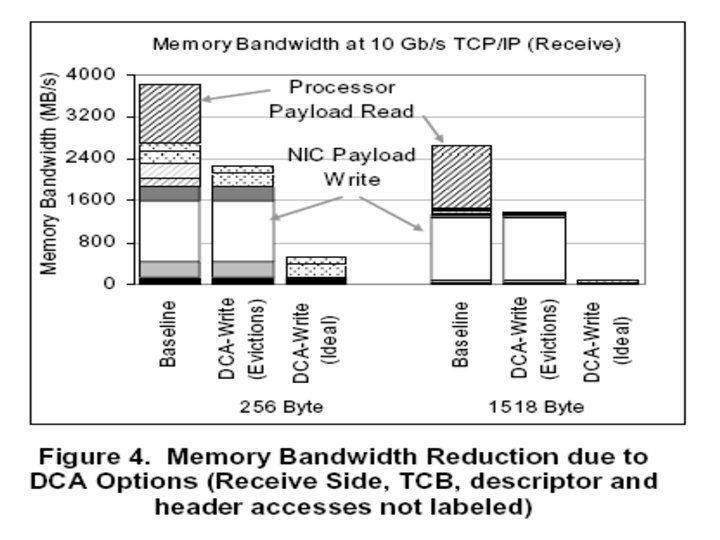
Usage of I/O Writes by Processor

Distance between I/O Writes and Processor Reads

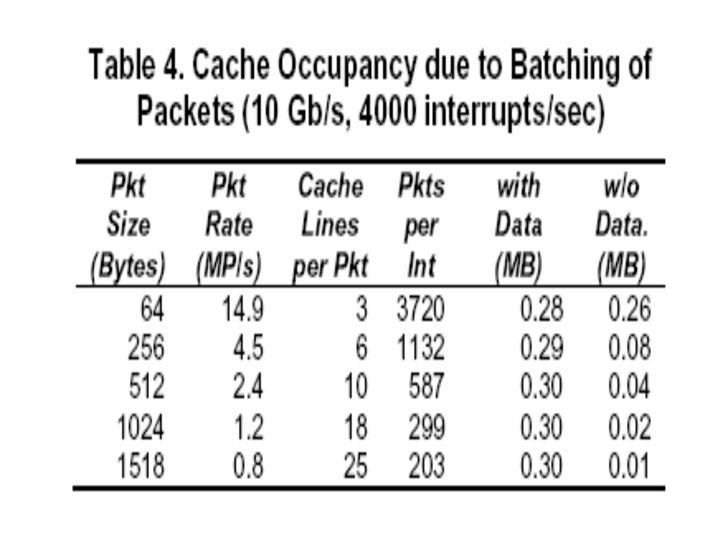
Traffic Profiles

System Considerations Ø Cache Selection within a Hierarchy Last level of cache is preferred Ø Cache Replacement Policy Limiting I/O-related allocations to one cache way Ø System Interconnect Protocol 1. Write-Update can be useful 2. Prefetch hint Ø Identify the Target Processor NUMA memory affinity and connection based affinity
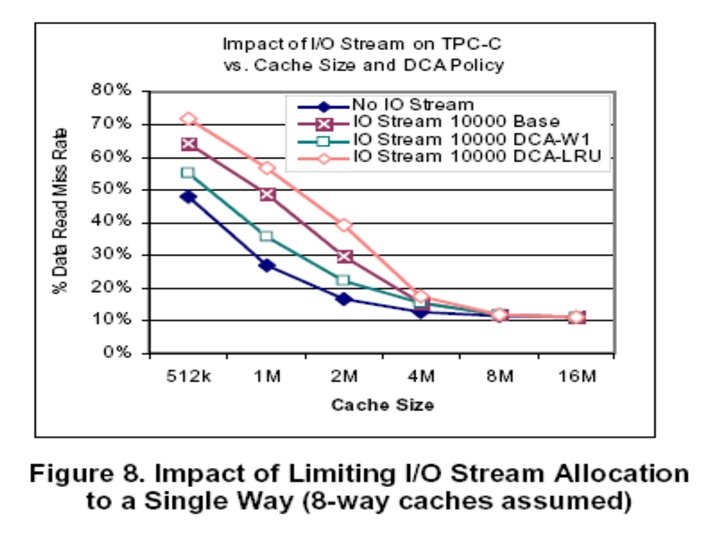
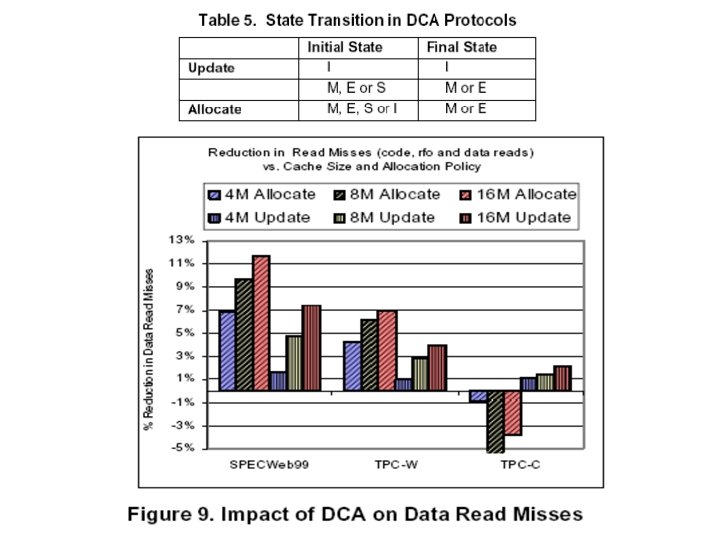


Summary of Architectural Guidelines

Ø Conclusions Ø References Ø Questions?
- Slides: 19