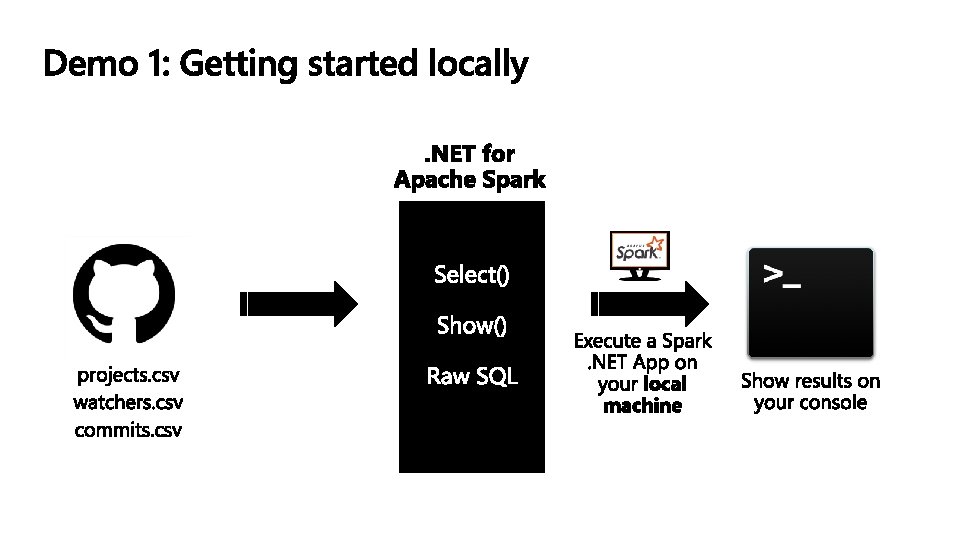
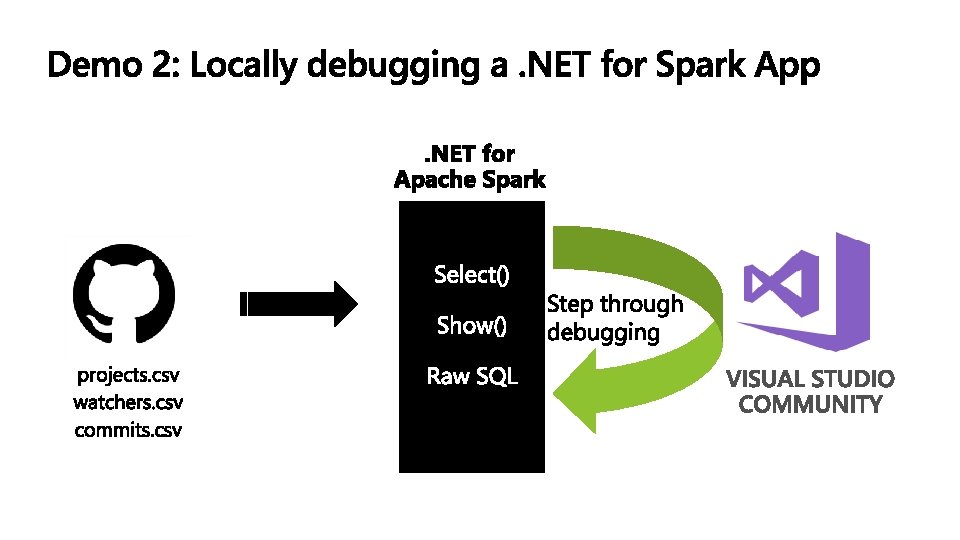
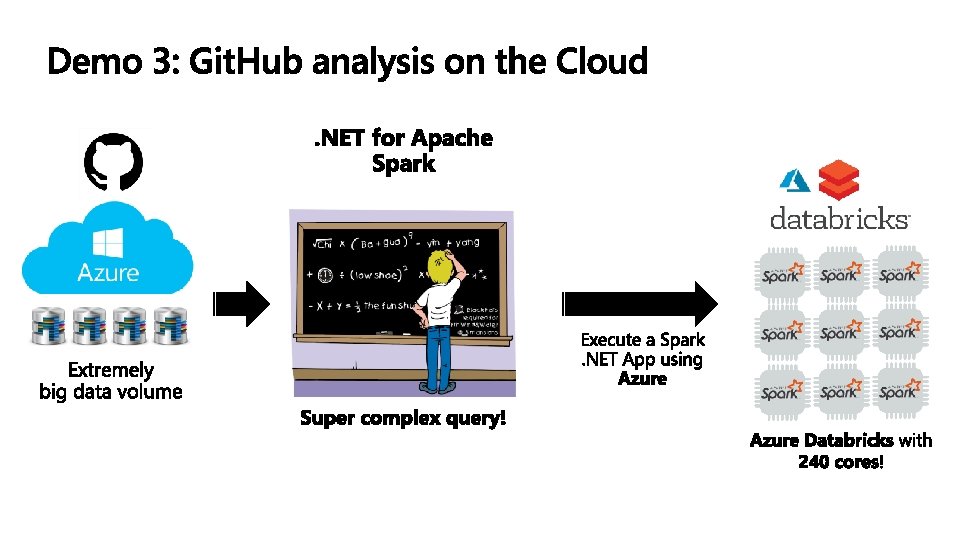
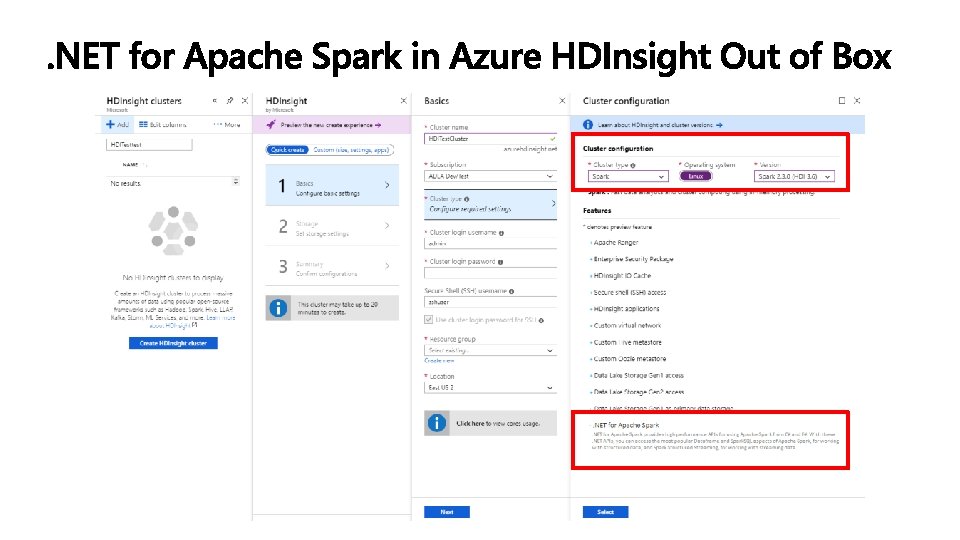
DESIGNED FOR THE QUESTIONS YOU KNOW ETL 1










, more than 70% expressed")




. Get. Or. Create(); var dataframe = spark. Read().")
. join(nation, $\"r_regionkey\" === nation(\"n_regionkey\")). join(supplier,")

 . NET Program Data. Frame Spark.")



 Idiomatic experiences for C#")



![CREATE TABLE [dbo]. [Customer] WITH ( DISTRIBUTION = ROUND_ROBIN , CLUSTERED INDEX (customerid) )](https://slidetodoc.com/presentation_image_h/37e762f53861acd545f33dabe029df89/image-30.jpg "CREATE TABLE [dbo]. [Customer] WITH ( DISTRIBUTION = ROUND_ROBIN , CLUSTERED INDEX (customerid) )")








- Slides: 39
DESIGNED FOR THE QUESTIONS YOU KNOW! ETL 1 2 Increasing data volumes New data sources and types Data sources Non-relational data OLTP ERP CRM LOB Devices Web Sensors Social 3 Cloud-born data 5
The data lake approach Store all data Ingest all data in native format without schema definition regardless of requirements Devices Do analysis Schematize for scenario, run scale out analysis Batch queries Social Interactive queries LOB applications Devices Video Real-time analytics Social LOB applications Sensors Web Sensors Video Relational Web Relational Clickstream Machine Learning Data warehouse
The modern data warehouse extends the scope of the data warehouse to serve big data that’s prepared with techniques beyond relational ETL Modern data warehousing Advanced analytics Real-time analytics “We want to integrate all our data—including big data—with our data warehouse” Advanced analytics is the process of applying machine learning and deep learning techniques to data for the purpose of creating predictive and prescriptive insights “We’re trying to get insights from our devices in real-time” “We’re trying to predict when our customers churn”
ORCHESTRATION & DATA FLOW ETL Azure Data Factory INGEST STORE PREP & TRAIN MODEL & SERVE Logs, files and media (unstructured) Azure Data Factory Azure Data Lake Storage Azure Databricks Power BI (Python, Scala, Spark SQL, . NET for Apache Spark) Polybase Business/custom apps (Structured) Azure SQL Data Warehouse Azure Analysis Services Azure also supports other Big Data services like Azure HDInsight and Azure Data Lake to allow customers to tailor the above architecture to meet their unique needs.
Apache Spark is an OSS fast analytics engine for big data and machine learning Improves efficiency through: General computation graphs beyond map/reduce In-memory computing primitives Allows developers to scale out their user code & write in their language of choice Rich APIs in Java, Scala, Python, R, Spark. SQL etc. Batch processing, streaming and interactive shell Available on Azure via Azure Databricks Azure HDInsight Iaa. S/Kubernetes
In a recently conducted. NET Developer survey (> 1000 developers), more than 70% expressed interest in Apache Spark! Would like to tap into OSS eco-system for: Code libraries, support, hiring Locked out from big data processing due to lack of. NET support in OSS big data solutions A lot of big data-usable business logic (millions of lines of code) is written in. NET! Expensive and difficult to translate into Python/Scala/Java!
Goal: . NET for Apache Spark is aimed at providing . NET developers a first-class experience when working with Apache Spark. Non-Goal: Converting existing Scala/Python/Java Spark developers.
Microsoft is committed… • • Technical documentation, blogs and articles End-to-end scenarios • • • Performance benchmarking (cluster) Production workloads Out of Box with Azure HDInsight, easy to use with Azure Databricks • • C# (and F#) language extensions using. NET Performance benchmarking (Interop) Portability aspects (e. g. , cross-platform. NET Standard) Tooling (e. g. , Apache Jupyter, Visual Studio Code) • • Interop layer for. NET (Scala-side) Potentially optimizing Python and R interop layers
. NET for Apache Spark was open sourced @Spark+AI Summit 2019 • Website: https: //dot. net/spark • Git. Hub: https: //github. com/dotnet/spark Spark project improvement proposals: • Interop support for Spark language extensions: SPARK-26257 • . NET bindings for Apache Spark: SPARK-27006 Contributions to foundational OSS projects: • Apache arrow: ARROW-4997, ARROW-5019, ARROW-4839, ARROW 4502, ARROW-4737, ARROW-4543, ARROW-4435 • Pyrolite (pickling library): Improve pickling/unpickling performance, Add a Strong Name to Pyrolite
. NET Standard Spark Data. Frames with Spark. SQL . NET Standard 2. 0 Batch & streaming Machine Learning Speed & productivity Including access to ML. NET Performance optimized interop, as fast or faster than py. Spark . NET Spark UDFs works with Spark v 2. 3. x/v 2. 4. [0/1] and includes ~300 Spark. SQL functions works with including. NET Framework v 4. 6. 1+ Spark Structured and. NET Core v 2. 1+ Streaming and all and includes C#/F# Spark-supported data support sources https: //github. com/dotnet/spark/examples
var spark = Spark. Session. Builder(). Get. Or. Create(); var dataframe = spark. Read(). Json(“input. json”); var concat = Udf<int? , string>((age, name)=>name+age); dataframe. Filter(df["age"] > 21). Select(concat(df[“age”], df[“name”]). Show();
Scala C# val europe = region. filter($"r_name" === "EUROPE"). join(nation, $"r_regionkey" === nation("n_regionkey")). join(supplier, $"n_nationkey" === supplier("s_nationkey")). join(partsupp, supplier("s_suppkey") === partsupp("ps_suppkey")) var europe = region. Filter(Col("r_name") == "EUROPE"). Join(nation, Col("r_regionkey") == nation["n_regionkey"]). Join(supplier, Col("n_nationkey") == supplier["s_nationkey"]). Join(partsupp, supplier["s_suppkey"] == partsupp["ps_suppkey"]); val brass = part. filter(part( "p_size") === 15 && part("p_type"). ends. With("BRASS")). join(europe, europe("ps_partkey") === $"p_partkey") var brass = part. Filter(part["p_size"] == 15 & part["p_type"]. Ends. With("BRASS")). Join(europe, europe["ps_partkey"] == Col("p_partkey")); val min. Cost = brass. group. By(brass( "ps_partkey")). agg(min("ps_supplycost"). as("min")) var min. Cost = brass. Group. By(brass["ps_partkey"]). Agg(Min("ps_supplycost"). As("min")); brass. join(min. Cost, brass( "ps_partkey") === min. Cost("ps_partkey")). filter(brass("ps_supplycost") === min. Cost("min")). select("s_acctbal", "s_name", "n_name", "p_partkey", "p_mfgr", "s_address", "s_phone", "s_comment"). sort($"s_acctbal". desc, $"n_name", $"s_name", $"p_partkey"). limit(100). show() brass. Join(min. Cost, brass["ps_partkey"] == min. Cost["ps_partkey"]). Filter(brass["ps_supplycost"] == min. Cost["min"]). Select("s_acctbal", "s_name", "n_name", "p_partkey", "p_mfgr", "s_address", "s_phone", "s_comment"). Sort(Col("s_acctbal"). Desc(), Col("n_name"), Col("s_name"), Col("p_partkey")). Limit(100). Show(); Similar syntax – dangerously copy/paste friendly! C# vs Scala (e. g. , == vs ===) $”col_name” vs. Col(“col_name”) Capitalization
Regular execution path (no. NET runtime during execution) . NET Program Data. Frame Spark. SQL No Did you define a. NET UDF? . NET for Apache Spark operation tree Yes Interop between Spark and. NET
Performance – warm cluster runs for Pickling Serialization (Arrow will be tested in the future) Takeaway 2: Where UDF performance is critical, . NET is ~2 x faster than Python! Takeaway 1: Where UDF performance does not matter, . NET is on-par with Python
Cross Cloud Windows Ubuntu mac. OS Azure & AWS Databricks Cross platform AWS EMR Spark Azure HDI Spark
Author • Spark. NET Project creation • Dependency packaging • Language service • Sample code • Reference management • Spark local run • Spark cluster run (e. g. HDInsight) Run Extension to VSCode v Tap into VSCode for C# programming v Automate Maven and Spark dependency for environment setup v Facilitate first project success through project template and sample code Fix • Debug v Support Spark local run and cluster run v Integrate with Azure for HDInsight clusters navigation v Azure Databricks integration planned
More programming experiences in. NET (UDAF, UDT support, multilanguage UDFs) Idiomatic experiences for C# and F# (LINQ, Type Provider) Spark data connectors in. NET (e. g. , Apache Kafka, Azure Blob Store, Azure Data Lake) Tooling experiences (e. g. , Jupyter, VS Code, Visual Studio, others? ) Out-of-Box Experiences (Azure HDInsight, Azure Databricks, Cosmos DB Spark, SQL 2019 BDC, …) Go to https: //github. com/dotnet/spark and let us know what is important to you!
CREATE EXTERNAL DATA SOURCE My. ADLSGen 2 WITH (TYPE = Hadoop, LOCATION = ‘abfs: //<filesys>@<account_name>. dfs. core. windows. net’, CREDENTIAL = <Database scoped credential>); CREATE EXTERNAL FILE FORMAT Parquet. File WITH ( FORMAT_TYPE = PARQUET, DATA_COMPRESSION = 'org. apache. hadoop. io. compress. Gzip. Codec’, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE)); Once per store account (WASB, ADLS G 1, ADLS G 2) Once per file format, supports Parquet (snappy or Gzip), ORC, CSV/TSV CREATE EXTERNAL TABLE [dbo]. [Customer_import] ( [Sensor. Key] int NOT NULL, [Speed] float NOT NULL) WITH (LOCATION=‘/Dimensions/customer', DATA_SOURCE = My. ADLSGen 2, FILE_FORMAT = Parquet. File) Folder path
CREATE TABLE [dbo]. [Customer] WITH ( DISTRIBUTION = ROUND_ROBIN , CLUSTERED INDEX (customerid) ) AS SELECT * FROM [dbo]. [Customer_import] INSERT INTO [dbo]. [Customer] SELECT * FROM [dbo]. [Customer_import] WHERE <predicate to determine new data>
Useful links: • http: //github. com/dotnet/spark https: //aka. ms/Go. Dot. Net. For. Spark Website: • https: //dot. net/spark Available out-of-box on Azure HDInsight Spark You &. NET Running. NET for Spark anywhere— https: //aka. ms/Install. Dot. Net. For. Spark
https: //github. com/dotnet/spark https: //dot. net/spark https: //docs. microsoft. com/dotnet/spark https: //devblogs. microsoft. com/dotnet/introducing-net-for-apache-spark/ https: //www. slideshare. net/Michael. Rys Spark Language Interop Spark Proposal “. NET for Spark” Spark Project Proposal
https: //mybuild. microsoft. com
Thank you for attending Build 2019