Design Management of the JLAB Farms Ian Bird

Design & Management of the JLAB Farms Ian Bird, Jefferson Lab May 24, 2001 FNAL LCCWS

Overview • JLAB clusters – Aims – Description – Environment • Batch software • Management – Configuration – Maintenance – Monitoring • Performance monitoring • Comments

Clusters at JLAB - 1 • Farm – Support experiments – reconstruction, analysis – 250 ( 320) Intel Linux CPU ( + 8 Sun Solaris) • 6400 8000 SPECint 95 – Goals: • Provide 2 passes of 1 st level reconstruction at average incoming data rate (10 MB/s) • (More recently) provide analysis, simulation, and general batch facility – Systems • First phase (1997) was 5 dual Ultra 2 + 5 dual IBM 43 p • 10 dual Linux (PII 300) acquired in 1998 • Currently 165 dual PII/III (300, 450, 500, 750, 1 GHz) – ASUS motherboards, 256 MB, ~40 GB SCSI, IDE, 100 Mbit – First 75 systems towers, 50 2 u rackmount, 40 1 u (½u? ) • Interactive front-ends – Sun E 450’s, 4 -proc Intel Xeon, (2 each), 2 GB RAM, Gb Ethernet
 +")
First purchases, 9 duals per 24” rack Last summer, 16 duals (2 u) + 500 GB cache (8 u) per 19” rack Recently, 5 TB IDE cache disk (5 x 8 u) per 19” Intel Linux Farm
 – Existing clusters – in")
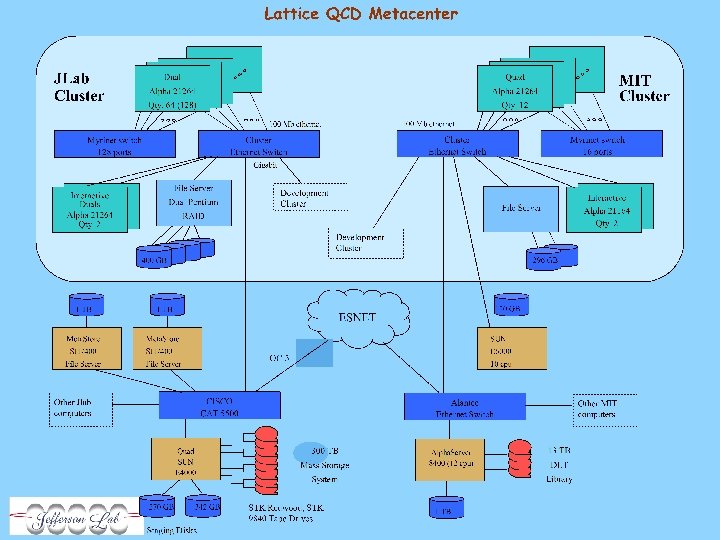
Clusters at JLAB - 2 • Lattice QCD cluster(s) – Existing clusters – in collaboration with MIT, at JLAB: • Compaq Alpha – 16 XP 1000 (500 MHz 21264), 256 or 512 MB, 100 Mbit – 12 Dual UP 2000 (667 MHz 21264), 256 MB, 100 Mbit • All have Myrinet interconnect • Front-end (login) machine has GB Ethernet, 400 GB fileserver for data staging and transfers MIT JLAB – Anticipated (funded) • 128 cpu (June 2001), Alpha or P 4(? ) in 1 u • 128 cpu (Dec/Jan ? ) – identical to 1 st 128 • Myrinet
, 2000 LQCD Clusters")
16 single Alpha 21264, 1999 12 dual Alpha (Linux Networks), 2000 LQCD Clusters
 – Net. App fileservers – NFS")
Environment • JLAB has central computing environment (CUE) – Net. App fileservers – NFS & CIFS • Home directories, group (software) areas, etc. – Centrally provided software apps • Available in – General computing environment – Farms and clusters – Managed desktops • Compatibility between all environments – home and group areas available in farm, library compatibility, etc. • Locally written software provides access to farm (and mass storage) from any JLAB system • Campus network backbone is Gigabit Ethernet, with 100 Mbit to physicist desktops, OC-3 to ESnet

Tape Servers DST/Cache File Servers 15 TB – RAID 0 Jefferson Lab Mass Storage and Farm Systems 2001 Farm Cache File Servers 4 x 400 GB DB Server Work File Servers 10 TB – RAID 5 From CLAS DAQ From Hall A, C DAQ 100 Mbit/s 1000 Mbit/s FCAL SCSI Batch and Interactive Farm
 • Pricing now")
Batch Software • Farm – Use LSF (v 4. 0. 1) • Pricing now acceptable – Manage resource allocation with • Job queues – Production (reconstruction, etc) – Low-priority (for simulations), High-priority (short jobs) – Idle (pre-emptable) • User + group allocations (shares) – Make full use of hierarchical shares - allows single undivided cluster to be used efficiently by many groups – E. g.

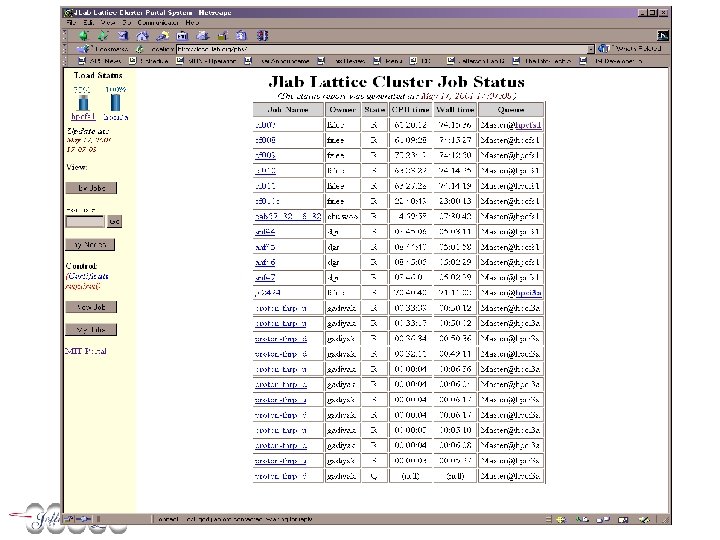
Batch software - 2 • Users do not use LSF directly, use Java client (jsub), that: – Is available from any machine (does not need LSF) – Provides missing functionality, e. g. • Submit 1000 jobs in 1 command • Fetches files from tape, pre-stages before job queued for execution (don’t block farm with jobs waiting for data), – Ensures efficient retrieval of files from tape - e. g. sort 1000 files by tape and by file no. on tape. – Web interface (via servlet) to monitor job status and progress (as well as host, queue, etc. )

View job status

View host status

Batch software - 3 • LQCD clusters use PBS – JLAB written scheduler • 7 stages – mimic LSF hierarchical behaviour – Users access PBS commands directly – Web interface (portal) – authorization based on certificates • Used to submit jobs between JLAB & MIT clusters

Batch software - 4 • Future – Combine jsub & LQCD portal features to wrap both LSF and PBS – XML-based description language – Provide web-interface toolkit to experiments to enable them to generate jobs based on expt. run data – In context of PPDG

Cluster management • Configuration – Initial configuration • Kickstart, 2 post-install scripts for configuration, sw install (LSF etc), driven by a floppy • Looking at PXE – DHCP (available on newer motherboards) – Avoids need for floppy – just power on – System working (last week) – Software: PXE standard bootprom (www. nilo. org/docs/pxe. html) – talks to DHCP, » bpbatch – pre-boot shell (www. bpbatch. org) - downloads vmlinux, kickstart etc • Alphas configured “by hand + kickstart” – Updates etc. • Autorpm (especially for patches) • New kernels – by hand with scripts • OS upgrades – Rolling upgrades – use queues to manage transition • Missing piece: – Remote, network-accessible console screen access • Have used serial console, KVM switches, monitor on a cart … • Linux Networks Alphas have remote power management – don’t use!

System monitoring • Farm systems – LM 78 to monitor temp + fans via /proc • This was our largest failure mode for Pentiums – Mon (www. kernel. org/software/mon) • Used extensively for all our systems – page “on-call” • For batch farm checks mostly – fan, temp, ping – Mprime (prime number search) has checks on memory and arithmetic integrity • Used in initial system burn-in

Monitoring

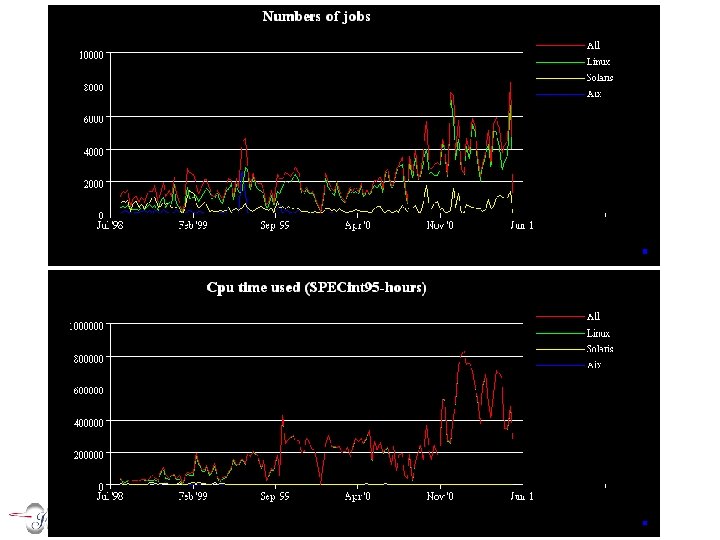
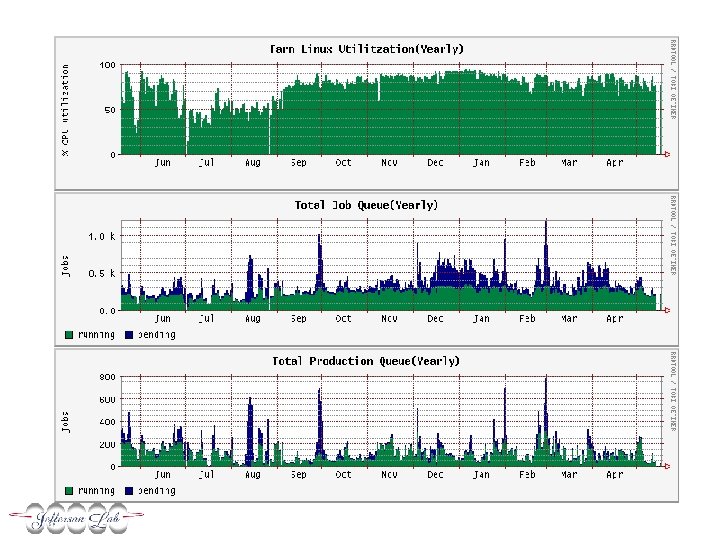
Performance monitoring • Use variety of mechanisms – Publish weekly tables and graphs based on LSF statistics – Graphs from mrtg/rrd • Network performance, #jobs, utilization, etc

Comments & Issues • Space – very limited – Installing a new STK silo, moved all sys admins out • Now have no admins in same building as machine room – Plans to build a new Computer Center … • Have always been lights-out

Future • Accelerator and experiment upgrades – – Expect first data in 2006, full rate 2007 100 MB/s data acquisition 1 – 3 PB/year (1 PB raw, > 1 PB simulated) Compute clusters: • • Level 3 triggers Reconstruction Simulation Analysis – PWA can be parallelized, but needs access to very large reconstructed and simulated datasets • Expansion of LQCD clusters – 10 Tflops by 2005
- Slides: 24