Deep Inside TSQL Query Programming Kind 511dreamwiz com
")
 맥스무비 연구개발 팀장 l Deep Inside T-SQL 테크닉(영진닷컴) l SQL")




















, @n int, @p varchar(255)")



")

![쿼리가 어떻게 해석되는가? 1. 쿼리 실행 계획 확인 [Trivial plan optimization] 2. 쿼리 단순화](https://slidetodoc.com/presentation_image/1d8b46b9beb5ed1834f293da2b91bccf/image-40.jpg "쿼리가 어떻게 해석되는가? 1. 쿼리 실행 계획 확인 [Trivial plan optimization] 2. 쿼리 단순화")

![쿼리가 어떻게 해석되는가? 쿼리 재사용[ Trivial plan optimization] 단계 실행 쿼리 파싱 시간 1](https://slidetodoc.com/presentation_image/1d8b46b9beb5ed1834f293da2b91bccf/image-46.jpg "쿼리가 어떻게 해석되는가? 쿼리 재사용[ Trivial plan optimization] 단계 실행 쿼리 파싱 시간 1")











![서브 쿼리 평면화 [Subquery Flattening] 서브쿼리이지만 조인으로 처리됨 select pub_name from pubs. dbo. publishers](https://slidetodoc.com/presentation_image/1d8b46b9beb5ed1834f293da2b91bccf/image-64.jpg "서브 쿼리 평면화 [Subquery Flattening] 서브쿼리이지만 조인으로 처리됨 select pub_name from pubs. dbo. publishers")
![서브 쿼리 평면화 [Subquery Flattening]](https://slidetodoc.com/presentation_image/1d8b46b9beb5ed1834f293da2b91bccf/image-65.jpg "서브 쿼리 평면화 [Subquery Flattening]")
![서브 쿼리 평면화 [Subquery Flattening] select * from some_table whre column in (수십건) select](https://slidetodoc.com/presentation_image/1d8b46b9beb5ed1834f293da2b91bccf/image-66.jpg "서브 쿼리 평면화 [Subquery Flattening] select * from some_table whre column in (수십건) select")

 + '-'")









 total")























 select @title_ids")






인 경우만을 조회 select *, Substring(', '+x.")



- Slides: 128
Deep Inside T-SQL Query Programming 손 호성 (Kind 511@dreamwiz. com)
강사 소개 l 현) 맥스무비 연구개발 팀장 l Deep Inside T-SQL 테크닉(영진닷컴) l SQL Server 2000 Bible (영진닷컴) l Practical Database Design (삼각형프레스) l SQL Megazine “Deep inside SQL Server 2000” (From 2001. 04~)
Agenda • The Query • Query Components • Join & Subquery Architecture • Query Optimizer • Real-world Technique
The Query
Query Components
몇 개의 SQL 키워드로 모든 쿼리를 해결 SELECT select_list FROM table_source [ WHERE search_condition ] [ GROUP BY group_by_expression ] [ HAVING search_condition ] [ ORDER BY order_expression [ ASC | DESC ] ]
Think Different !!!
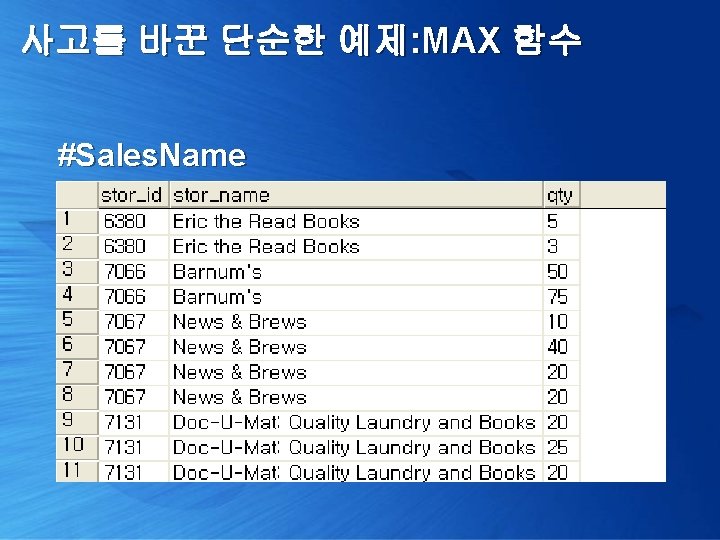
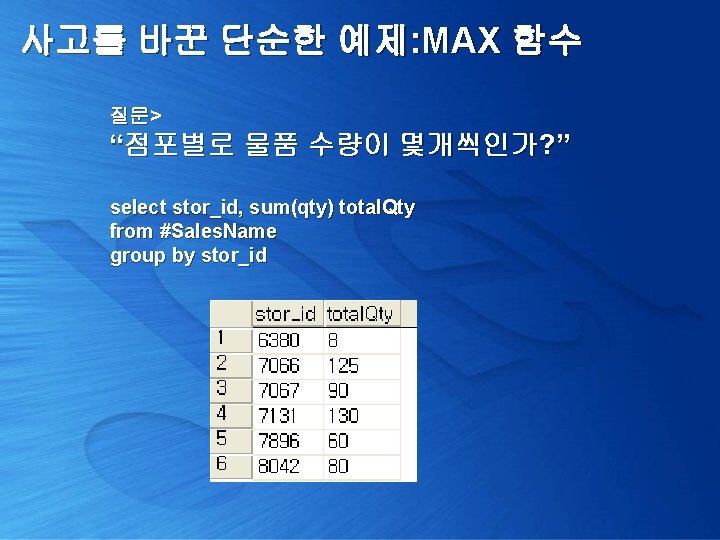
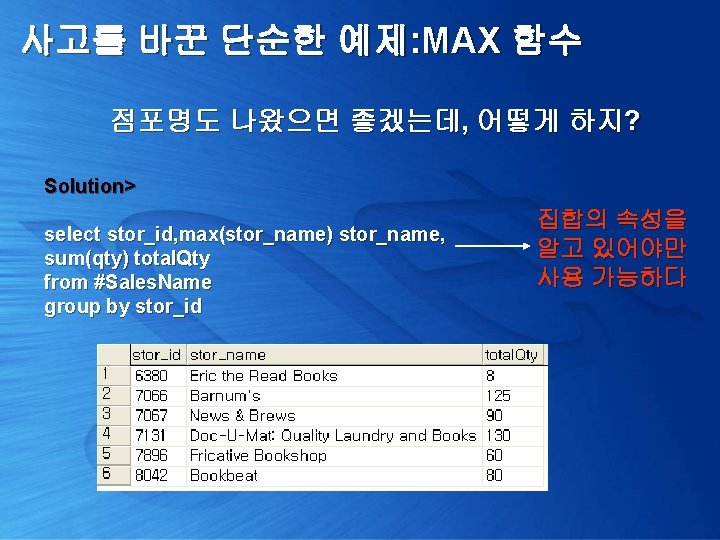
사고를 바꾼 단순한 예제: MAX 함수 점포명도 나왔으면 좋겠는데, 어떻게 하지? 1> select x. stor_id, y. stor_name, x. total. Qty from ( select stor_id, sum(qty) total. Qty from #Sales. Name group by stor_id ) x left outer join pubs. dbo. stores y on x. stor_id = y. stor_id 외부 조인 2> select stor_id, stor_name, sum(qty) from #Sales. Name group by stor_id, stor_name 잘못된 결과
SELECT 구성요소의 의미 v 집합의 원소를 선택 SELECT select_list v 원본 집합을 선택 FROM table_source [ WHERE search_condition ] v 데이터 블럭을 찾아가는 경로 v 집합을 요약 [ GROUP BY group_by_expression ] [ HAVING search_condition ] v 요약된 결과를 걸러주는 역할 [ ORDER BY order_expression [ ASC | DESC ] ] v 각 사건들의 순서를 지정
Count 처럼 사용된 Sum select Customer. ID, SUM((Case when Ship. Country = 'USA' then 1 else 0 end)) USA_Total. Orders, SUM((Case when Ship. Country = 'UK' then 1 else 0 end)) UK_Total. Orders from Northwind. . Orders group by Customer. ID order by 2 desc, 3 desc
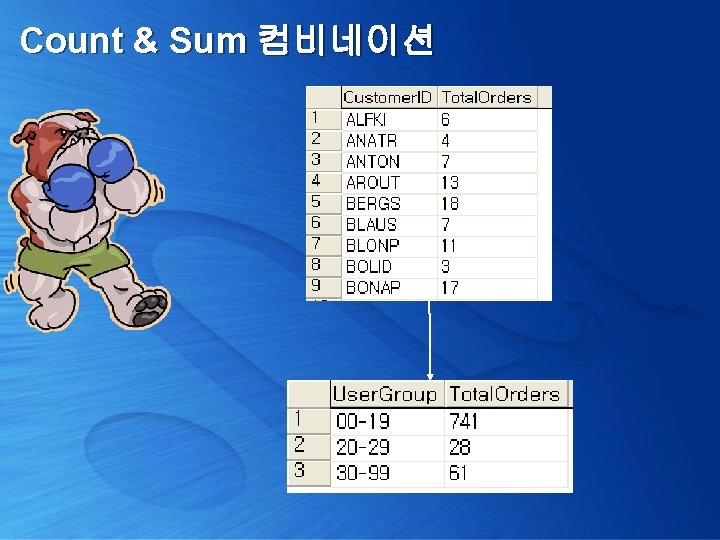
Count & Sum 컴비네이션 select (case when x. Total. Orders < 20 then '00 -19' when x. Total. Orders >= 20 and x. Total. Orders < 30 then '20 -29' when x. Total. Orders >= 30 then '30 -99' end) User. Group, Sum(x. Total. Orders) Total. Orders from ( select Customer. ID, Count(Order. ID) Total. Orders from Northwind. . Orders group by Customer. ID )x group by (case when x. Total. Orders < 20 then '00 -19' when x. Total. Orders >= 20 and x. Total. Orders < 30 then '20 -29' when x. Total. Orders >= 30 then '30 -99' end)
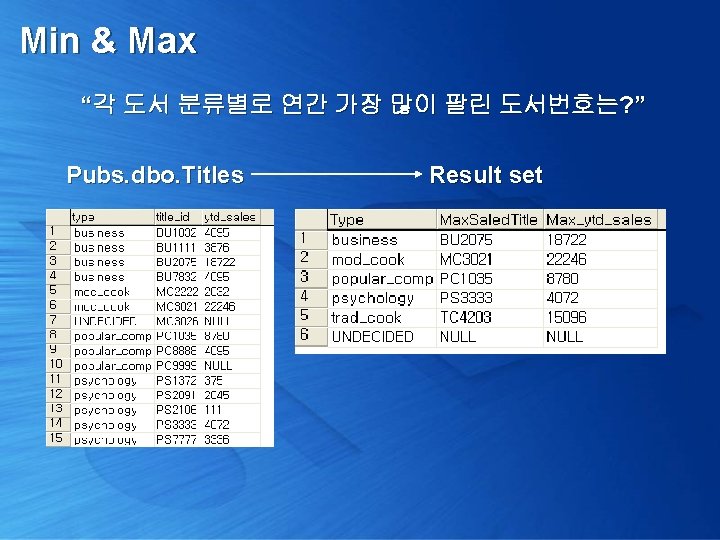
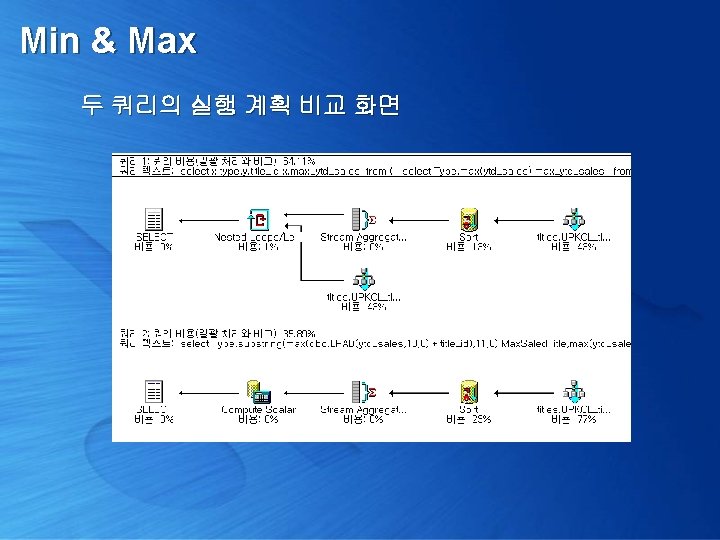
Min & Max “각 도서 분류별로 연간 가장 많이 팔린 도서번호는? ” 이게 단순한 Group By 쿼리일까? select Type, max(ytd_sales) max_ytd_sales from pubs. dbo. titles group by Type 없다!!! 도서번호가
Min & Max “각 도서 분류별로 연간 가장 많이 팔린 도서번호는? ” select x. type, y. title_id, x. max_ytd_sales from ( select Type, max(ytd_sales) max_ytd_sales from pubs. dbo. titles group by Type ) as x left outer join pubs. dbo. titles as y on x. type = y. type and x. max_ytd_sales = y. ytd_sales
Min & Max “각 도서 분류별로 연간 가장 많이 팔린 도서번호는? ” select Type, substring( max( dbo. LPAD(ytd_sales, 10, 0) + title_id ) , 11, 6) Max. Saled. Title, max(ytd_sales) Max_ytd_sales from pubs. dbo. titles group by type
Min & Max LPad Function CREATE FUNCTION LPAD( @s varchar(255), @n int, @p varchar(255) ) returns varchar(255) as BEGIN return Is. NULL(REPLICATE(@p, @n-LEN(@s)), '')+@s END select 'P' + dbo. LPad(37985, 9, '0') -----------------------P 000037985
Min & Max 수치를 고정 문자열로 변환하면 정렬 순서는 동일함 select type, dbo. LPAD(ytd_sales, 10, 0) ytd_sales, title_id from pubs. dbo. titles order by type, ytd_sales desc, title_id
Min & Max 두 필드를 결합해도 정렬 순서는 그대로 유지 select type, dbo. LPAD(ytd_sales, 10, 0) + title_id ytd_sales_title_id from pubs. dbo. titles order by type, ytd_sales_title_id desc
Min & Max 결합된 컬럼을 분리하면 원래의 값을 찾아내는 것이 가능 select Type, substring(max(dbo. LPAD(ytd_sales, 10, 0) + title_id), 11, 6) Max. Saled. Title, max(ytd_sales) Max_ytd_sales from pubs. dbo. titles group by type
Min & Max 만일 뒤의 값이 수치와 같이 고정되지 않은 값이라면 select type, max(ytd_sales) max_ytd_sales, (max(ytd_sales + price / 100000) - max(ytd_sales)) * 100000 price from pubs. dbo. titles group by type
Query Optimizer
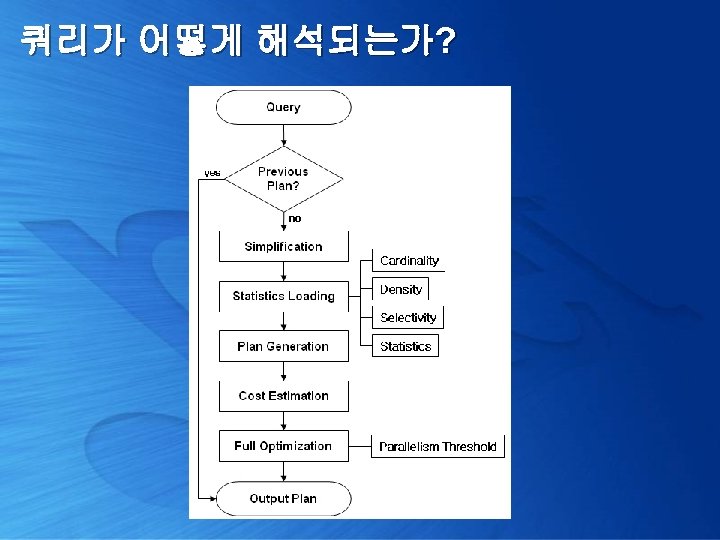
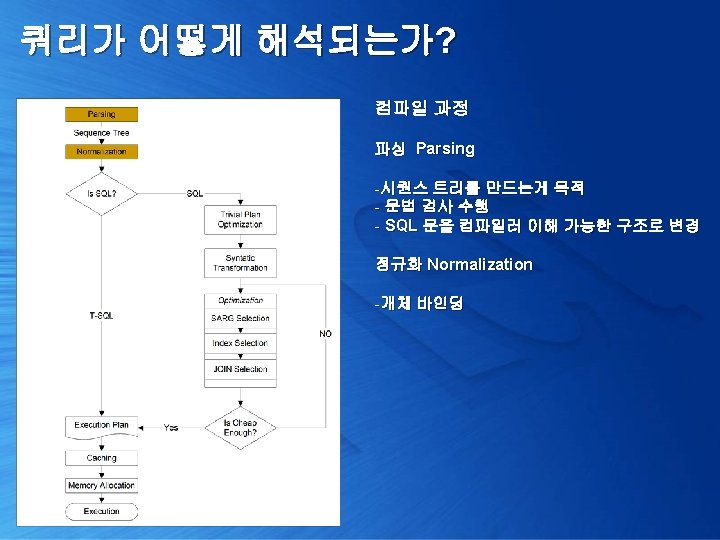
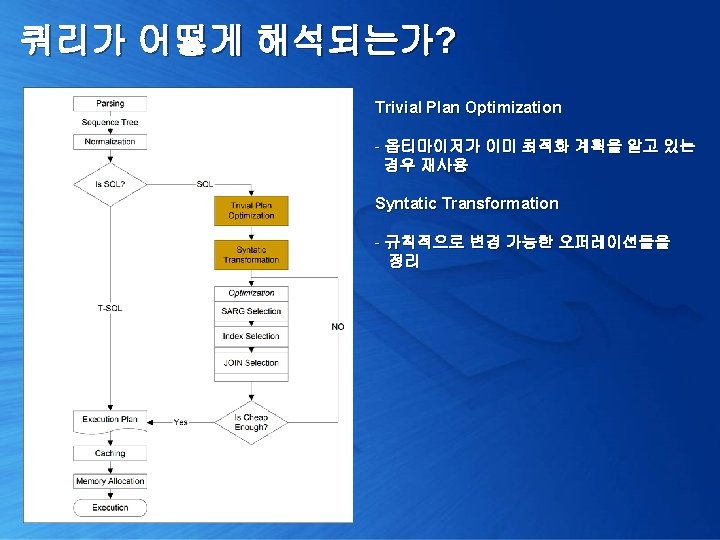
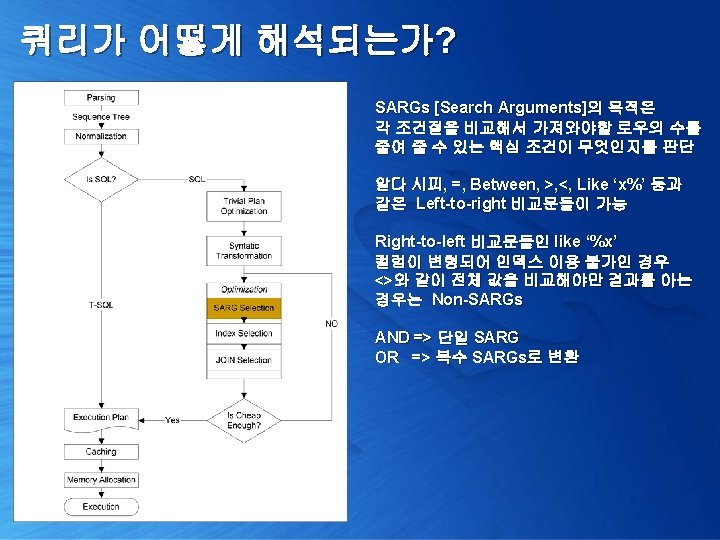
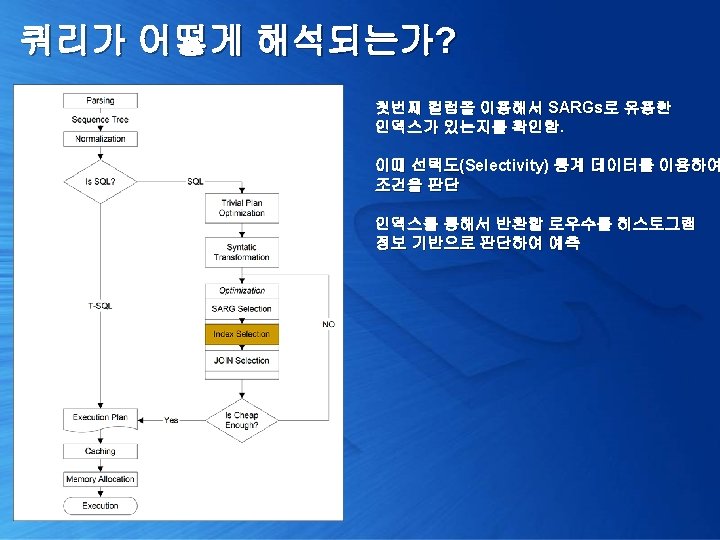
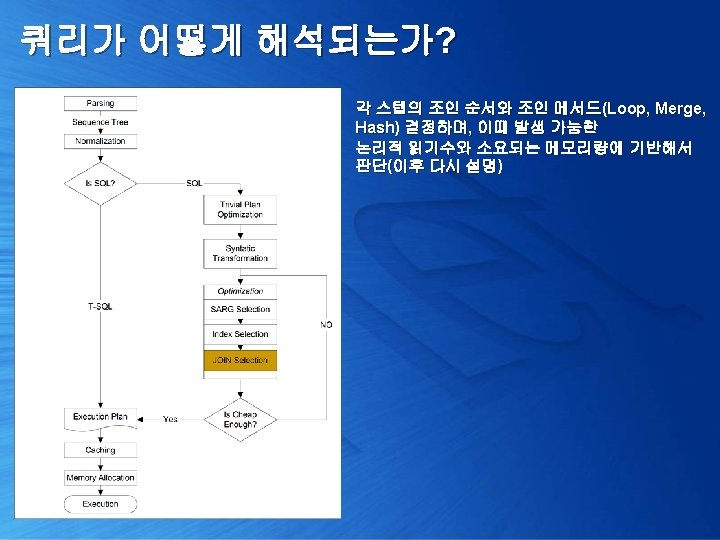
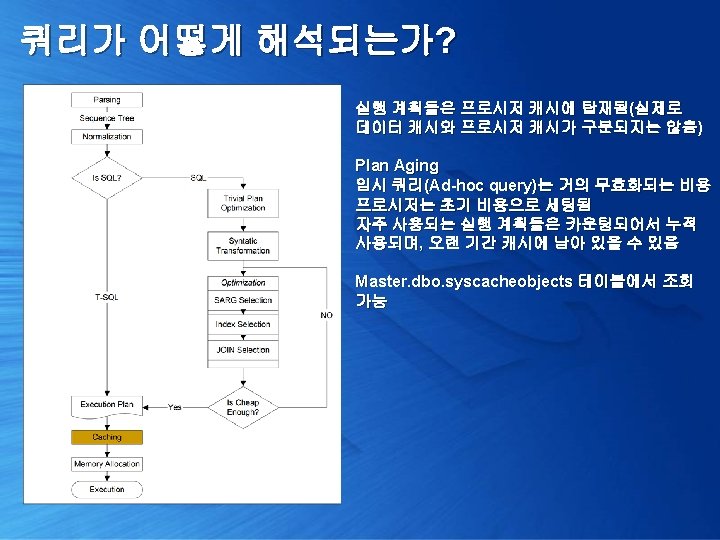
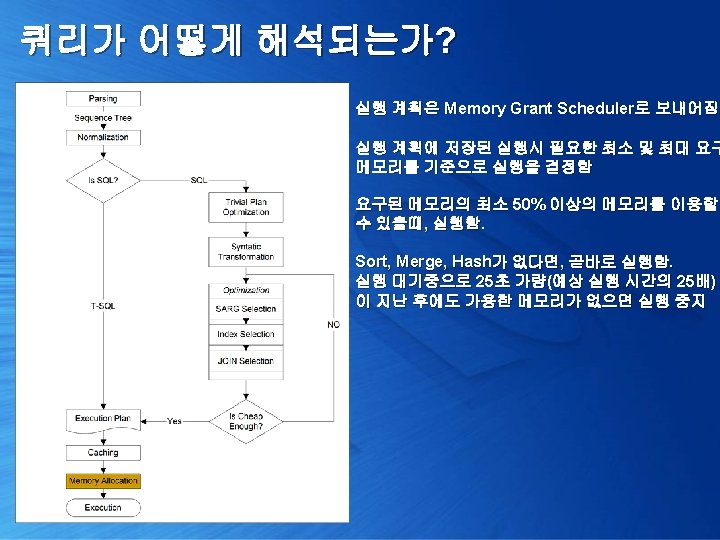
쿼리가 어떻게 해석되는가? 1. 쿼리 실행 계획 확인 [Trivial plan optimization] 2. 쿼리 단순화 및 통계 정보 로딩 [Simplification & Stats Loading] 3. 비용 산정 [Cost Estimation] 4. 최종 최적화 수행 [Full Optimization]
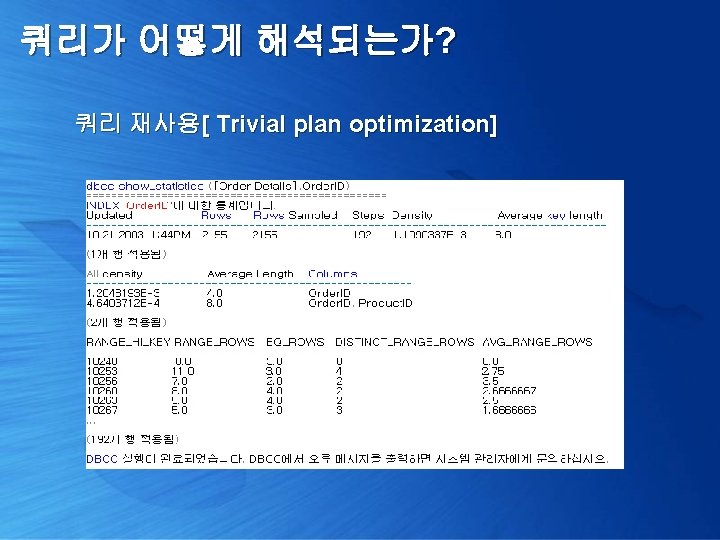
쿼리가 어떻게 해석되는가? 쿼리 재사용[ Trivial plan optimization] 단계 실행 쿼리 파싱 시간 1 select * from pubs. dbo. employee 63 2 select * from pubs. dbo. employee 0 3 select * from employee 46 4 select * from pubs. dbo. employee where emp_id = 'A-C 71970 F' 46 5 select * from pubs. dbo. employee where emp_id = 'AMD 15433 F' 0 6 select * from PUBS. DBO. EMPLOYEE where emp_id = 'AMD 15433 F' 45 7 select * from PUBS. DBO. EMPLOYEE where EMP_ID = 'AMD 15433 F' 43 8 Cache. Proc 'A-C 71970 F' 47 9 Cache. Proc 'AMD 15433 F' 0 10 exec Cache. Proc 'AMD 15433 F' 0 11 CACHEPROC 'AMD 15433 F' 0
Join Architecture
Join Method : Summary
Join Method : Nested Loop For i=1 To 100 Some Code. . . Next Loop 범위를 탐색 Nested Loop For i=1 To 100 두개의 범위를 비교 For j=1 To 100 If i=J Then. . . Some Code. . . Next
Join Method : Nested Loop
Join Method : Sort Merge
Join Method : Hash Match
Subquery Architecture
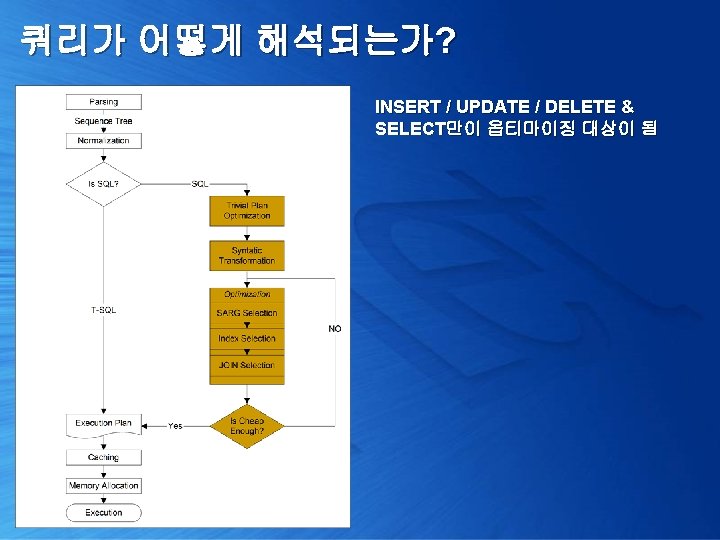
실체화된 서브쿼리 일반적인 서브쿼리로 값이 상수화되어서 처리 select pub_name from pubs. dbo. publishers where pub_id in ('0877') select pub_name from pubs. dbo. publishers where pub_id = ('0877') select title from pubs. dbo. titles where ytd_sales = (select max(ytd_sales) from pubs. dbo. titles)
서브 쿼리 평면화 [Subquery Flattening] 서브쿼리이지만 조인으로 처리됨 select pub_name from pubs. dbo. publishers where pub_id in ( select pub_id from pubs. dbo. titles where type = 'business‘ )
서브 쿼리 평면화 [Subquery Flattening]
서브 쿼리 평면화 [Subquery Flattening] select * from some_table whre column in (수십건) select * from some_table whre column in (수십만건) 일반적으로 조인으로 처리되는 것이 비용이 저렴
T-SQL Common Technique
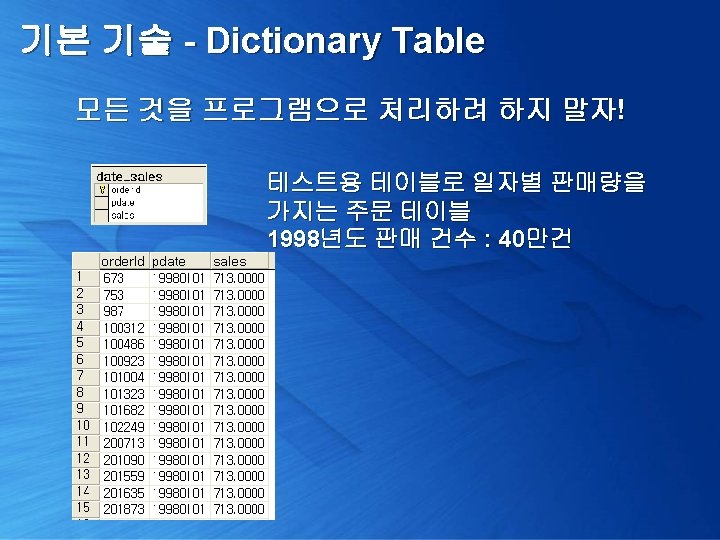
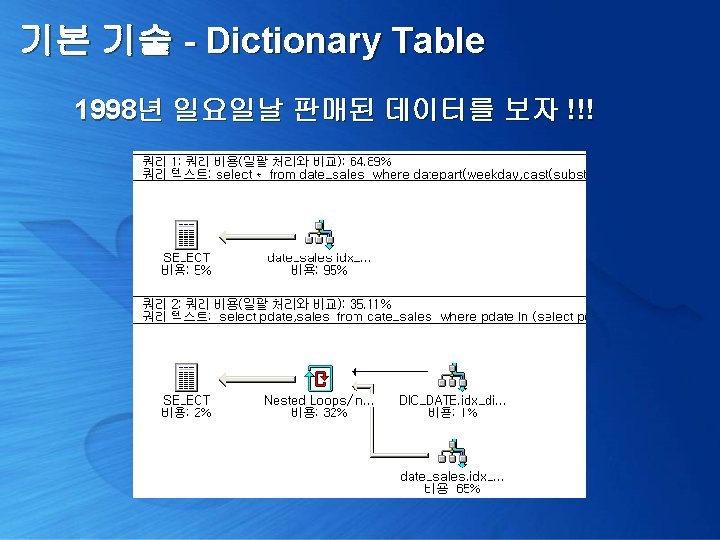
기본 기술 - Dictionary Table select datepart( weekday, cast( substring(pdate, 1, 4) + '-' + substring(pdate, 5, 2) + '-' + substring(pdate, 7, 2) as smalldatetime) ) 요일, avg(sales) 평균판매량 from date_sales where pdate between '19980101' and '19981231' group by datepart(weekday, cast(substring(pdate, 1, 4) + '-' + substring(pdate, 5, 2) + '-' + substring(pdate, 7, 2) as smalldatetime)) order by 1 1998년도 요일별 평균 판매량?
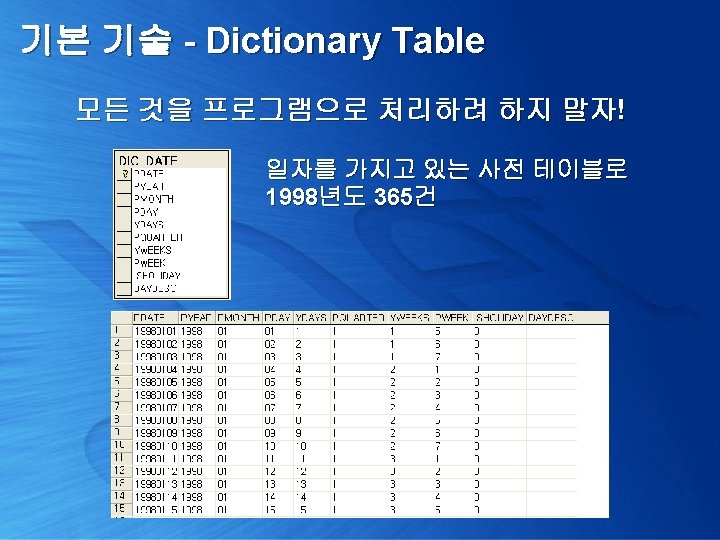
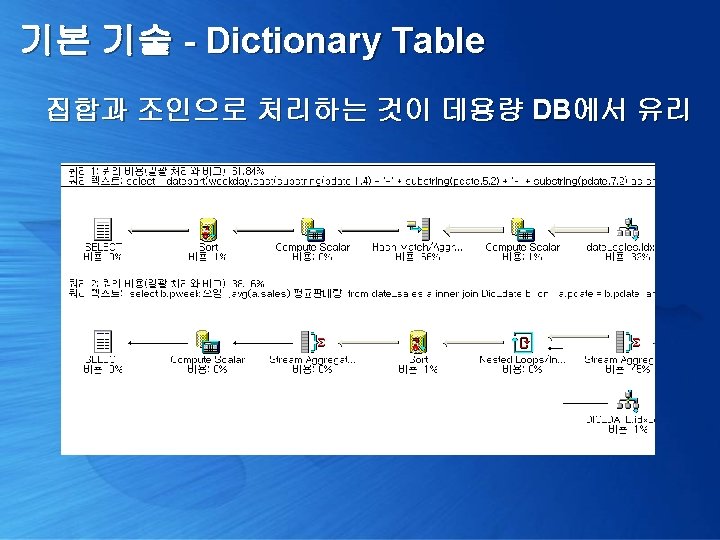
기본 기술 - Dictionary Table 프로그램으로 해결하려 하지 말고, 새로운 집합을 만들어서 해결 select b. pweek 요일 , avg(a. sales) 평균판매량 from date_sales a inner join Dic_date b on a. pdate = b. pdate and a. pdate between '19980101' and '19981231' group by b. pweek order by 1
기본 기술 - Dictionary Table 1998년 일요일날 판매된 데이터를 보자 !!! select * from date_sales where datepart(weekday, cast(substring(pdate, 1, 4) + '-' + substring(pdate, 5, 2) + '-' + substring(pdate, 7, 2) as smalldatetime)) = 1 and pdate between '19980101' and '19981231‘ select pdate, sales from date_sales where pdate in ( select pdate from dic_date where pweek =1 and pdate between '19980101' and '19981231')
기본 기술 - Case When SQL에 동적인 힘을 부여하는 문장 select ( case type when 'UNDECIDED' then 'business' else type end), sum(ytd_sales) from pubs. dbo. titles group by ( case type when 'UNDECIDED' then 'business' else type end)
기본 기술 - Case When SQL에 동적인 힘을 부여하는 문장 select * from pubs. dbo. titles where ytd_sales >= ( case type when 'UNDECIDED' then 0 else 2000 end) (ytd_sales >= 0 and type=‘UNDECIDED’) or (ytd_sales >= 2000 and type <> ‘UNDECIDED’)
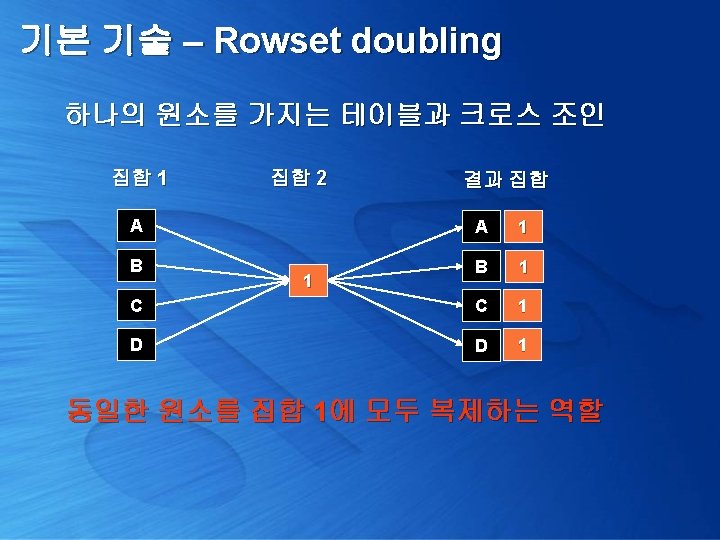
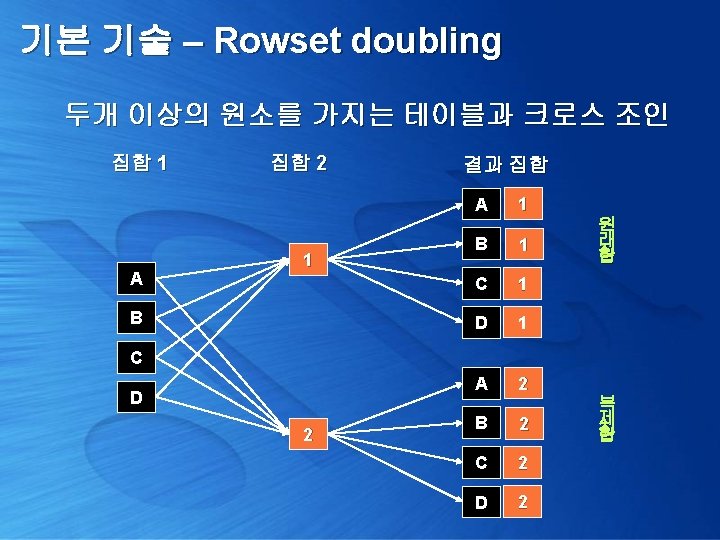
기본 기술 – Rowset doubling 하나의 원소를 가지는 테이블과 크로스 조인 create table #Dbl. Test(c 1 char(1)) insert #Dbl. Test values('A') insert #Dbl. Test values('B') insert #Dbl. Test values('C') select a. c 1, b. c 2 from #Dbl. Test a, (select 1 c 2) b c 1 c 2 ----------A 1 B 1 C 1
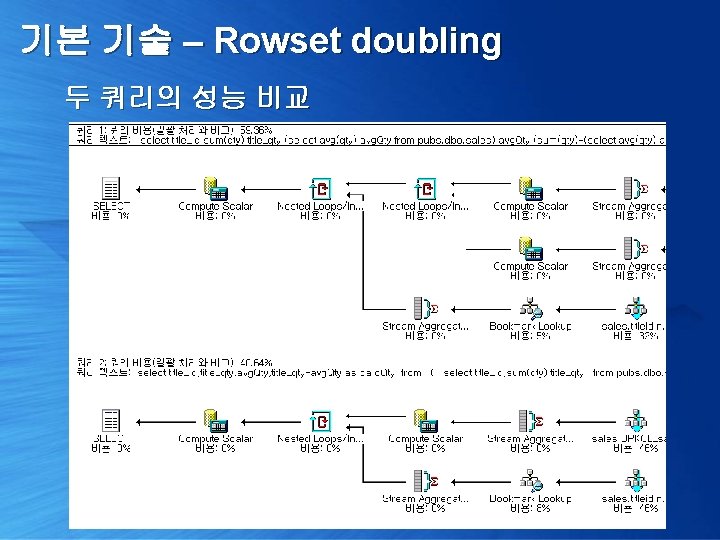
기본 기술 – Rowset doubling 일반적으로 한 쿼리에서 하나의 서브쿼리 값을 연속으로 사용해야 하는 경우 select title_id, sum(qty) title_qty, (select avg(qty) avg. Qty from pubs. dbo. sales) avg. Qty, (sum(qty)-(select avg(qty) avg. Qty from pubs. dbo. sales)) calc. Qty from pubs. dbo. sales group by title_id
기본 기술 – Rowset doubling 이를 크로스 조인하면 요소 값을 복제 하여 사용 select title_id, title_qty, avg. Qty, title_qty-avg. Qty as calc. Qty from ( select title_id, sum(qty) title_qty from pubs. dbo. sales group by title_id ) as a, ( select avg(qty) avg. Qty from pubs. dbo. sales ) as b
기본 기술 – Rowset doubling 존재하지 않는 값의 발생 !!! create table Customer. Area ( area varchar(10), gender varchar(2), something int ) insert Customer. Area values('서울', '남', 100) values('부산', '여', 150) values('청주', '여', 200) values('서울', '여', 120) values('경기', '남', 118)
기본 기술 – Rowset doubling 지역별 성별 인구수를 집계하자. select area, gender, sum(something) total from Customer. Area group by area, gender area gender total ----------경기 남 118 서울 남 100 부산 여 150 서울 여 120 청주 여 200
기본 기술 – Rowset doubling 이를 크로스 조인하면 요소 값을 복제 하여 사용 select a. area, a. gender, b. gender, a. something from Customer. Area a , (select '남' gender union all select '여') b area gender something ------ -----서울 남 남 100 서울 남 여 100 부산 여 남 150 부산 여 여 150 청주 여 남 200 청주 여 여 200 서울 여 남 120 서울 여 여 120 경기 남 남 118 경기 남 여 118
기본 기술 – Rowset doubling 이를 크로스 조인하면 요소 값을 복제 하여 사용 select a. area, b. gender, sum(case a. gender when b. gender then something else 0 end) Tot. Something from Customer. Area a , (select '남' gender union all select '여') b group by a. area, b. gender order by 1, 2 Area Gender Tot. Something 경기 남 118 경기 여 0 부산 남 0 부산 여 150 서울 남 100 서울 여 120 청주 남 0 청주 여 200
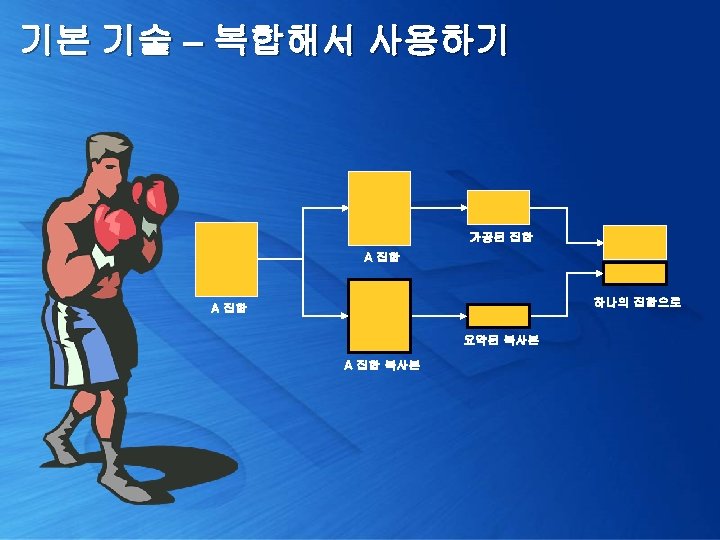
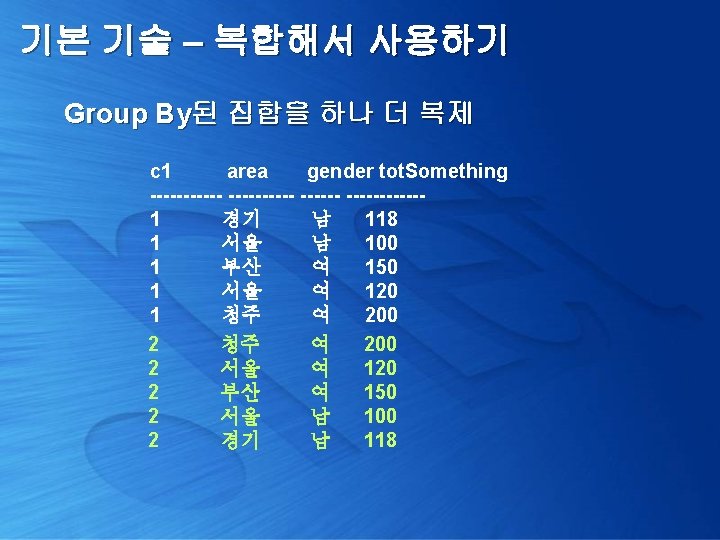
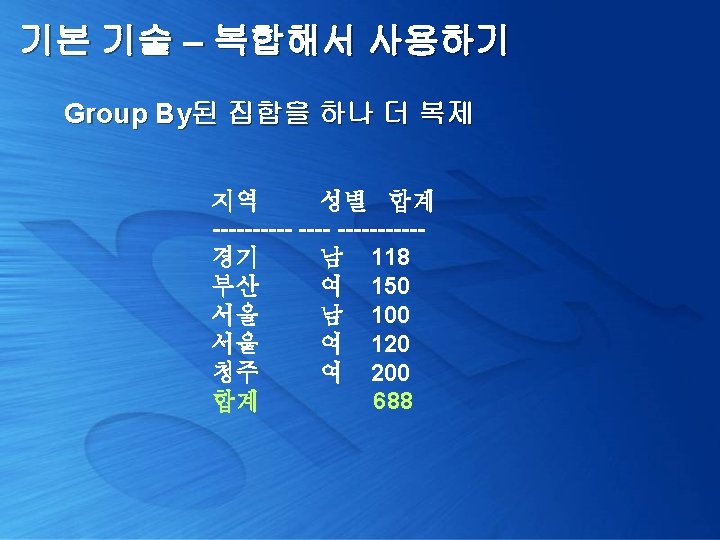
기본 기술 – 복합해서 사용하기 Group By된 집합을 하나 더 복제 select y. c 1, x. area, x. gender, x. tot. Something from ( select area, gender, sum(something) tot. Something from Customer. Area group by area, gender ) x, (select 1 c 1 union all select 2) y order by y. c 1
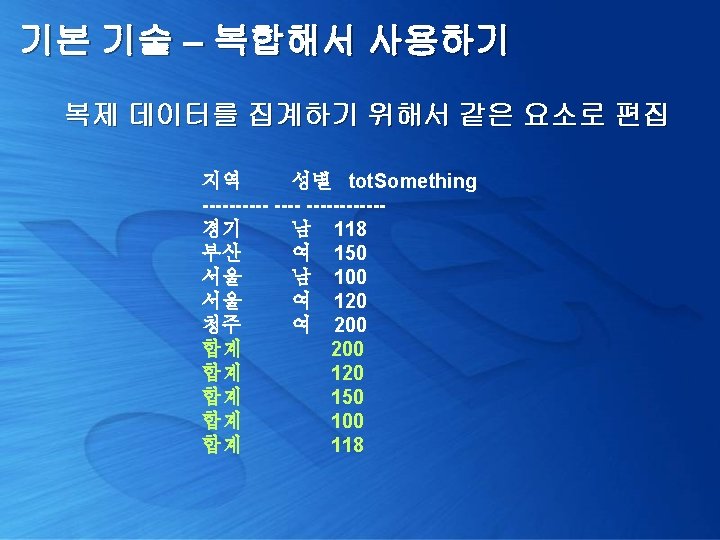
기본 기술 – 복합해서 사용하기 복제 데이터를 집계하기 위해서 같은 요소로 편집 select (case y. c 1 when 2 then '합계' else x. area end) 지역, (case y. c 1 when 2 then ' ' else x. gender end) 성별, x. tot. Something from ( select area, gender, sum(something) tot. Something from Customer. Area group by area, gender ) x, (select 1 c 1 union all select 2) y order by 1, 2
기본 기술 – 복합해서 사용하기 Group By된 집합을 하나 더 복제 select (case y. c 1 when 2 then '합계' else x. area end) 지역, (case y. c 1 when 2 then ' ' else x. gender end) 성별, sum(x. tot. Something) 합계 from ( select area, gender, sum(something) tot. Something from Customer. Area group by area, gender ) x, (select 1 c 1 union all select 2) y group by (case y. c 1 when 2 then 'TOT' else 'PER' end), (case y. c 1 when 2 then '합계' else x. area end), (case y. c 1 when 2 then ' ' else x. gender end)
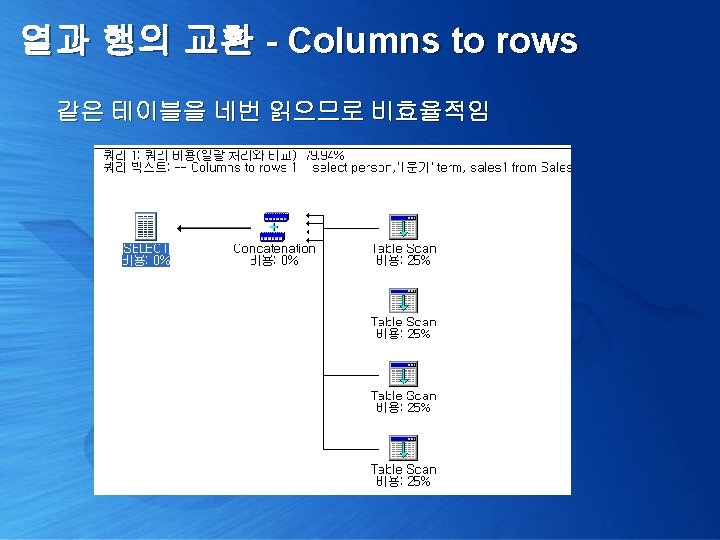
열과 행의 교환 - Columns to rows Sales. Person table Person Philip Brown Lay Chris Mckena Branda Jornan Sales 1 Sales 2 Sales 3 Sales 4 100 80 200 108 0 15 18 120 79 280 100 30 20 140 100 460 109 80 40 160 90 110 500 125 200 55 300
열과 행의 교환 - Columns to rows Sales. Person 테이블의 모든 컬럼을 로우로 펼친다면 >> 가장 쉬운 방법은 Union all select person, '1분기' term, sales 1 from Sales. Person union all select person, '2분기' term, sales 2 from Sales. Person union all select person, '3분기' term, sales 3 from Sales. Person union all select person, '4분기' term, sales 4 from Sales. Person
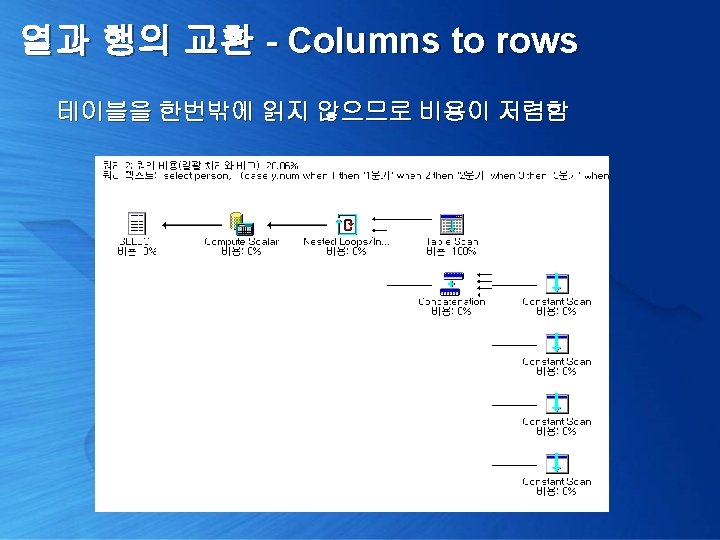
열과 행의 교환 - Columns to rows Sales. Person 테이블의 모든 컬럼을 로우로 펼친다면 >> 컬럼 수만큼의 복제를 이용할 수 있음 select person, (case y. num when 1 then '1분기' when 2 then '2분기' when 3 then '3분기' when 4 then '4분기' end) term, (case y. num when 1 then sales 1 when 2 then sales 2 when 3 then sales 3 when 4 then sales 4 end) sales from Sales. Person x, (select 1 num union all select 2 union all select 3 union all select 4) y
열과 행의 교환 - Columns to rows 앞의 예제를 변형하여, 각 요소를 두번씩 복제하고, 1, 2분기 3, 4분기로 표시하는 예제 select person, (case y. num when 1 then '1, 2분기' when 2 then '3, 4분기' end) term, (case y. num when 1 then sales 1 when 2 then sales 3 end) sales 1, (case y. num when 1 then sales 2 when 2 then sales 4 end) sales 2 from Sales. Person x, (select 1 num union all select 2) y
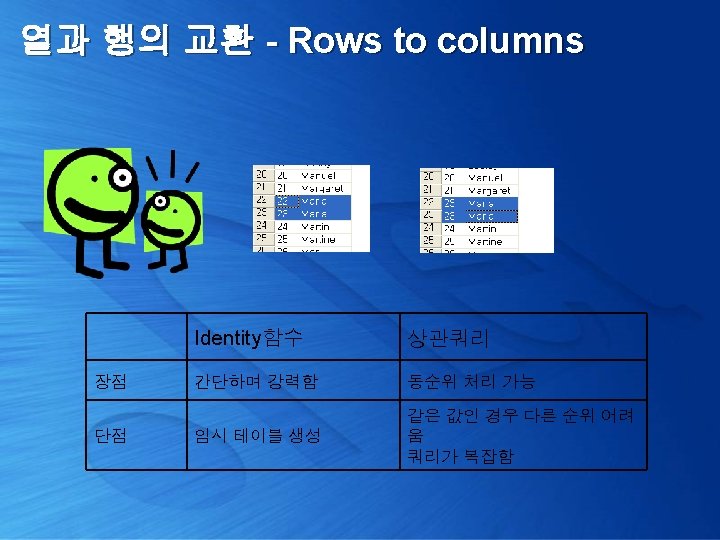
열과 행의 교환 - Rows to columns 우선, 테이블 자체에 정렬된 시퀀스가 존재해야만 한다. 가장, 간단하면서 강력한 시퀀스 생성 기법 : Identity 함수 select top 100 percent identity(int, 1, 1) num, fname into #Seq. Emp from pubs. dbo. employee order by fname
열과 행의 교환 - Rows to columns 상관 쿼리를 이용한 Ranking 테크닉 select num= ( select count(*) from pubs. dbo. employee where fname <= x. fname ), fname from pubs. dbo. employee x order by fname
열과 행의 교환 - Rows to columns 일련의 로우들을 그룹화하기 위한 키를 생성 select ceiling(num/4. 0) ceil_num, fname from #Seq. Emp Ceil_num Num Fname 1 1 Anabela 1 2 Ann 1 3 Annette 1 4 Aria 2 5 Carine 2 6 Carlos 2 7 Daniel 2 8 Diego
열과 행의 교환 - Rows to columns 각 그룹내의 원소들을 분리하기 위해서 모듈라 연산 select ceiling(num/4. 0) ceil_num, (num%4) mod_num, fname from #Seq. Emp Ceil_num Mod_num Num Fname 1 1 1 Anabela 1 2 2 Ann 1 3 3 Annette 1 0 4 Aria 2 1 5 Carine 2 2 6 Carlos 2 3 7 Daniel 2 0 8 Diego
열과 행의 교환 - Rows to columns 분리된 값들을 각각의 컬럼들로 이동 select ceiling(num/4. 0) ceil_num, (num%4) mod_num, (case (num%4) when 1 then fname end) fname 1, (case (num%4) when 2 then fname end) fname 2, (case (num%4) when 3 then fname end) fname 3, (case (num%4) when 0 then fname end) fname 4 from #Seq. Emp
열과 행의 교환 - Rows to columns 실제 값이 아닌 경우에는 NULL 값으로 표시됨 Ceil_num Mod_num Num Fname 1 Fname 2 Fname 3 Fname 4 1 1 1 Anabela NULL 1 2 2 NULL Ann NULL 1 3 3 NULL Annette NULL 1 0 4 NULL Aria 2 1 5 Carine NULL 2 2 6 NULL Carlos NULL 2 3 7 NULL Daniel NULL 2 0 8 NULL Diego
열과 행의 교환 - Rows to columns 각 그룹에서 Max 값을 구하도록 쿼리 조정 select ceiling(num/4. 0) ceil_num, max(case (num%4) when 1 then fname end) fname 1, max(case (num%4) when 2 then fname end) fname 2, max(case (num%4) when 3 then fname end) fname 3, max(case (num%4) when 0 then fname end) fname 4 from #Seq. Emp group by ceiling(num/4. 0)
열과 행의 교환 - Rows to columns 각 그룹에서 Max 값을 구하도록 쿼리 조정 Ceil_num Fname 1 Fname 2 Fname 3 Fname 4 1 Anabela Annette Aria 2 Carine Carlos Daniel Diego 3 Elizabeth Francisco Gary Helen 4 Helvetius Howard Janine Karin 5 Karla Lesley Manuel 6 Margaret Maria Martin 7 Martine Mary Matti Miguel 8 Palle Paolo Patricia Paul 9 Paula Pedro Peter Philip 10 Pirkko Rita Roland Sven 11 Timothy Victoria Yoshi NULL Laurence
컴비네이션 - Ranking & Ceiling 각 페이지 그룹으로 나누어 히스토그램 값 구하기 1. 상관쿼리로 된 Ranking select ceiling(rank/20. 0), min(num), max(num) from ( select num, rank=(select count(*) from Temp. Brd where num <= x. num) from Temp. Brd x ) as a group by ceiling(rank/20. 0) Temp. Brd에는 10만건의 데이터 order by 1 2. Identity를 사용하는 Ranking select identity(bigint, 1, 1) rank, num into New. Temp. Brd from Temp. Brd
컴비네이션 - Ranking & Ceiling 상관 쿼리 비용은 99. 99%, Identity는 0. 01%
컴비네이션 - Ranking & Ceiling 20개의 로우 단위로 그룹화하여 시작 키와 종료 키 조회 select ceiling(rank/20. 0) Range. Grp, min(num) Range. Low, max(num) Range. Hi from New. Temp. Brd group by ceiling(rank/20. 0) order by 1
컴비네이션 - Ranking & Ceiling 특정 페이지 그룹의 시작 키와 종료 키 조회 select ceiling(rank/20. 0) Range. Grp, min(num) Range. Low, max(num) Range. Hi from New. Temp. Brd group by ceiling(rank/20. 0) having ceiling(rank/20. 0) = 37
컴비네이션 - Ranking & Ceiling 37번째 페이지 그룹의 모든 데이터 보기 select x. * from Temp. Brd x, ( select ceiling(rank/20. 0) Range. Grp, min(num) Range. Low, max(num) Range. Hi from New. Temp. Brd group by ceiling(rank/20. 0) )y where x. num between y. Range. Low and y. Range. Hi and y. Range. Grp = 37 order by num
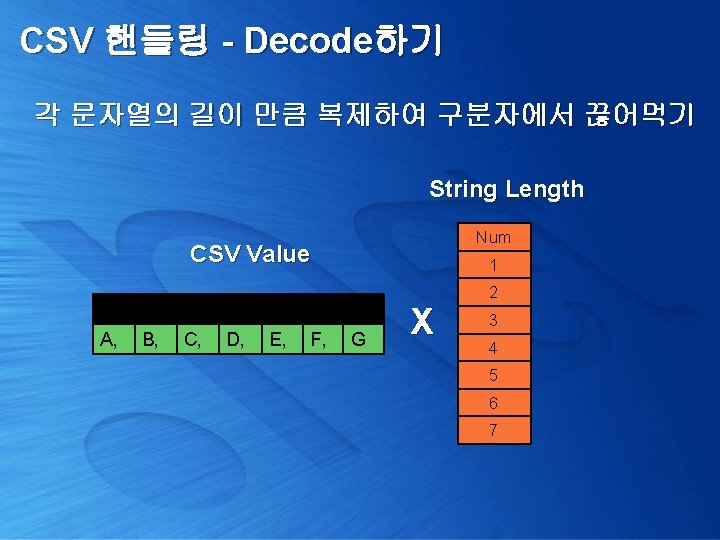
CSV 핸들링 - Encode하기 Multi-value들은 단일 CSV 값으로 모으기 declare @title_ids varchar(8000) select @title_ids = COALESCE(@title_ids + ', ', '') + title_id from pubs. dbo. titles select @title_ids Title_Ids
CSV 핸들링 - Decode하기 Fix. CSV Sample Table Emp. ID Terms Pay. Amt Kosmos 01월, 02월, 08월, 11월 500 David 05월, 06월, 09월, 12월 450 Omega 03월, 04월, 05월 180 Zinko 12월 250
CSV 핸들링 - Decode하기 첫번째 복제 카운트+’월’ 문자열이 없는 경우는 0값을 반환 select *, Char. Index(dbo. LPad(y. Num, 2, '0')+'월', x. Terms) from Fix. CSV x, Dic_Number y where y. Num <= 12
CSV 핸들링 - Decode하기 첫번째 값이 0 이상인 경우만을 찾아서 보여주도록 하면 select x. emp_id, dbo. LPad(y. Num, 2, '0') + '월' Work. Month, x. pay. Amt from Fix. CSV x, Dic_Number y where y. Num <= 12 and Char. Index(dbo. LPad(y. Num, 2, '0')+'월', x. Terms) > 0
CSV 핸들링 - Decode하기 두번째 동적으로 문장의 길이만큼 복제, 약간의 비효율 select *, Char. Index(dbo. LPad(y. Num, 2, '0')+'월', x. Terms) from Fix. CSV x, Dic_Number y where y. Num <= Len(‘, ’ + x. Terms + ‘, ’)
CSV 핸들링 - Decode하기 문자열을 한자씩 파싱해나감 select *, Substring(', '+x. Terms+', ', y. Num-1, 1) This. Char from Fix. CSV x, Dic_Number y where y. Num <= Len(‘, ’ + x. Terms + ‘, ’)
CSV 핸들링 - Decode하기 파싱한 문자가 구분자(, )인 경우만을 조회 select *, Substring(', '+x. Terms+', ', y. Num-1, 1) This. Char from Fix. CSV x, Dic_Number y where y. Num <= Len(‘, ’ + x. Terms + ‘, ’) and Substring(', '+x. Terms+', ', y. Num-1, 1) = ', '
CSV 핸들링 - Decode하기 원래 문자열에서 구분자부터 나머지까지 문자열 자르기 select *, Substring(', '+x. Terms+', ', y. Num, len(', '+x. Terms+', ')) This. Char. Below from Fix. CSV x, Dic_Number y where y. Num <= Len(‘, ’ + x. Terms + ‘, ’) and Substring(', '+x. Terms+', ', y. Num-1, 1) = ', '
CSV 핸들링 - Decode하기 구분자에서 다음 구분자까지 문자열 잘라내기, 최종 select emp_id, Substring(', '+x. Terms+', ', y. Num, Char. Index(', ', ', '+x. Terms+', ', y. Num) - y. Num ) Terms, pay. Amt from Fix. CSV x, Dic_Number y where y. Num <= Len(‘, ’ + x. Terms + ‘, ’) and Substring(', '+x. Terms+', ', y. Num-1, 1) = ', '
© 2003 Microsoft Corporation. All rights reserved. This presentation is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY.