Databases recover themselves Services recover themselves Servers recover



Databases recover themselves Services recover themselves Servers recover themselves Datacenters recover themselves Failover time decreased by 50% 58% faster reseeds
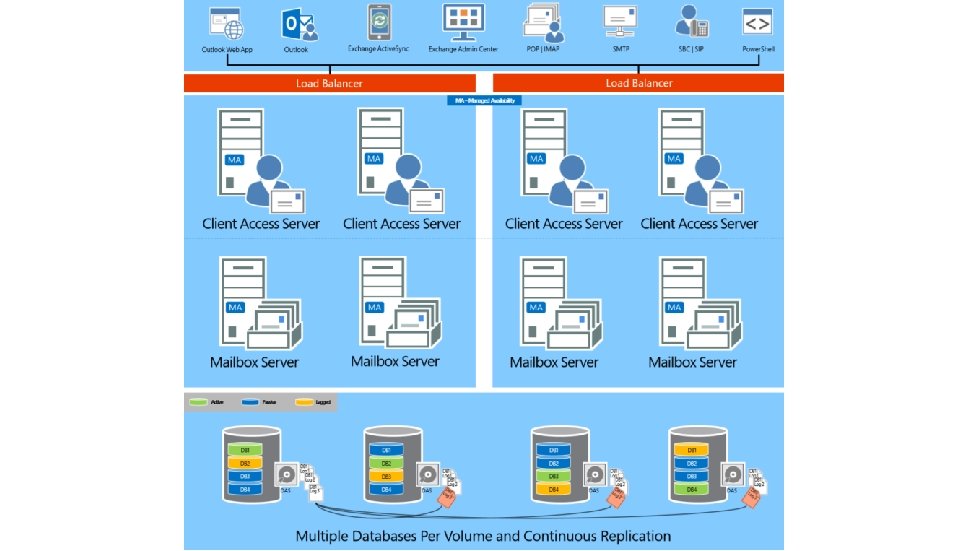

620 checkins since CU 1 IP addressless DAGs Dag Management service Loose Truncation New Monitors Max Preferred Actives Database Activation Suspended and Move Now


Find and fix the root cause code Recover the client experience Repair the symptom Remove complexity root repair recover remove

root Much easier to set up Fewer things that can fail Let Exchange manage, or use robust Power. Shell repair recover remove

root Runs non-critical aspects of maintaining high availability repair Checking for sufficient redundancy and availability Loose Truncation monitoring Lag manager Separates Log Replication and HA decision making from non-core functions to isolate failure modes recover remove

root Active Loose Truncation Passive Loose Truncation repair recover remove

root Failed backups are worse than no backups Lagged database copies will play forward beyond their configured value when: • The database has a bad page and needs a patch • There isn’t enough space to keep all the logs • Risk of losing all available copies of a database repair recover remove

root repair Restoring redundancy so you don’t have to Configured by setting mount points for volumes X recover remove


root Now extremely robust Forget about replacing disks as they fail repair Success 99. 94% Probability you’ll need to replace more than monthly: No spares 0. 06% recover remove
")
root repair Exchange Server 2010 Exchange Server 2013 ESE Database Hung IO (4 min) Failure Item Channel Heartbeat (0. 5 min) System disk Heartbeat (2 min) System Bad State (5 min) Long I/O times (. 6 min) Repl memory threshold (4 GB) Repl won’t restart (65 min) Store timeout (1 min) Exchange Server 2013 SP 1 Cluster service repeated crashes (60 min) recover remove

125, 000+ databases at 99. 98% availability 15 second average DB failover time Site switchovers/month: 100 s planned, 10 s unplanned 26 locations worldwide HA weekly recovery actions per server One Copy Min Per Database 0 1 Sep Nov Jul May Mar Nov Jan'13 Sep Jul Mar May Jan'12 Nov Sep Jul May Mar Jan'11 Oct Aug May Feb '10 10 0. 05 0. 15 Server. One. Copy. Internal. Monitor. Service. Restart Service. Health. MSExchange. Repl. Endpoint. Restart Cluster. Endpoint. Restart Service. Health. MSExchange. Repl. Endpoint. Failover Server. One. Copy. Internal. Monitor. Force. Reboot 0. 1 Service. Health. Active. Manager. Restart. Service. Health. Active. Manager. Force. Reboot Service. Health. MSExchange. Repl. Force. Reboot 0. 01 Service. Health. MSExchange. Repl. Endpoint. Restart. Second. Trial Restart service Server failover Reboot


Fundamental purpose of Managed Availability is to: • Detect customer impacting service degradation • Attempt to recover from failure • If recovery fails – escalate to Exchange administrators

Monitor engine: pivotal to MA – contains business logic of evaluating health of customer impacting features Probe engine: measurements Responder engine: set of recovery actions that taking and notifications can be taken to recover degraded state of the mechanism, feeding into… monitored resource

provides status of all monitors tracking a particular server provides a rollup of health sets for a server or for group of servers Complete set of monitors, probes and responders can be found in Windows crimson log channel

HA uses MA to monitor data redundancy, cluster health, physical storage health and database logical corruption HA Probes, Monitors and Responders are grouped into Data. Protection and Clustering Health. Sets

Cluster. Endpoint. Monitor Cluster. Group. Monitor Cluster. Hang. Monitor Cluster. Network. Monitor Cluster. Service. Crash. Monitor Database. Health. Db. Copy. Failed. And. Suspended. Monitor Database. Health. Db. Copy. Stalled. Monitor Database. Health. Db. Copy. Suspended. Monitor Database. Health. Log. Copy. Queue. Monitor Database. Health. Log. Replay. Queue. Monitor Server. One. Copy. Internal. Monitor Server. Wide. Offline. Monitor Service. Health. Active. Manager. Check. Monitor Service. Health. MSExchange. Repl. Crash. Monitor Service. Health. MSExchange. Repl. Endpoint. Monitor Ese. Db. Time. Too. New. Monitor Ese. Db. Time. Too. Old. Monitor Ese. Inconsistent. Data. Monitor Ese. Lost. Flush. Monitor Database. Health. Log. Generation. Rate. Monitor Database. Health. Un. Monitored. Database. Monitor Database. Health. Circ. Logging. Monitor Storage. Db. Io. Hard. Failure. Item. Monitor Low. Log. Volume. Space. Monitor

Server. One. Copy. Monitor: HA’s most important redundancy protection Once a minute each database on a server is checked: • • • Copy is (Healthy || Mounted) && Server. Component. State is NOT Offline && Copy is NOT Activation Blocked && Server is NOT exceeding Max. Active && Copy Queue Length < Mount. Dial && Server is NOT Activation Disabled

30 consecutive failures are considered as a Escalating condition Immediately after that One. Copy. Monitor is notified and becomes “Unhealthy” One. Copy. Monitor UNHEALTHY …

Monitor has three probes and five responders:

In Exchange 2013 the story is a little bit more complicated than in Exchange 2010 Mailbox Server has multiple roles installed In order to prevent outages we need to make sure server is not serving any client protocol

Put server into maintenance 1. 2. 3. 4. 5. 6. Set Transport and UM to draining their queues Set messaging redirection to (preferably) another server in the DAG Suspend cluster node Set server to be Activation Disabled Set server to be Activation Blocked Set all Server. Component. States Offline Confirm • • All Server. Component. States are offline Server is activation blocked and activation disabled Cluster node is “Paused” Transport queues are empty



What’s the same? Still Active Manager algorithm What’s new? Cap replay queue to limit mount time Performed at *over time New max actives soft limit Uses extracted system health BCS criteria includes protocol stack health Same replication criteria and phases Protocol health prioritized to control impact Tuned replication health criteria thresholds MA failover responder targets not worse server

Load management limits Controls server max load Server-level activation controls Controls server usage Database-level activation control Prevent copy activation – questionable database copy?

Maximum Active Databases Dismount instead of failover Maximum Preferred Actives Designed optimum Optimized for load Still allows mount Result of Redistribute. Active. Databases. ps 1 Example: 28 Example: 14 Example: 19

Maximum. Active. Databases Hard limit for activation– i. e. worst case Enforced by BCS Dismount databases over limit Control “exceptional failure” load Set to most mdbs you want per server Maximum. Preferred. Active. Databases Soft limit for activation – new in SP 1 Copies deprioritized in BCS Catalog and copy queue health Failovers can exceed limit Load balancing optimizes to this limit Follow role requirements calculator guidance Checks can be skipped in Move-Active. Mailbox. Database Parameter “Skip. Maximum. Active. Database. Checks” skips both; be careful!

Normal *over behavior All health sets healthy All medium priority health sets and above are healthy All health sets on target server are better than source server All health sets on target server are the same as source server Server health not considered MA failover responder behavior Skip target if not better than source server All health sets healthy All medium priority and above are healthy All health sets better than source server


New server setting to improve site resilience Get all active databases off server – FAST! Last resort to not move an active! Proactively continue move databases attempts Server can still be in service Databases mounted and mail delivery!

Tool Parameter Value Instance Usage Suspend-Mailbox. Database. Copy Activation. Only N/A Per database Keep active off a working but copy questionable drive Set-Mailbox. Server Database. Copy. Auto Activation. Policy “Blocked” or “Unrestricted” Per server Used to control active/passive SR configurations and maintenance. Can force admin move…. . Set-Mailbox. Server Database. Copy. Acti vation. Disabled. An d. Move. Now $true or $false Per server Used to do faster site failovers and maintain database availability. Databases are not blocked from failing back. Continuous move off operation.

Maintenance Mode Server is out of service No active databases No PAM No mailflow Used for: Software installation Hardware or software repair Site Resilience VS. CAS out of service REMOVED from name space NOT in maintenance mode Mailboxes not out of service NOT in maintenance mode Can be forced to provide active service

Windows Server 2012 and later Node Shutdown Node removes its own vote Node Crash Remaining active nodes remove vote of the downed node Node Join On successful join the node gets its vote back

Windows Server 2012 R 2 and later Witness Offline Witness vote gets removed by the cluster Witness Failure Witness vote gets removed by the cluster Witness Online If necessary, Witness vote is added back by the cluster

Exchange is not dynamic quorum or witness - aware DAGS use dynamic quorum to reduce Restore-DAG usage No quorum requirements changes for DAGs Internal DAG testing used dynamic quorum Enabled in Office 365 for servers on Windows Server 2012 Guidance: Use it; it will help DAG availability If using Dynamic Quorum and Restore-DAG make sure excluded nodes are powered off and will not automatically power on

New Witness Server placement options available Right answer based on biz needs and available options Deployment scenario Recommendations DAG(s) deployed in a single datacenter Locate witness server in the same datacenter as DAG members; can share one server across DAG(s) deployed across two datacenters; No additional locations available Locate witness server in primary datacenter; can share one server across DAG(s) deployed across two+ datacenters Locate witness server in third location; can share one server across DAGs Third location DAG witness server improves DAG recovery behaviors Automatic recovery on datacenter loss; Third location network infrastructure must have independent failure modes

Frontend/Backend recovery are independent!!! DNS resolves to multiple IP addresses Most protocol access in Exchange Server 2013 is HTTP clients have built-in IP failover capabilities Clients skip past IPs that produce hard TCP failures

Admins can switchover by removing VIP from DNS or disabling Namespace no longer a single point of failure No dealing with DNS latency Single or multiple name space options

Automate





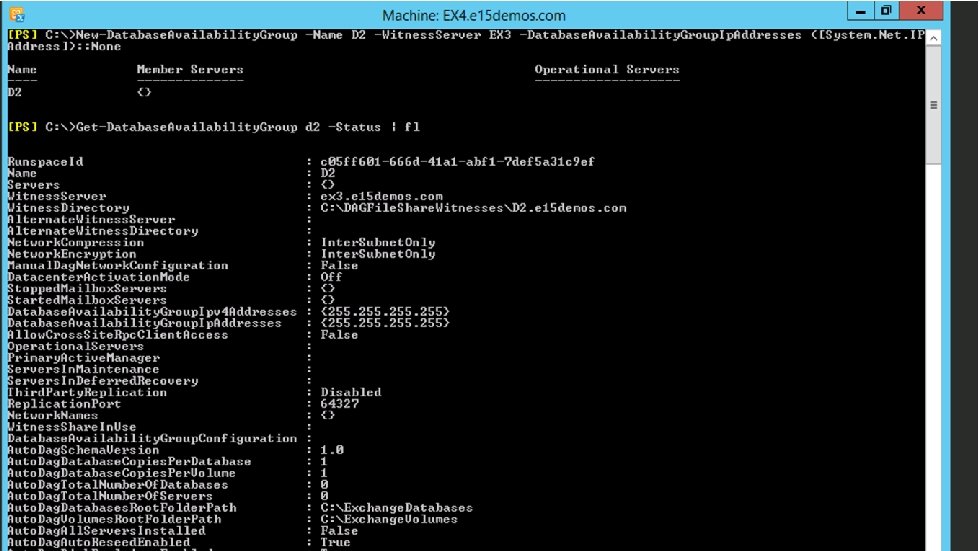

Configure Storage subsystem with spare disks Create DAG, add servers with configured storage Auto. Dag. Databases. Root. Folder. Path (DAG) Auto. Dag. Volumes. Root. Folder. Path (DAG) Create directory and mount points Configure DAG, including Auto. DAG properties Create mailbox databases and database copies Auto. Dag. Database. Copies. Per. Volume (DAG) == 1 MDB 2 Manipulate the settings with Set/Get-Database. Availability. Group MDB 1. db MDB 1. log
 Start the seed (1 hr)")
Periodically scan for failed and suspended copies (15 m) Start the seed (1 hr) Resume copy three times (45 m) Verify that healthy copy Pre-reqs, then remap a spare Release the original spare

Cluster will survive simultaneous loss of 50% votes Especially useful in multi-site DR scenarios with even split Cluster always ensures total number of votes are Odd One site automatically elected to win By default, cluster randomly selects a node to take its vote out Lower. Quorum. Priority. Node. ID cluster common property identifies a node to take its vote out Cluster Site 1 Site 2
 mail. contoso. com")
Single Common Namespace Example Geographical DNS Solution Sue (somewhere in NA) mail. contoso. com DNS Resolution Round-Robin between # of VIPs VIP #1 DAG Sue DNS Resolution via Geo-DNS Round-Robin between # of VIPs VIP #2 VIP #3 DAG (traveling in APAC) VIP #4

All Healthy Checks for a server hosting a copy that has all health sets in a healthy state Up to Normal Healthy Checks for a server hosting a copy that has all health sets Medium and above in a healthy state All Better than Source Checks for a server hosting a copy that has health sets in a state that is better than the current server hosting the affected copy Same as Source Checks for a server hosting a copy of the affected database that has health sets in a state that is the same as the current server hosting the affected copy

Dynamic Quorum DQ = 7

Dynamic Quorum DQ = 4 X X X

Dynamic Quorum DQ = 4 X X X

Dynamic Quorum X DQ = 3 X X X

Dynamic Quorum X Node weight = 0 DQ = 3 X X X

X cas 1 cas 2 Redmond cas 3 cas 4 Portland

X Assuming MBX 3 and MBX 4 are operating and one of them can lock the witness. log file, automatic failover should occur mbx 1 mbx 2 Redmond dag 1 mbx 3 mbx 4 witness Portland

1. Mark the failed servers/site as down: Stop-Database. Availability. Group DAG 1 –Active. Directory. Site: Redmond X 2. Stop the Cluster Service on Remaining DAG members: Stop-Clussvc 3. Activate DAG members in 2 nd datacenter: Restore-Database. Availability. Group DAG 1 –Active. Directory. Site: Portland mbx 1 mbx 2 Redmond dag 1 X X mbx 3 mbx 4 Portland

1. Mark the failed servers/site as down: Stop-Database. Availability. Group DAG 1 –Active. Directory. Site: Redmond X 2. Stop the Cluster Service on Remaining DAG members: Stop-Clussvc 3. Activate DAG members in 2 nd datacenter: Restore-Database. Availability. Group DAG 1 –Active. Directory. Site: Portland mbx 1 mbx 2 Redmond dag 1 mbx 3 mbx 4 Portland
- Slides: 65