Data Mining Concepts and Techniques Mining Frequent Patterns





 = #tuples")

 • One problematic aspect of the Apriori is")
 • Initially, scan database for frequent 1 -itemsets – Place")















 Header table B: 1 A: 2 C: 1 D: 1")
 Header table null A A: 2 C: 1 2 D: 1")
 Header table A: 1 C: 1 The conditional")
 Header table null The conditional FPTree for suffix AE null A:")
 Header table A: 2")
 Header table null A: 4 B: 2 B: 1 C: 1")
 Header table Conditional FPTree for suffix CDB null A: 2 B:")
 Header table Conditional FPTree for suffix CDA null The set of")
 Header table A: 1 C: 3")
 Header table null B B: 6 Conditional FPTree for suffix AC")
 Header table B 6 B: 6 Conditional FPTree for suffix")
 Header table A: 2 B Conditional FPTree for")
 Header table Conditional FPTree for suffix B null B: 8 The")





- Slides: 44
Data Mining: Concepts and Techniques Mining Frequent Patterns & Association Rules Dr. Maher Abuhamdeh
What Is Frequent Pattern Analysis? • Frequent pattern: a pattern (a set of items, subsequences, substructures, etc. ) that occurs frequently in a data set • First proposed by Agrawal, Imielinski, and Swami [AIS 93] in the context of frequent itemsets and association rule mining • Motivation: Finding inherent regularities in data – What products were often purchased together? — Tea and Milk? ! – What are the subsequent purchases after buying a PC? – What kinds of DNA are sensitive to this new drug? – Can we automatically classify web documents? • Applications – Basket data analysis, cross-marketing, catalog design, sale campaign analysis, .
Applications • Market Basket Analysis: given a database of customer transactions, where each transaction is a set of items the goal is to find groups of items which are frequently purchased together. • Telecommunication (each customer is a transaction containing the set of phone calls) • Credit Cards/ Banking Services (each card/account is a transaction containing the set of customer’s payments) • Medical Treatments (each patient is represented as a transaction containing the ordered set of diseases) • Basketball-Game Analysis (each game is represented as a transaction containing the ordered set of ball passes)
Basic Concepts: Frequent Patterns Tid Items bought 10 Tea, Nuts, Diaper 20 Tea, Coffee, Diaper 30 Tea, Diaper, Eggs 40 Nuts, Eggs, Milk 50 Nuts, Coffee, Diaper, Eggs, Milk Customer buys both Customer buys Tea Customer buys diaper • itemset: A set of one or more items • k-itemset X = {x 1, …, xk} • (absolute) support, or, support count of X: Frequency or occurrence of an itemset X • (relative) support, s, is the fraction of transactions that contains X (i. e. , the probability that a transaction contains X) • An itemset X is frequent if X’s support is no less than a minsup threshold
Basic Concepts: Association Rules Tid 10 20 30 40 50 Items bought Tea, Nuts, Diaper Tea, Coffee, Diaper Tea, Diaper, Eggs Nuts, Eggs, Milk Nuts, Coffee, Diaper, Eggs, Milk Customer buys both Customer buys Tea Customer buys diaper • Find all the rules X Y with minimum support and confidence – support, s, probability that a transaction contains X Y – confidence, c, conditional probability that a transaction having X also contains Y Let minsup = 50%, minconf = 50% Freq. Pat. : Tea: 3, Nuts: 3, Diaper: 4, Eggs: 3, {Tea, Diaper}: 3
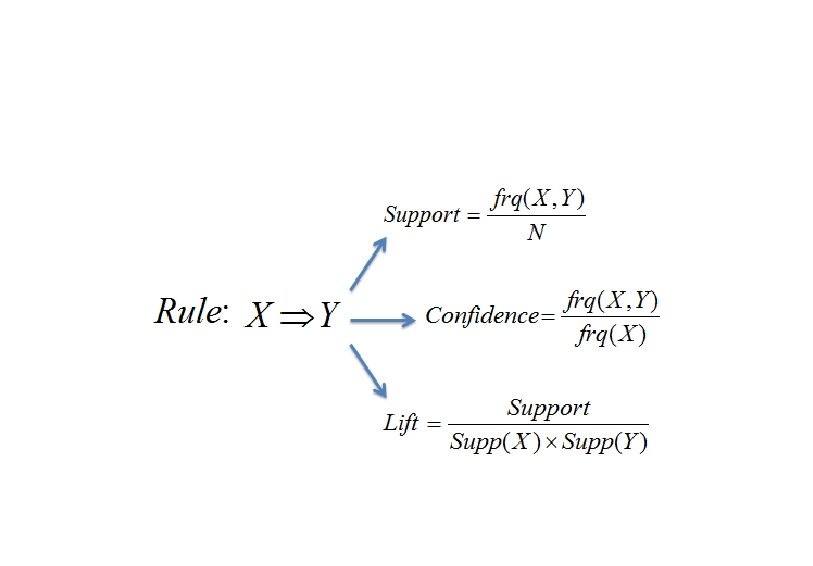
Rule Measures: Support & Confidence • Simple Formulas: – Confidence (A B) = #tuples containing both A & B / #tuples containing A = P(B|A) = P(A U B ) / P (A) – Support (A B) = #tuples containing both A & B/ total number of tuples = P(A U B) • What do they actually mean ? Find all the rules X & Y Z with minimum confidence and support – support, s, probability that a transaction contains {X, Y, Z} – confidence, c, conditional probability that a transaction having {X, Y} also contains Z
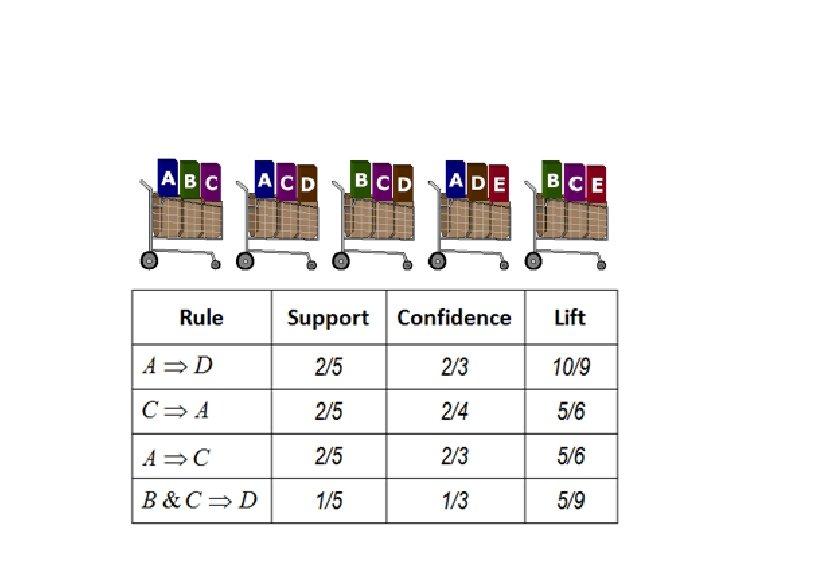
Support & Confidence : An Example Let minimum support 50%, and minimum confidence 50%, then we have, – A C (50%, 66. 6%) – C A (50%, 100%)
FP Growth (Han, Pei, Yin 2000) • One problematic aspect of the Apriori is the candidate generation – Source of exponential growth • Another approach is to use a divide and conquer strategy • Idea: Compress the database into a frequent pattern tree representing frequent items
FP Growth (Tree construction) • Initially, scan database for frequent 1 -itemsets – Place resulting set in a list L in descending order by frequency (support) • Construct an FP-tree – Create a root node labeled null – Scan database • Process the items in each transaction in L order • From the root, add nodes in the order in which items appear in the transactions • Link nodes representing items along different branches
FP-Tree Algorithm -- Simple Case Transaction_id Time Items_bought 101 6: 35 Milk, bread, cookies, juice 792 7: 38 Milk, juice 1130 8: 05 Milk, eggs 1735 8: 40 Bread, cookies, coffee
FP Growth – Another Example TID Items 1 I 1, I 2, I 5 2 I 2, I 4 3 I 2, I 3, I 6 4 I 1, I 2, I 4 5 I 1, I 3 6 I 2, I 3 7 I 1, I 3 8 I 1, I 2, I 3, I 5 9 I 1, I 2, I 3 • Minimum support of 20% (frequency of 2) • Frequent 1 -itemsets I 1, I 2, I 3, I 4, I 5 • Construct list L = {(I 2, 7), (I 1, 6), (I 3, 6), (I 4, 2), (I 5, 2)}
Build FP-Tree Create root node I 2 1 I 1 1 I 3 0 I 4 0 I 5 1 null (I 2, 1) (I 1, 1) (I 5, 1) Scan database Transaction 1: I 1, I 2, I 5 Order: I 2, I 1, I 5 Process transaction Add nodes in item order Label with items, count Maintain header table
Build FP-Tree I 2 2 I 1 1 I 3 0 I 4 1 I 5 1 null (I 2, 2) (I 1, 1) (I 5, 1) (I 4, 1) TID Items 1 I 1, I 2, I 5 2 I 2, I 4 3 I 2, I 3, I 6 4 I 1, I 2, I 4 5 I 1, I 3 6 I 2, I 3 7 I 1, I 3 8 I 1, I 2, I 3, I 5 9 I 1, I 2, I 3
Minining the FP-tree • Start at the last item in the table • Find all paths containing item – Follow the node-links • Identify conditional patterns – Patterns in paths with required frequency • Build conditional FP-tree C • Append item to all paths in C, generating frequent patterns • Mine C recursively (appending item) • Remove item from table and tree
Mining the FP-Tree I 2 7 I 1 6 I 3 6 I 4 2 I 5 null (I 1, 2) (I 2, 7) (I 1, 4) 2 (I 5, 1) (I 3, 2) (I 4, 1) (I 3, 2) Prefix Paths (I 2 I 1, 1) (I 2 I 1 I 3, 1) Conditional Path (I 2 I 1, 2) Conditional FP-tree null (I 3, 2) (I 4, 1) (I 5, 1) (I 2, 2) (I 1, 2) (I 2 I 1 I 5, 2)
FP-Tree Example Continued Item Conditional pattern base Conditional FP-Tree Frequent pattern generated I 5 {(I 2 I 1: 1), (I 2 I 1 I 3: 1)} <I 2: 2 , I 1: 2> I 2 I 5: 2, I 1 I 5: 2, I 2 I 1 I 5: 2 I 4 {(I 2 I 1: 1), (I 2: 1)} <I 2: 2> I 2 I 4: 2 I 3 {(I 2 I 1: 2), (I 2: 2), (I 1: 2)} <I 2: 4, I 1: 2>, <I 1: 2> I 2 I 3: 4, I 1 I 3: 4 , I 2 I 1 I 3: 2 I 1 {(I 2: 4)} <I 2: 4> I 2 I 1: 4
Frequent 1 -itemsets TID Items 1 I 1, I 2, I 5 2 I 2, I 4 3 I 2, I 3, I 6 4 I 1, I 2, I 4 5 I 1, I 3 6 I 2, I 3 7 I 1, I 3 8 I 1, I 2, I 3, I 5 9 I 1, I 2, I 3 • Minimum support of 20% (frequency of 2) • Frequent 1 -itemsets I 1, I 2, I 3, I 4, I 5 • Construct list L = {(I 2, 7), (I 1, 6), (I 3, 6), (I 4, 2), (I 5, 2)}
Build FP-Tree Create root node I 2 1 I 1 1 I 3 0 I 4 0 I 5 1 null (I 2, 1) (I 1, 1) (I 5, 1) Scan database Transaction 1: I 1, I 2, I 5 Order: I 2, I 1, I 5 Process transaction Add nodes in item order Label with items, count Maintain header table
Build FP-Tree I 2 2 I 1 1 I 3 0 I 4 1 I 5 1 null (I 2, 2) (I 1, 1) (I 5, 1) (I 4, 1) TID Items 1 I 1, I 2, I 5 2 I 2, I 4 3 I 2, I 3, I 6 4 I 1, I 2, I 4 5 I 1, I 3 6 I 2, I 3 7 I 1, I 3 8 I 1, I 2, I 3, I 5 9 I 1, I 2, I 3
Mining the FP-tree • Start at the last item in the table • Find all paths containing item – Follow the node-links • Identify conditional patterns – Patterns in paths with required frequency • Build conditional FP-tree C • Append item to all paths in C, generating frequent patterns • Mine C recursively (appending item) • Remove item from table and tree
Mining the FP-Tree I 2 7 I 1 6 I 3 6 I 4 2 I 5 2 Prefix Paths (I 2 I 1, 1) (I 2 I 1 I 3, 1) Conditional Path (I 2 I 1, 2) Conditional FP-tree null (I 1, 2) (I 2, 7) (I 4, 1) (I 1, 4) (I 3, 2) null (I 3, 2) (I 5, 1) (I 3, 2) (I 4, 1) (I 5, 1) (I 2, 2) (I 1, 2) (I 2 I 1 I 5, 2)
FP-tree construction null After reading TID=1: B: 1 After reading TID=2: null B: 2 A: 1 C: 1 D: 1 Minimum support of 20% (frequency of 2)
FP-Tree Construction Transaction Database null B: 8 C: 3 Header table B 8 A 7 C 7 D 5 E 3 D: 1 A: 5 C: 3 D: 1 A: 2 E: 1 C: 1 D: 1 E: 1 Chain pointers help in quickly finding all the paths of the tree containing some given item. There is a pointer chain for each item. I have shown pointer chains only for E and D.
Transactions containing E null B: 8 C: 3 D: 1 A: 5 C: 3 D: 1 A: 2 E: 1 C: 1 D: 1 E: 1 null E: 1 B: 1 A: 2 C: 1 E: 1 C: 1 D: 1 E: 1
Suffix E null (New) Header table B: 1 A: 2 C: 1 D: 1 A 2 C 2 D 2 Conditional FPTree for suffix E null E: 1 D: 1 E: 1 The set of paths ending in E. Insert each path (after truncating E) into a new tree. B doesn’t survive because it has support 1, which is lower than min support of 2. C: 1 A: 2 C: 1 D: 1 We continue recursively. Base of recursion: When the tree has a single path only. FI: E
Suffix DE (New) Header table null A A: 2 C: 1 2 D: 1 The conditional FPTree for suffix DE null D: 1 A: 2 The set of paths, from the E-conditional FP-Tree, ending in D. Insert each path (after truncating D) into a new tree. We have reached the base of recursion. FI: DE, ADE
Suffix CE null C: 1 (New) Header table A: 1 C: 1 The conditional FPTree for suffix CE null D: 1 The set of paths, from the E-conditional FP-Tree, ending in C. Insert each path (after truncating C) into a new tree. We have reached the base of recursion. FI: CE
Suffix AE (New) Header table null The conditional FPTree for suffix AE null A: 2 The set of paths, from the E-conditional FP-Tree, ending in A. Insert each path (after truncating A) into a new tree. We have reached the base of recursion. FI: AE
Suffix D null B: 3 A: 2 C: 1 (New) Header table A: 2 C: 1 D: 1 A 4 B 3 Conditional FPTree for suffix D null C: 1 D: 1 A: 4 B: 1 D: 1 B: 2 The set of paths containing D. Insert each path (after truncating D) into a new tree. C: 1 We continue recursively. Base of recursion: When the tree has a single path only. FI: D
Suffix CD (New) Header table null A: 4 B: 2 B: 1 C: 1 A 2 B 2 Conditional FPTree for suffix CD null C: 1 A: 2 B: 1 The set of paths, from the D-conditional FP-Tree, ending in C. Insert each path (after truncating C) into a new tree. We continue recursively. Base of recursion: When the tree has a single path only. FI: CD
Suffix BCD (New) Header table Conditional FPTree for suffix CDB null A: 2 B: 1 null B: 1 The set of paths from the CD-conditional FP-Tree, ending in B. Insert each path (after truncating B) into a new tree. We have reached the base of recursion. FI: CDB
Suffix ACD (New) Header table Conditional FPTree for suffix CDA null The set of paths from the CD-conditional FP-Tree, ending in A. Insert each path (after truncating B) into a new tree. We have reached the base of recursion. FI: CDA
Suffix C null B: 6 A: 3 (New) Header table A: 1 C: 3 B 6 A 4 Conditional FPTree for suffix C C: 1 null C: 3 B: 6 A: 1 A: 3 The set of paths ending in C. Insert each path (after truncating C) into a new tree. We continue recursively. Base of recursion: When the tree has a single path only. FI: C
Suffix AC (New) Header table null B B: 6 Conditional FPTree for suffix AC 3 A: 1 null A: 3 B: 3 The set of paths from the C-conditional FP-Tree, ending in A. Insert each path (after truncating A) into a new tree. We have reached the base of recursion. FI: AC, BAC
Suffix BC null (New) Header table B 6 B: 6 Conditional FPTree for suffix BC null The set of paths from the C-conditional FP-Tree, ending in B. Insert each path (after truncating B) into a new tree. We have reached the base of recursion. FI: BC
Suffix A null B: 5 (New) Header table A: 2 B Conditional FPTree for suffix A 5 A: 5 null B: 5 The set of paths ending in A. Insert each path (after truncating A) into a new tree. We have reached the base of recursion. FI: A, BA
Suffix B (New) Header table Conditional FPTree for suffix B null B: 8 The set of paths ending in B. Insert each path (after truncating B) into a new tree. We have reached the base of recursion. FI: B
Apriori Advantages and disadvantages • Generate all candidates item set and test them with minimum support are expensive in both space and time. • Apriori is so slow comparing with FP growth • Apriori is easy to implement
FP Growth Advantages and disadvantages • No candidate generation, no candidate test • No repeated scan of entire database • Basic ops: counting local frequent items and building sub FP-tree, no pattern search and matching • Faster than Apriori • FP tree is expensive to build • FP tree not fit in memory
ECLAT Algorithm by Example • • Equivalence CLASS Transformation Transform the horizontally formatted data to the vertical format by scanning the database once TID List of item IDS T 100 I 1, I 2, I 5 T 200 I 2, I 4 T 300 I 2, I 3 T 400 I 1, I 2, I 4 T 500 I 1, I 3 T 600 I 2, I 3 T 700 I 1, I 3 T 800 I 1, I 2, I 3, I 5 T 900 I 1, I 2, I 3 itemset TID_set I 1 {T 100, T 400, T 500, T 700, T 800, T 900} I 2 {T 100, T 200, T 300, T 400, T 600, T 800, T 900} I 3 {T 300, T 500, T 600, T 700, T 800, T 900} I 4 {T 200, T 400} I 5 {T 100, T 800}
ECLAT Algorithm by Example Frequent 1 -itemsets in vertical format min_sup=2 itemset TID_set I 1 {T 100, T 400, T 500, T 700, T 800, T 900} I 2 {T 100, T 200, T 300, T 400, T 600, T 800, T 900} I 3 {T 300, T 500, T 600, T 700, T 800, T 900} I 4 {T 200, T 400} I 5 {T 100, T 800} • The frequent k-itemsets can be used to construct the candidate (k+1)itemsets based on the Apriori property Frequent 2 -itemsets in vertical format itemset TID_set {I 1, I 2} {T 100, T 400, T 800, T 900} {I 1, I 3} {T 500, T 700, T 800, T 900} {I 1, I 4} {T 400} {I 1, I 5} {T 100, T 800} {I 2, I 3} {T 300, T 600, T 800, T 900} {I 2, I 4} {T 200, T 400} {I 2, I 5} {T 100, T 800} {I 3, I 5} {T 800}
ECLAT Algorithm by Example Frequent 3 -itemsets in vertical format min_sup=2 itemset TID_set {I 1, I 2, I 3} {T 800, T 900} {I 1, I 2, I 5} {T 100, T 800} • This process repeats, with k incremented by 1 each time, until no frequent items or no candidate itemsets can be found • Properties of mining with vertical data format – Take the advantage of the Apriori property in the generation of candidate (k+1)-itemset from k-itemsets – No need to scan the database to find the support of (k+1) itemsets, for k>=1 – The TID_set of each k-itemset carries the complete information required for counting such support – The TID-sets can be quite long, hence expensive to manipulate – Use diffset technique to optimize the support count computation