Data matrix n p Dissimilarity matrix nxn mean




 • mean")



 예 – gender: symmetric – 기타변수: asymmetric – Y, P =>1, N")








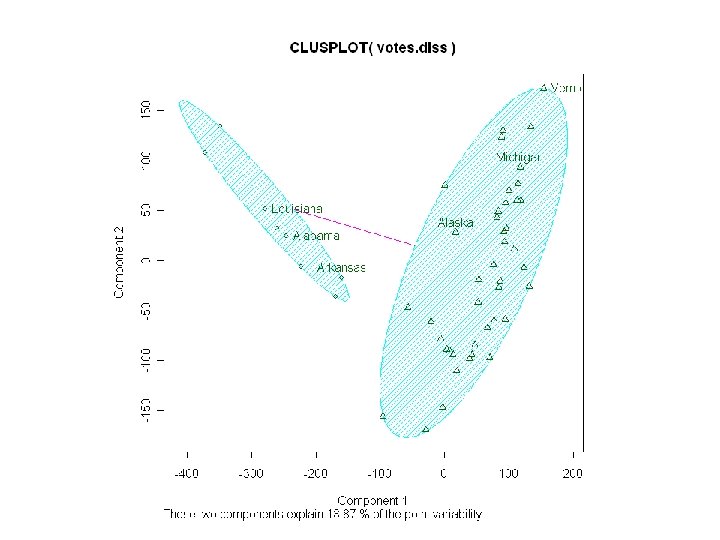
 data(votes. repub) votes. diss <- daisy(votes. repub) #euclidean distance")
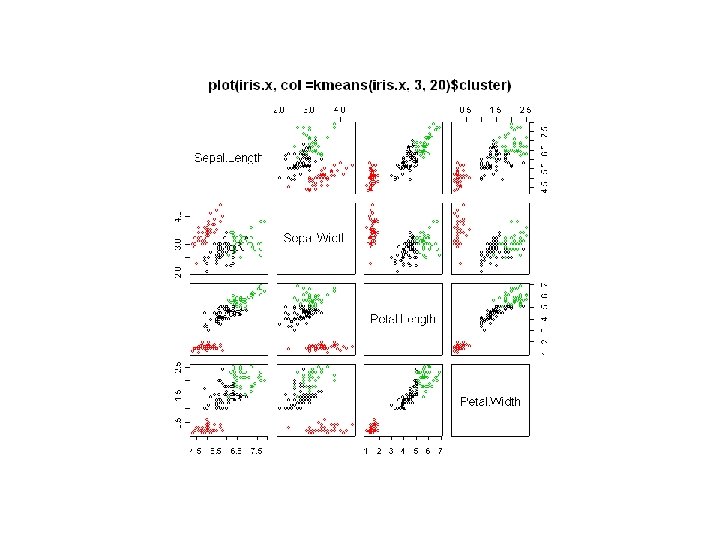
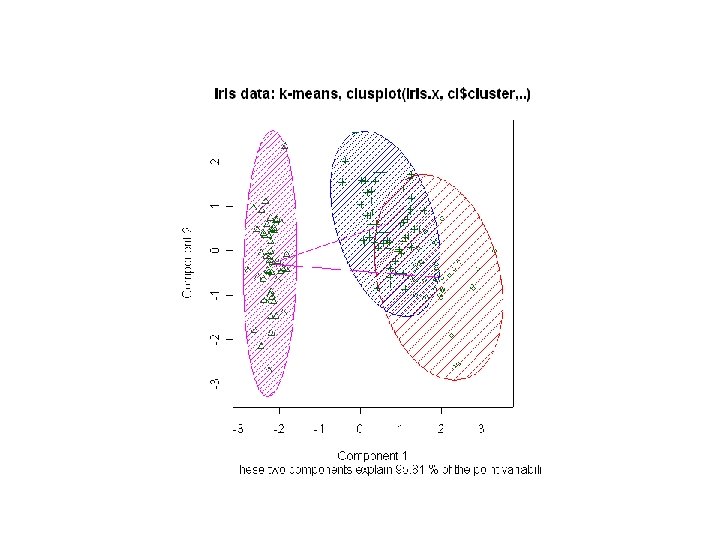
: k=3 par(mfrow=c(1, 2)) data(iris) iris. x <-")

- Slides: 26
자료 • Data matrix – n: 자료수 – p: 변수의 수 • Dissimilarity matrix –nxn
구간형변수 • 표준화 – mean absolute deviation: 여기서 – 펴준화 점수 (z-score) • mean absolute deviation 이 표준편차보다 robust
이진변수 • 이진자료의 분할표 Object j Object i • Simple matching coefficient (symmetric - 중요 성이 동일) • Jaccard coefficient (asymmetric, 중요성이 다름):
이진변수 (asymmetric) 예 – gender: symmetric – 기타변수: asymmetric – Y, P =>1, N => 0
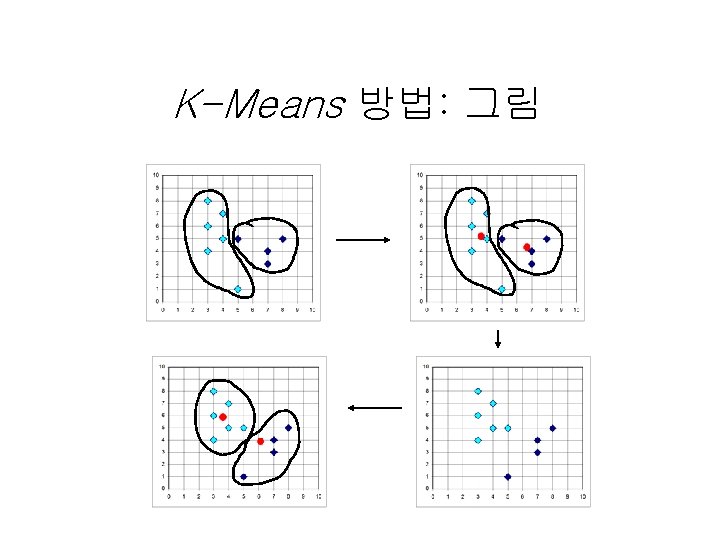
군집방법 • Partitioning algorithms: K-means, Kmedoids • Hierarchy algorithms: dendrogram
R program for PAM library(cluster) data(votes. repub) votes. diss <- daisy(votes. repub) #euclidean distance votes. clus <- pam(votes. diss, 2, diss = TRUE)$clustering if(interactive()) clusplot(votes. diss, votes. clus, diss = TRUE, shade = TRUE, labels = 1)
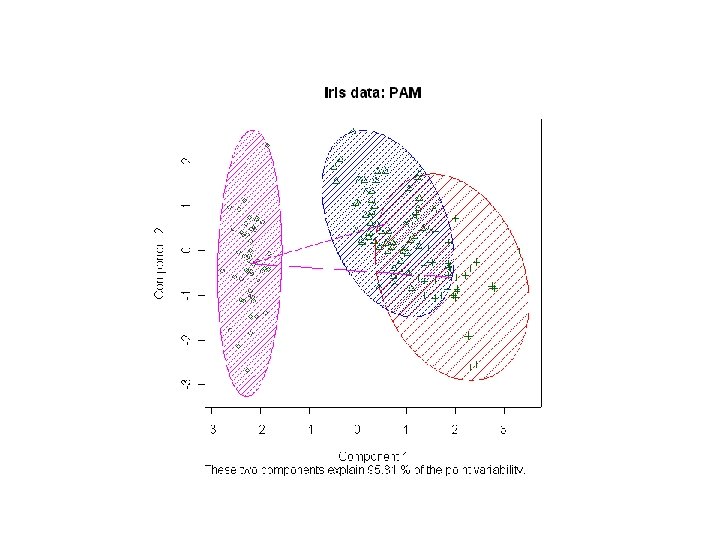
K-medoid: iris data: ##irir 자료: k-medoid (PAM): k=3 par(mfrow=c(1, 2)) data(iris) iris. x <- iris[, 1: 4] clusplot(iris. x, pam(iris. x, 3)$clustering, diss = FALSE, plotchar = TRUE, color = TRUE, shade = TRUE, span=FALSE, line=1)
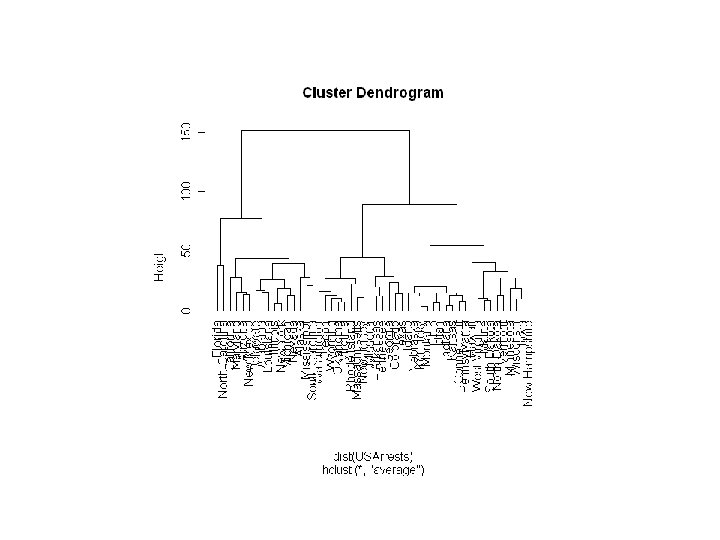
게층적 군집분석 • 거리행렬을 사용하여 군집. – K 를 먼저 선택할 필요가 없다. – 끝나는 지점을 지정해야한다. Step 0 a b Step 1 Step 2 Step 3 Step 4 ab abcde c cde d de e Step 4 agglomerative (AGNES) Step 3 Step 2 Step 1 Step 0 divisive (DIANA)