Data Hub A Collaborative Data Analytics and Visualization

Data Hub: A Collaborative Data Analytics and Visualization Platform Sam Madden madden@csail. mit. edu With a cast of many….

BIG Data MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Example: Medical Costs MGH Cancer Center “Super-Database” Largest cancer database in the world (173, 301 patients) Based on national tumor registry Cross linked with death registry Includes billing, reports, labs, imagery, genome SNPs Question: What are the factors driving costs for lung cancer patients? Some results: No correlation of cost with • Stage of presentation • Survival Strong correlation of cost with oncologist! - Dr. James Michaelson, Ph. D, MGH, Harvard Medical School MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Challenge: Making Data Accessible Column Oriented DBs Super Duper Indexes Main Memory DBs Map Reduce Beyond scalable platforms What does the data look like? How do I correlate it with other data sets? How do I present it to users/execs? Where are these anomalies and outliers coming from? MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Challenge: Making Data Accessible Introducing Datahub + DB Technology = Octocat, the Github mascot MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY
 Selective Sharing and Access")
Introducing Datahub Data Commons Secure, Hosted Data Storage (“Database Service”) Selective Sharing and Access Control Easy to Find, Combine, Clean Data Sets Ability to Browse, Visualize, and Query Data in situ MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Lots of other places to find data! Datahub: “five-star” integrated, For example: browse-able, & query-able repository of linked data Aka … Just a bunch of zip files Versus open, linked data (Tim Berners Lee Taxonomy) ★ ★★ ★★★★★ make your stuff available on the Web under an open license make it available as structured data use non-proprietary formats (e. g. , CSV instead of Excel) use URIs to denote things, so that people can point at your stuff link your data to other data to provide context MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Datahub Interface Anant Bhardwaj MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Datahub Interface MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Datahub Interface MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

“Wrangling” Features Wrangler: Interactive Visual Specification of Data Transformation Scripts Sean Kandel, Andreas Paepcke, Joseph Hellerstein, Jeffrey Heer MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Post-Wrangling MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

More Datahub Interface Versions Browsing and Visualization MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

MIT Living Lab • Goal: allow MIT community to access, selectively share, and use data about itself, using Data. Hub. A Dogfood Eating Exercise MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

MIT Living Lab • Goal: allow MIT community to access, selectively share, and use data about itself, using Data. Hub. Organizational Data MIT data: ID card swipes, network packets, expense reports, medical data, payroll, parking garages, buses and cars, course catalogs, registrar, benefits, on-campus events/seminars, Infrastructure: energy, HVAC, maintenance, etc. Academic/Research: publications, presentations, research data… MIT Data Hub Personal Data: location/GPS, calendar, video/pictures, exercise/physio data, application usage, meetings… Public Data Relevant Linked Data: local transit / transport data, crime data, nearby restaurants, events etc. MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

What Will Data Hub Enable at MIT? • Campus “Quantification” – is going to class correlated with better grades? – which dining facilities are most popular amongst different groups? • Transportation planning: – bus utilization and on demand routing – parking lot utilization – carpool finding, etc • Health + Medical: – – campus wide public health, e. g. , flu tracking, observing who is missing class, depressed Health signals: exercise and eating habits; partners; outpatient care • Research: – expert finding; – data sharing between groups MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Challenges: It’s Not All Fuzzy Stuff We also don’t want our research to be like this guy Platform Challenges: How to efficiently store thousands or millions of databases? Monomi How to anonymize data, control access, etc? How to keep data private and allowing querying over it? Challenges in Improving Interaction Map. D with Databases: Scorpion Data Cleaning and Integration Interactive Data Presentation Understanding Why Results are the Way They Are How to Leverage Experts in an Organization MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Private Data Problem Confidential data leaks 2012: hackers extracted 6. 5 million hashed passwords from the DB of Linked. In Threat: passive DB server attacks User 1 Application User 2 SQL DB Server Sensitive content User 3 Datahub Hackers System administrator

How to protect data confidentiality? Sensitive content DB Server Client Encrypt data Sensitive content server may not be able to process queries! Compute on encrypted data! Without giving server encryption key! General approach has been proposed several times…

Monomi / Crypt. DB Threat 1: passive DB server attacks User 1 Application User 2 SQL DB Server Sensitive content User 3 1. Process SQL queries on encrypted data Hide DB from sys. admins. , outsource DB to the cloud 2. Modest overhead 3. No changes to DBMS (e. g. , Postgres, My. SQL) and no changes to applications w/ Raluca Popa, Stephen Tu, Hari Balakrishnan, Frans Kaashoek, Nickolai Zeldovich

Application Deterministic Randomized encryption SELECT * FROM emp WHERE salary = 100 table 1/emp Proxy SELECT * FROM table 1 WHERE col 3 = x 5 a 8 c 34 x 5 a 8 c 3 ? 4 x 5 a 8 c 3 4 col 1/rank col 2/name col 3/salary x 934 bc 1 x 4 be 219 60 x 5 a 8 c 3 x 95 c 623 4 x 84 a 21 x 2 ea 887 c x 5 a 8 c 3 x 17 cea 7 4 100 SQL Queries on Encrypted Data Example 800 100
 encryption SELECT * FROM emp WHERE salary ≥ 100 Proxy")
Application Deterministic OPE (order) encryption SELECT * FROM emp WHERE salary ≥ 100 Proxy table 1 (emp) SELECT * FROM table 1 WHERE col 3 ≥ x 638 e 54 x 638 e 5 4 x 922 eb 4 x 638 e 5 4 col 1/rank col 2/name col 3/salary x 934 bc 1 x 1 eab 8 1 x 5 a 8 c 3 x 638 e 5 44 x 84 a 21 x 922 eb 4 c x 638 e 5 x 5 a 8 c 3 44 60 100 800 100

Monomi: Protecting Data in Datahub • Extensions to Crypt. DB to efficiently support OLAP queries • Show to run all of TPC-H, rather than just 4 of 22 queries – Key insight: split queries, run as much as possible on untrusted DBMS, compute remainder on trusted client

Monomi vs Plaintext Monomi Runtime vs Plaintext TPC-H SF 10, Postgres See Stephen Explain How it Really Works Right after this Talk! Takeaway: median overhead 1. 24 x,

Many Open Problems Understanding performance more broadly How to reason about security of non-randomized schemes? Auditing, information flow, etc. MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Data. Hub Research Challenges Platform Challenges: How to efficiently store thousands or millions of databases? Monomi How to anonymize data, control access, etc? How to keep data private and allowing querying over it? Challenges in Improving Interaction Map. D with Databases: Scorpion Data Cleaning and Integration Interactive Data Presentation Understanding Why Results are the Way They Are How to Leverage Experts in an Organization MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Interactive Large-Scale Visualization using a GPU Database

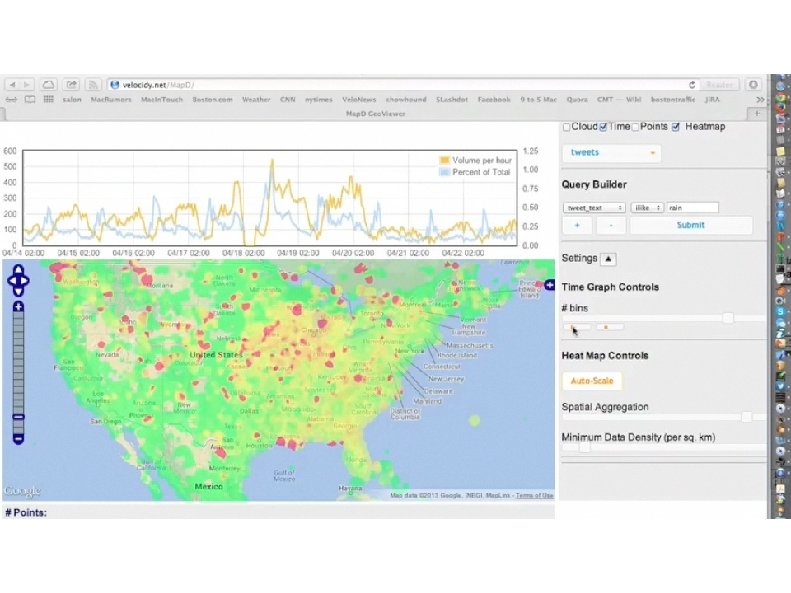
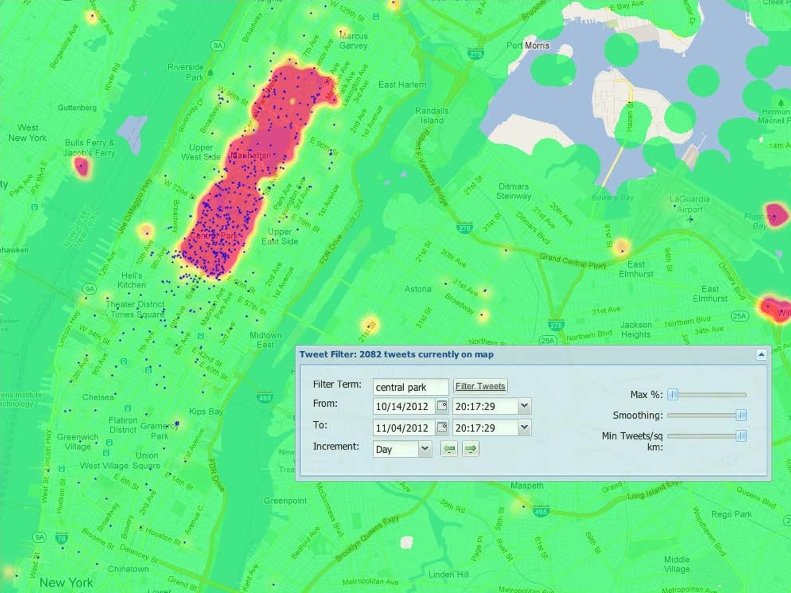
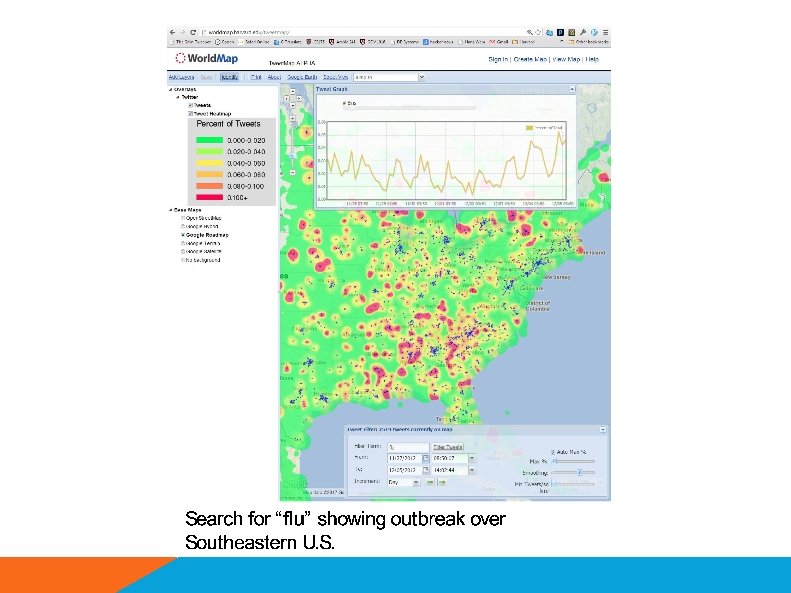
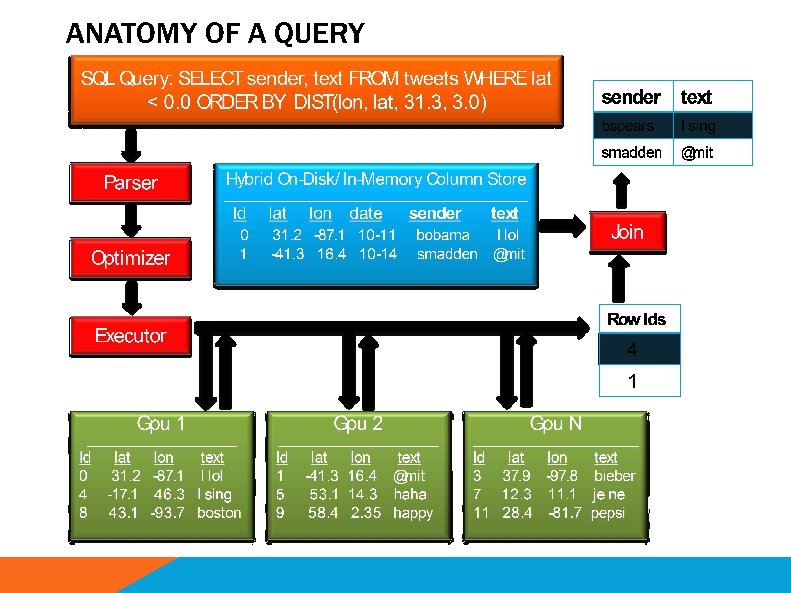
The Need for Interactive Analytics • Data. Hub needs to support browsing massive data sets • Browsing is best supported through visualization ad-hoc analytics, with millisecond response times

Map. D: GPU Accelerated SQL Database • Key insight: GPUs have enough memory that a cluster of them can store substantial amounts of data • Not an accelerator, but a full blown query processor! • Massive parallelism enables interactive browsing interfaces – 4 x GPUs can provide > 1 TB/sec of bandwidth – 12 Tflops compute – Order of magnitude speedups over CPUs, when data is on GPU • “Shared nothing” arrangement

Demo

Next Steps • Scale out to many nodes, automate layout algorithms • Add various advanced analytics (e. g. , machine learning algorithms) • Generalize visualization beyond maps

Data. Hub Research Challenges Platform Challenges: How to efficiently store thousands or millions of databases? Monomi How to anonymize data, control access, etc? How to keep data private and allowing querying over it? Challenges in Improving Interaction Map. D with Databases: Scorpion Data Cleaning and Integration Interactive Data Presentation Understanding Why Results are the Way They Are How to Leverage Experts in an Organization MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Visual Provenance: Scorpion • Visualization of data is most common form of big data analysis • Common problem: outliers • Would be nice to have a tool that identifies why outliers exist Eugene Wu

Definition of Why Given an outlier group, find a predicate over the inputs that makes the output no longer an outlier. i = Input Data 5 4 3. 5 3 2. 5 2 1. 5 1 0. 5 0 Output Visualization Outlier Group p Italy France Spain US p = predicate MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Definition of Why Given an outlier group, find a predicate over the inputs that makes the output no longer an outlier. i = Input Data Output Visualization 5 4 3. 5 3 2. 5 2 1. 5 1 p 0. 5 0 Italy p = predicate MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY France Spain US

Definition of Why Given an outlier group, find a predicate over the inputs that makes the output no longer an outlier. i = Input Data Output Visualization 5 4 3. 5 3 2. 5 2 1. 5 1 p 0. 5 0 Italy France Removing the predicate makes US no longer an outlier What are common properties of those records? MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY Spain US {Bill Gates, Steve Ballmer} p: Company = MSFT

Why is this hard? Exponential search space over records, attributes In general, each candidate predicate requires re-running aggregation A B C D E F G MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Why is this hard? Exponential search space over records, attributes In general, each candidate predicate requires re-running aggregation A B C D E F G AVG(rows) = 2. 7 MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Why is this hard? Exponential search space over records, attributes In general, each candidate predicate requires re-running aggregation A B C D E F G AVG(rows) = 2. 9 MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Why is this hard? Exponential search space over records, attributes In general, each candidate predicate requires re-running aggregation A B C D E F G AVG(rows) = 2. 2 MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Why is this hard? Exponential search space over records, attributes In general, each candidate predicate requires re-running aggregation A B C D E F G AVG(rows) = 3. 3 MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Why is this hard? Exponential search space over records, attributes See Eugene Explain In general, each candidate predicate requires re-running How it Really Works aggregation this Afternoon! Desire for simple, understandable predicates and a general purpose visualization framework A B C D E F G AVG(rows) = 3. 1 … MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Next Steps • A general purpose visualization language for expressing visualizations with provenance support References to underlying data set MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY

Conclusion Big Data is a cry for help from non DB people Lots of exciting work on scalable systems DB community should be doing a much better job of helping users use data We risk losing mindshare Datahub aims to make data easy to find, visualize, and query, securely and efficiently Many fascinating, hard problems! (Monomi, Map. D, Scorpion) MIT COMPUTER SCIENCE AND ARTIFICIAL INTELLIGENCE LABORATORY
- Slides: 48