CSU 33014 Introduction to GPU Architecture and Programming











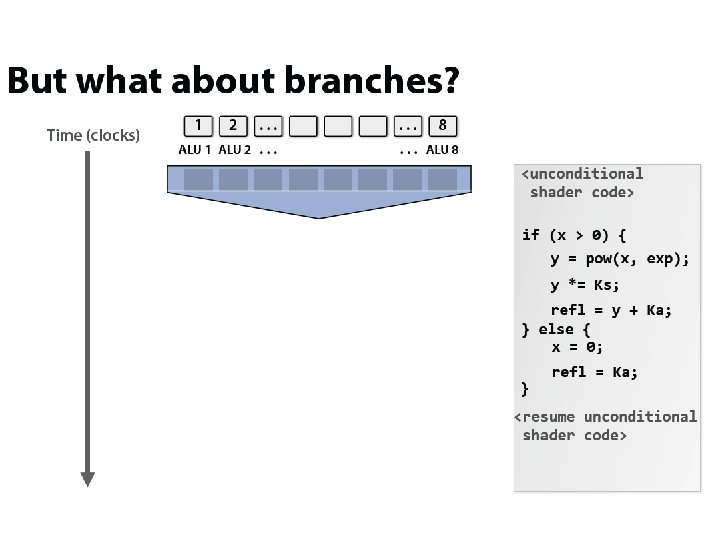
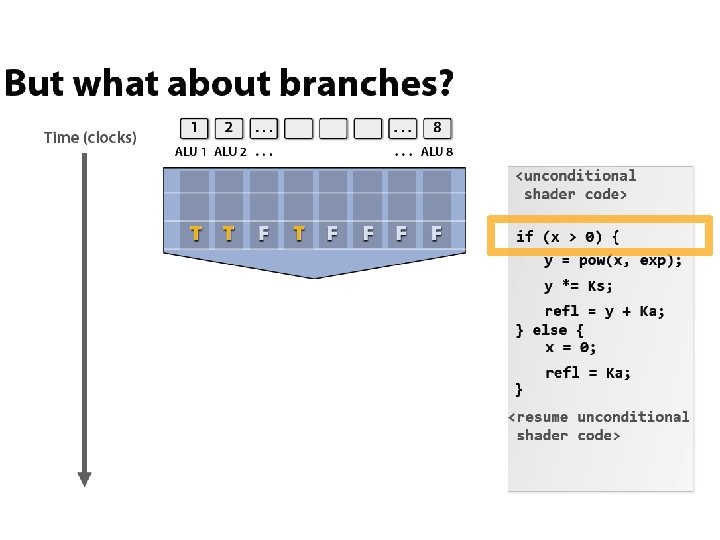

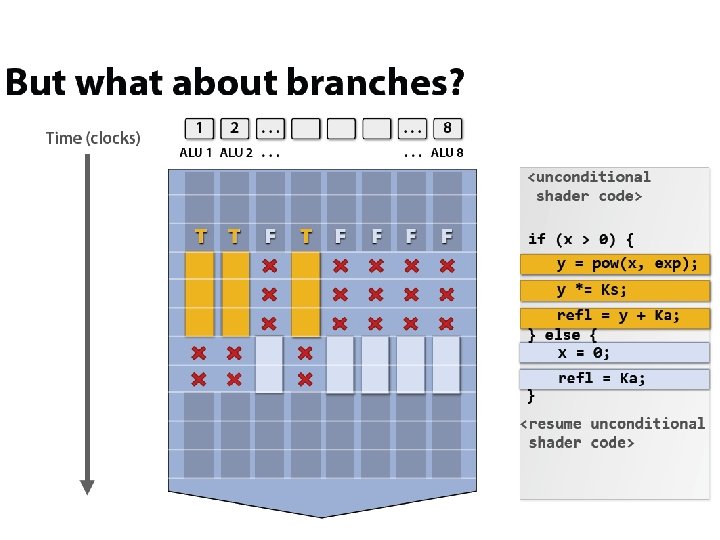



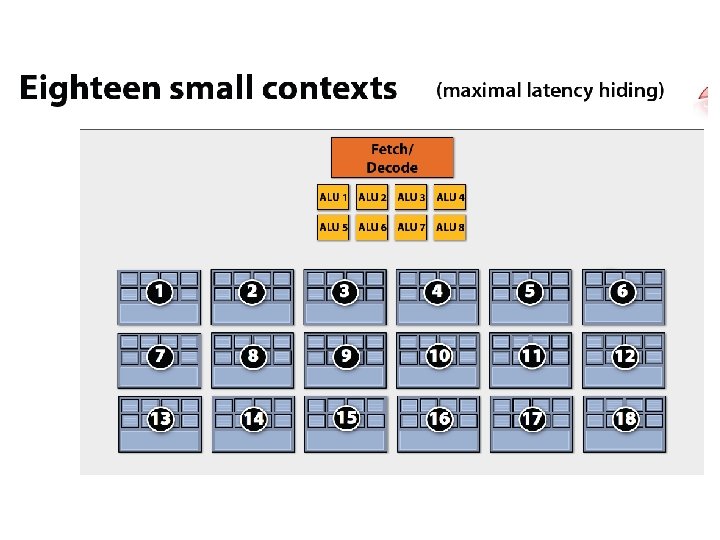
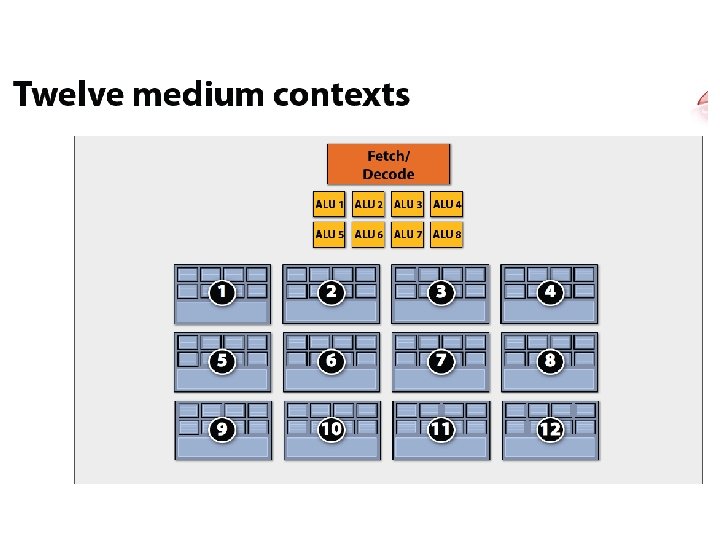
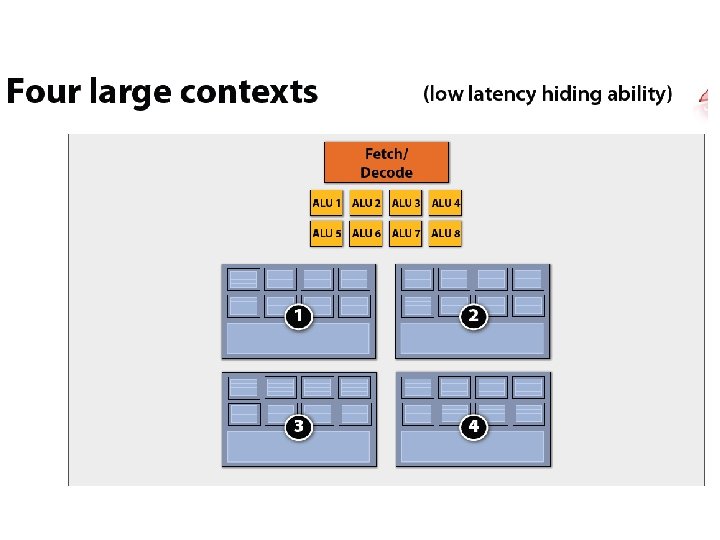
 x 4 interleaving / core x 8 ALUs / core @ 2 cycles/FLOP")






 Harrison’s H 1 sea clock (1737) 34")
 NVIDIA-terminology • 480 stream processors (“CUDA")
 CUDA ‘core’ • A multiprocessor contains 32")






 Summary - Employ")


 slow – 400 -600")







 4 cycles")
 4")







. •")
- Slides: 64
CSU 33014 Introduction to GPU Architecture and Programming Model Based on slides from Matei Ripeanu Acknowledgement: some slides borrowed from presentations by K. Fatahalian, M. Harris, S. Al-Kiswany 1
Which plane is better? Plane YVR to Paris Speed Passengers Boeing 747 10 hours 600 mph 470 Concorde 5 hours 1200 mph 132
Same idea for GPUs - Specialized for data-intensive highly parallel computations - (exactly what the graphics hardware does well) - More transistors allocated to processing data rather than to caching and control flow (compared to CPUs)
Outline • Hardware: GPU Architecture Intuition • Software - Programming Model - Optimizations
GPU Architecture Intuition
GPU Architecture Intuition
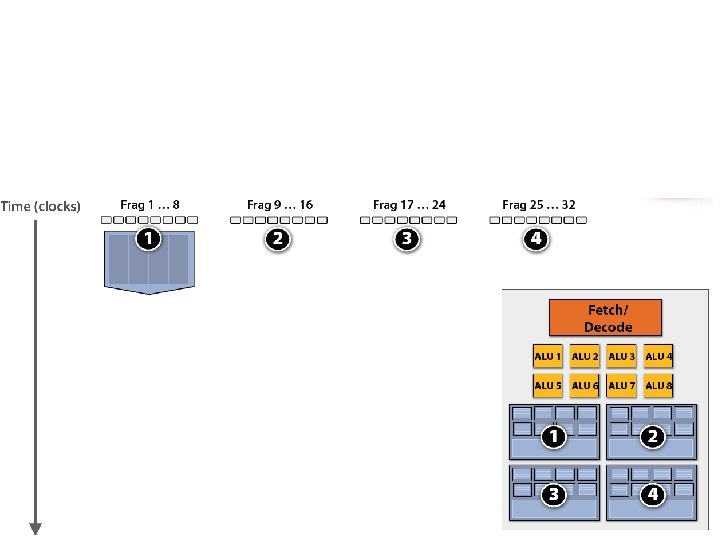
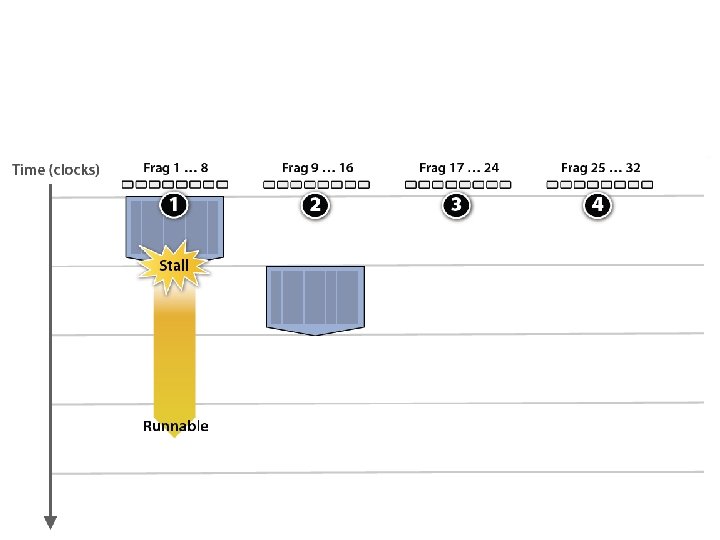
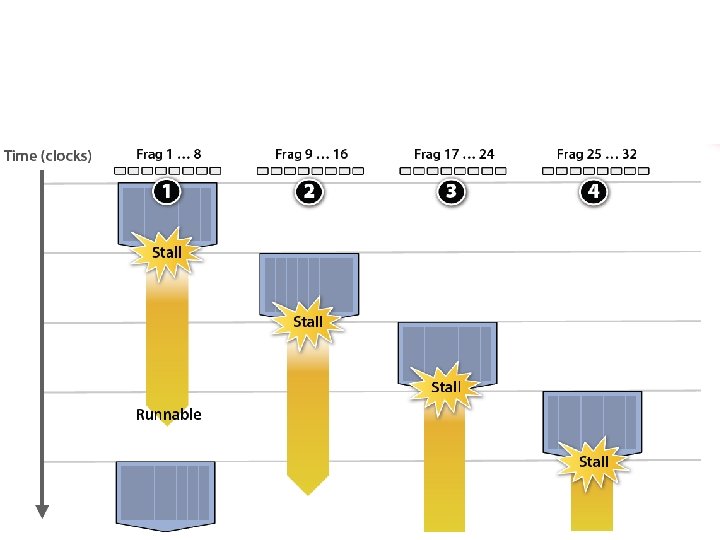
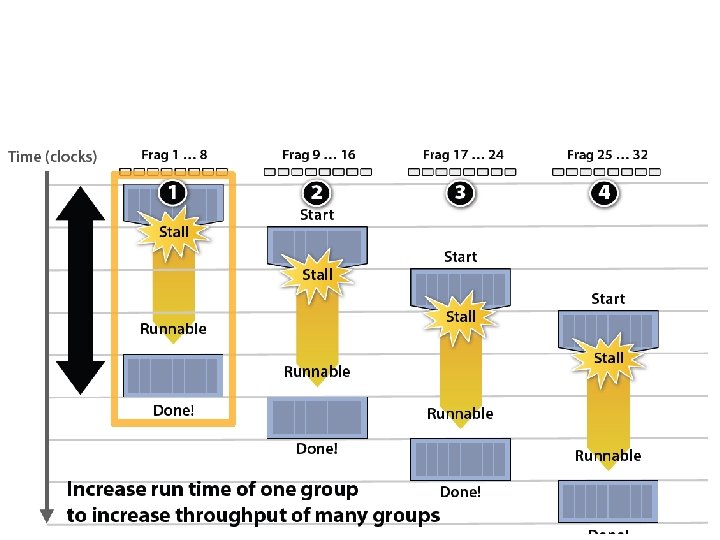
GPU Architecture Intuition
GPU Architecture Intuition
GPU Architecture Intuition
GPU Architecture Intuition
GPU Architecture Intuition
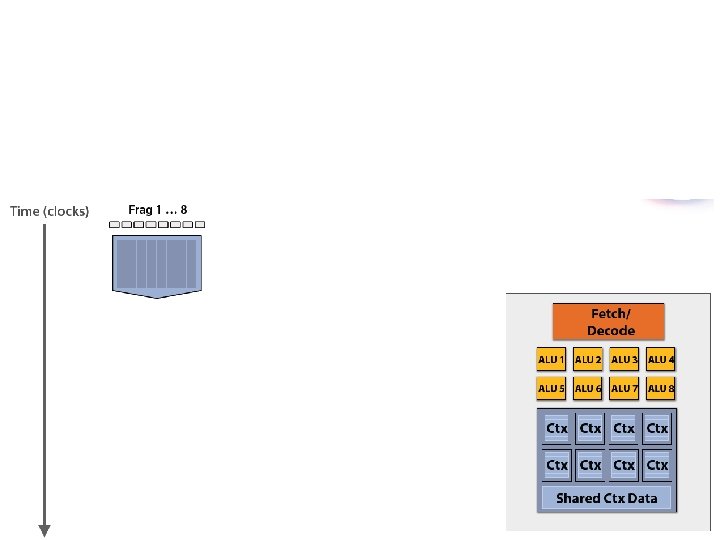
Your data is not ready …
Storing contexts
(imagined) x 4 interleaving / core x 8 ALUs / core @ 2 cycles/FLOP
Carding 29
Spinning 30
Spinning Jenny 31
Weaving 32
Weaving Jacquard Loom 33
Mechanical clocks Salisbury Cathedral Clock (1386) Harrison’s H 1 sea clock (1737) 34
n. Vidia (still idealized but closer to reality) NVIDIA-terminology • 480 stream processors (“CUDA cores”) - (15 ‘multi-processors’ x 32 cuda-cores each) • SIMT execution
NVIDIA Ge. Force GTX 480 (a multiprocessor) CUDA ‘core’ • A multiprocessor contains 32 cores • Two groups of threads (warps) are selected each clock (decode, fetch, execute two instruction streams in parallel) • Up to 48 warps are interleaved totalling 1536 CUDA threads / multiprocessor
So far: Processig Next: Accessing data
K 40: 288 GB/sec; 384 bit width K 40: 12 GB
Three major ideas (employed by all modern processors at varying degrees) Summary - Employ multiple processing cores so far - Simpler cores (embrace thread-level parallelism over ILP - Amortize instruction stream processing over cores (SIMD) - Increase compute capability with little extra cost - Use multi-threading to make more efficient use of processing resources (hide latencies, fill available resources) Due to high arithmetic capability on modern chips, many parallel applications (on both CPUs and GPUs) are bandwidth bound GPUs push throughput computing to extreme scale (in #threads) - Notable differences in memory system design
Program Flow and Host-Level Issues
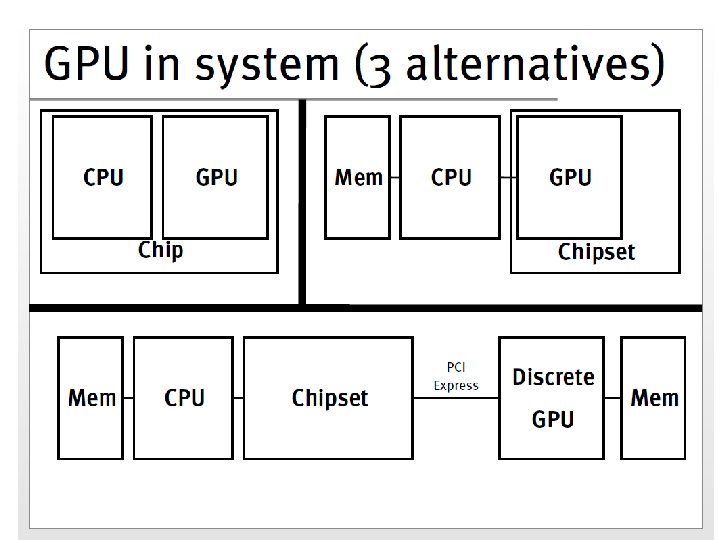
GPU Architecture Host Machine GPU Multiprocessor N Multiprocessor 2 Multiprocessor 1 Shared Memory Registers Processor 1 Processor 2 Registers Instruction Processor M Unit Constant Memory Host Texture Memory Global Memory
ØSIMD Architecture. ØFour memories. • Device (a. k. a. global) slow – 400 -600 cycles access latency large – 1 GB – 12 GB • Shared fast – ~4 cycles access latency small – 128 KB • Texture – read only • Constant – read only
GPU Architecture – Program Flow 1. Preprocessing 3 2. Data transfer in 3. GPU Processing 4. Data transfer out 5. Postprocessing 1 2 4 5 1 2 3 4 5 TTotal = TPreprocesing + TData. Hto. G + TProcessing + TData. Gto. H + TPost. Proc
Outline • Hardware • Software - Programming Model - Optimizations
Add vectors
Programming Model: Software representation of the Hardware
GPU Programming Model Block Kernel: A function on the grid
GPU Programming Model
GPU Programming Model
GPU Programming Model In reality scheduling granularity is a warp (32 threads) 4 cycles to complete a single instruction by a warp
GPU Programming Model • In reality scheduling granularity is a warp (32 threads) 4 cycles to complete a single instruction by a warp • Threads in a Block can share state through shared memory • Threads in the Block can synchronize • Global atomic operations
Optimizations - Memory • Use shared memory • Use texture (1 D, 2 D, or 3 D) and constant memory • Avoid shared memory bank conflicts • Coalesced memory access (one approach: padding)
Warps and memory access coalescing • The cores of an NVidia GPU are referred to as “streaming multiprocessors” • Each “streaming multiprocessor” can operate on 32 data items in parallel - Similar to vector processing • The “threads” on GPUs on only one single item • “Streaming multiprocessors” gather groups of 32 threads together into one “warp” - Threads are adjacent in space • The “streaming multiprocessor” executes an instruction from each of the 32 threads in parallel - Nvidia calls this “single instruction multiple thread” (SIMT) - Like vector processing, SIMT is a subset of SIMD parallel architectures
Warps and memory access coalescing • Each “thread” within a warp performs the same operations - Except with branching, where only one side of the branch can make progress at a time • When the instruction is a memory operation, all threads attempt a load or store
Optimizations - Memory
Optimizations - Memory Global Memory Non-Coalesced Access
Shared memory banks Shared memory is organized multiple “banks”. Bank 0 Concurrent accesses to the same bank will be serialized (bank conflict) slow down. Bank 1. . . Bank 15 Banks are interleaved. Therefore, we can access data that is spread sequentially across banks in parallel Bank 0 0 Bank 1 4 8 Bank 2 16 4 bytes. . .
Optimizations - Computation • Use 1000 s of threads to best use the GPU hardware • Use Full Warps (32 threads) (use blocks multiple of 32). • Lower code branch divergence. • Avoid synchronization • Loop unrolling (fewer instructions, space for compiler optimizations)
Summary • GPUs are highly parallel devices. • Easy to program for (functionality). • Hard to optimize for (performance). • Optimization: - Many optimization, but often you do not need them all (Iteration of profiling and optimization) - May bring hard tradeoffs (More computation vs. less memory, more computation vs. better memory access, . . etc).