CS 152 Computer Architecture and Engineering Lecture 6









. Only read behavior shown.")










 ID (Decode) IR I-Cache EX (ALU) IR")
 ID (Decode) IR I-Cache Branch Predictor Predictions")

![Address of BNEZ instruction 0 b 011[. . ]010[. . ]100 18 bits 12](https://slidetodoc.com/presentation_image_h2/bd50770f915c74cc03aad7ec0392fedd/image-24.jpg "Address of BNEZ instruction 0 b 011[. . ]010[. . ]100 18 bits 12")
 Branch History Table Entry Prediction for next branch. (1 =")





![Spatial branch predictor (BTB, tag not shown) 0 b 0110[. . . ]01001000 BEQZ](https://slidetodoc.com/presentation_image_h2/bd50770f915c74cc03aad7ec0392fedd/image-31.jpg "Spatial branch predictor (BTB, tag not shown) 0 b 0110[. . . ]01001000 BEQZ")




- Slides: 36
CS 152 Computer Architecture and Engineering Lecture 6 – Superpipelining + Branch Prediction 2014 -2 -6 John Lazzaro (not a prof - “John” is always OK) TA: Eric Love www-inst. eecs. berkeley. edu/~cs 152/ Play: CS 152: L 6: Superpipelining + Branch Prediction UC Regents Spring 2014 © UCB
Today: First advanced processor lecture Super-pipelining: Beyond 5 stages. Short Break. Branch prediction: Can we escape control hazards in long CPU pipelines? CS 152: L 6: Superpipelining + Branch Prediction UC Regents Spring 2014 © UCB
From Appendix C: Filling the branch delay slot
Superpipelining CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
5 Stage Pipeline: A point of departure Seconds Program = Instructions Program Cycles Instruction Seconds Cycle Filling a t l l c e d f e r lay sl e g P hin o t s ( b c ranch ca , load) At best, the 5 -stage pipeline executes one instruction per clock, with a clock period determined by the slowest stage Processor has no “multi-cycle” instructions (ex: multiply with an accumulate register) CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
Superpipelining: Add more stages ! y a d To Goal: Reduce critical path by adding more pipeline stages. Example: 8 -stage ARM XScale: extra IF, ID, data cache stages. Difficulties: Added penalties for load delays and branch misses. Ultimate Limiter: As logic delay Also, power! goes to 0, FF clk-to-Q and setup. CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
5 Stage Note: Some stages now overlap, some instructions take extra stages. IF IR ID+RF IR IF now ta kes 2 sta ges (pipeline d I-cache ) ID and EX IR MEM IR WB CS 194 -6 L 9: Advanced Processors I 8 Stage ALU spli RF ea ch get a stage. t ov er 3 stag es MEM t akes 2 stages (pipeli ned D -cache ) UC Regents Fall 2008 © UCB
Superpipelining techniques. . . Split ALU and decode logic over several pipeline stages. Pipeline memory: Use more banks of smaller arrays, add pipeline stages between decoders, muxes. Remove “rarely-used” forwarding networks that are on critical path. Creates stalls, affects CPI. Pipeline the wires of frequently used forwarding networks. Also: Clocking tricks (example: use positive-edge AND negative-edge CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
Recall: IBM Power Timing Closure “Pipeline engineering” happens here. . . about 1/3 of project schedule From “The circuit and physical design of the POWER 4 microprocessor”, IBM J Res and Dev, 46: 1, Jan 2002, J. D. Warnock et al. CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
Pipelining a 256 byte instruction memory. Fully combinational (and slow). Only read behavior shown. Can we add two pipeline stages? A 7 -A 0: 8 -bit read address { 3 { A 7 A 6 A 5 A 4 A 3 A 2 3 OE --> Tri-state Q outputs! OE 1 D E M U. X. . OE Byte 0 -31 Byte 32 -63 256 Q Q . . . OE Byte 224 -255 256 Q 256 M U X Data 3 output is 32 bits D 0 -D 31 32 i. e. 4 bytes 256 Each register holds 32 bytes (256 bits) CS 152: L 6: Superpipelining + Branch Prediction UC Regents Spring 2014 © UCB
On a chip: “Registers” become SRAM cells Architects specify number of rows and columns. Word and bit lines slow down as array grows larger! Write Driver Parallel Data I/O Lines Add muxes here to select subset of bits How could we pipeline this memory? See last CS 152: L 6: Superpipelining + Branch Prediction UC Regents Spring 2014 © UCB
RISC CPU 5. 85 million devices 0. 65 million devices
IC processes are optimized for small SRAM cells From Marvell ARM CPU paper: 90% of the 6. 5 million transistors, and 60% of the chip area, is devoted to cache memories. Implication? SRAM is 6 X as dense as logic.
RAM Compilers On average, 30% of a modern logic chip is SRAM, which is generated by RAM compilers. Compile-time parameters set number of bits, aspect ratio, ports, etc. CS 250 L 1: Fab/Design Interface UC Regents Fall 2013 © UCB
ALU: Pipelining Unsigned Multiply * 1011 Facts to remember CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
Building Block: Full-Adder Variant 1 -bit signals: x, y, z, s, Cin, Cout x y z Cin Cout z: one bit of multiplier s x: one bit of multiplicand If z = 1, {Cout, s} <= x + y + Cin If z = 0, {Cout, s} <= y + Cin Verilog for “ 2 -bit entity”, CS 194 -6 L 9: Advanced Processors I y: one bit of the “running sum” UC Regents Fall 2008 © UCB
Put it together: Array computes P = A x B y To pipeline array: z x 0 Place registers between adder stages (in green). 0 0 0 Cout Add registers Cout to delay selected A and B Fully combinational implementation is bits CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
Adding pipeline stages is not enough. . . MIPS R 4000: Simple 8 -stage pipeline Branch stalls are the main reason why pipeline CPI > 1. 2 -cycle load delay, 3 -cycle branch delay. (Appendix C, Figure C. 52) CS 152: L 6: Superpipelining + Branch Prediction UC Regents Spring 2014 © UCB
Branch Prediction CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
Add pipeline stages, reduce clock period Q. Could adding pipeline stages hurt the CPI for an application? A. Yes, due to these problems: ARM XScale 8 stages CS 194 -6 L 9: Advanced Processors I CPI Problem Possible Solution Taken branches cause longer stalls Branch prediction, loop unrolling Cache misses take more clock cycles Larger caches, add prefetch opcodes to ISA UC Regents Fall 2008 © UCB
Recall: Control hazards. . . IF (Fetch) ID (Decode) IR I-Cache EX (ALU) IR MEM IR WB IR We avoiding stalling by (1) adding a branch delay slot, and (2) adding comparator to ID stage If we add more early stages, we must stall. Sample Program Time: t 1 (ISA w/o branch Inst IF I 1: delay slot) I 2: I 1: BEQ R 4, R 3, 25 I 3: I 2: AND R 6, R 5, R 4 I 4: SUB R 1, R 9, R 8 I 3: I 5: I 6: CS 194 -6 L 9: Advanced Processors I t 2 t 3 t 4 t 5 ID IF EX ID IF MEM WB t 6 t 7 t 8 EX stage computes if branch is taken If branch is taken, these instructions MUST NOT complete! UC Regents Fall 2008 © UCB
Solution: Branch prediction. . . IF (Fetch) ID (Decode) IR I-Cache Branch Predictor Predictions A control instr? Taken or Not Taken? If taken, where to? What PC? EX (ALU) IR MEM IR WB IR We update the PC based on the outputs of the branch predictor. If it is perfect, pipe stays full! Dynamic Predictors: a cache of branch history Time: t 1 Inst IF I 1: I 2: I 3: I 4: I 5: I 6: CS 194 -6 L 9: Advanced Processors I t 2 t 3 t 4 t 5 ID IF EX ID IF MEM WB t 6 t 7 t 8 EX stage computes if branch is taken If we predicted incorrectly, these instructions MUST NOT complete! UC Regents Fall 2008 © UCB
Branch predictors cache branch history Address of branch instruction 0 b 0110[. . . ]01001000 30 bits 4096 Branch Target entries. . . 30 -bit address tag Buffer (BTB) target address Branch instruction BNEZ R 1 Loop Branch History Table (BHT) = = = 0 b 0110[. . . ]0010 PC + 4 + Loop = “Hit” At EX stage, update BTB/BHT, kill instructions, if necessary, CS 152: L 6: Superpipelining + Branch Prediction “Taken” Address 2 state bits Drawn as fully associativ e to focus on the essentials. In real designs, “Taken” or always direct“Not Taken” mapped. UC Regents Spring 2014 © UCB
Address of BNEZ instruction 0 b 011[. . ]010[. . ]100 18 bits 12 bits Branch Target Buffer (BTB) 18 -bit address tag 0 b 011[. . . ]01 = Hit target address PC + 4 + Loop “Taken” Address 0% -9 ate 80 cur ac Branch predictor: direct-mapped version As in real-life. . . direct-mapped. . . BNEZ R 1 Loop Branch History Table (BHT) 4096 BTB/BHT entries Update BHT/BTB for next time, once true behavior “Taken” or known “Not Taken” Must check prediction, kill instruction if needed. CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
Simple (” 2 -bit”) Branch History Table Entry Prediction for next branch. (1 = take, 0 = not take) Initialize to 0. D Was last prediction correct? (1 = yes, 0 = no) Initialize to 1. Q D Q After we “check” prediction. . . Flip bit if prediction is not correct and “last predict correct” bit is 0. Set to 1 if prediction bit was correct. Set to 0 if prediction bit was incorrect. Set to 1 if prediction bit flips. We do not change the prediction the first time it is incorrect. Why? This branch taken 10 times, then not ADDI R 4, R 0, 11 taken once (end of loop). The next time loop: SUBI R 4, -1 we enter the loop, we would like to BNE R 4, R 0, loop predict “take” the first time through. CS 194 -6 L 9: Advanced Processors I UC Regents Fall 2008 © UCB
“ 80 -90% accurate” 4096 -entry 2 bit predictor Figure C. 19
Branch Prediction: Trust, but verify. . . Instr Fetch PC D Decode & Reg Fetch Execute I-Cache Q +4 IR IR IR Branch Predictor and BTB A Y Predicted PC Predictions Branch Taken/Not Taken A branch instr? Taken or Not Taken? Logic B If taken, where to? What PC? B P Note instruction type and branch target. Pass to next stage. B Prediction info --> P CS 152: L 6: Superpipelining + Branch Prediction Check all predictions. Take actions if needed (kill instructions, update predictor). Prediction info --> UC Regents Spring 2014 © UCB
Flowchart control for dynamic branch prediction. Figure 3. 22
Spatial Predictors C code snippet: b 1 b 2 b 3 After compilation: We want to predict this branch. Idea: Devote hardware to four 2 -bit predictors for BEQZ branch. P 1: Use if b 1 and b 2 not taken. P 2: Use if b 1 taken, b 2 not taken. P 3: Use if b 1 not taken, b 2 taken. P 4: Use if b 1 and b 2 taken. Track the current taken/not-taken status of b 1 and b 2, and use it to choose from P 1. . . P 4 for BEQZ. . . How? b 1 b 2 b 3 Can b 1 and b 2 help us predict it?
Branch History Register: Tracks global history Instr Fetch PC D Decode & Reg Fetch We choose which predictor I-Cache Q +4 IR IR Branch Predictor and BTB to use (and update) based on the Branch History Register. IR A Y Predicted PC Predictions n e k A branch instr? Taken or Not Taken? Logic B If taken, where to? What PC? B P Prediction info --> CS 152: L 6: Superpipelining + Branch Prediction Ta ch Ta n a t Br No n/ e k Branch History Register D WE Q D Q WE Shift register. Holds taken/not-taken status of last 2 UCbranches. Regents Spring 2014 © UCB
Spatial branch predictor (BTB, tag not shown) 0 b 0110[. . . ]01001000 BEQZ R 3 L 3 Branch History Tables Map PC to index P 1 P 2 P 3 P 4 2 state bits Branch History Register D Q Mux to choose “which branch (bb==2) WE predictor” branch D Q (aa==2) “Taken” or “Not Taken” branch WE For (aa!= bb) CS 152: L 6: Superpipelining + Branch Prediction 95% te ra accu UC Regents Spring 2014 © UCB
Performance For more details on branch prediction: 4096 vs 1024? Fair comparison, matches total # of bits) One BHT (4096 entries) Spatial (4 BHTs, each with 1024 entries) % rate 5 9 cu ac Figure 3. 3
Predict function returns by stacking call info Figure 3. 24
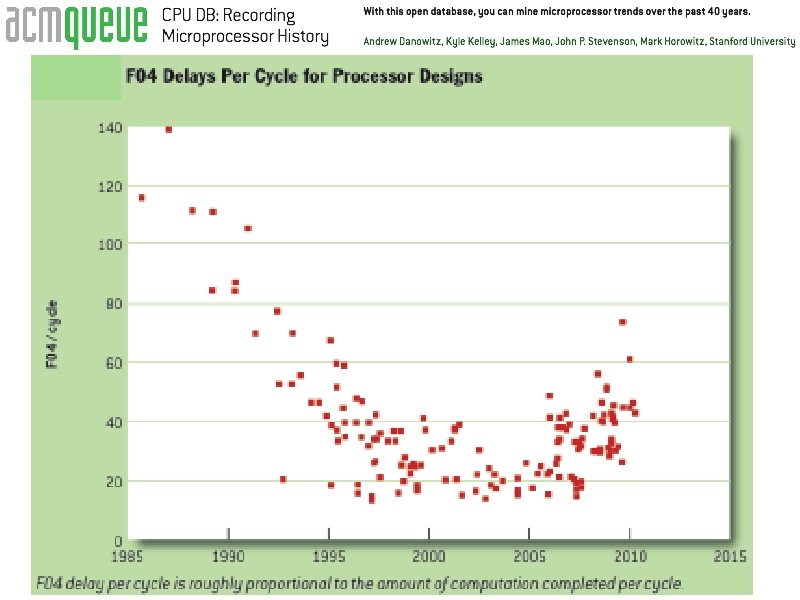
Hardware limits to superpipelining? FO 4 Delays CPU Clock Periods 1985 -2005 MIPS 2000 5 stages Historical limit: about 12 FO 4 s Pentium Pro 10 stages * Pentium 4 20 stages Power wall: Intel Core Duo has 14 stages FO 4: How many fanout-of-4 inverter delays in the clock period. CS 250 L 3: Timing Thanks to Francois Labonte, Stanford UC Regents Fall 2013 © UCB
On Tuesday We turn our focus to memory system design. . . Have a good weekend!