Crawling the Web Outline Basic WWW Technologies Web

Crawling the Web

Outline • Basic WWW Technologies – Web的基本概念 • Basic Crawling – 基本的爬取算法

URI:Uniform Resource Identifier -Uniform Resource Identifiers – URL: Uniform Resource Locators – URN: Uniform Resource Names • • Every resource available on the Web has an address that may be encoded by a URL URIs typically consist of three pieces: – The naming scheme of the mechanism used to access the resource. (HTTP, FTP) – The name of the machine hosting the resource – The name of the resource itself, given as a path


URI Example • http: //www. w 3. org/TR/123. html • There is a document available via the HTTP protocol • Residing on the machines hosting www. w 3. org • Accessible via the path "/TR"
 • A connection-oriented protocol (TCP) used to carry WWW traffic")
Hypertext Transfer Protocol (HTTP) • A connection-oriented protocol (TCP) used to carry WWW traffic between a browser and a server • One of the transport layer protocol supported by Internet • HTTP communication is established via a TCP connection and server port 80

On a Web server or Hypertext Transfer Protocol daemon, port 80 is the port that the server "listens to" or expects to receive from a Web client, assuming that the default was taken when the server was configured or set up. A port can be specified in the range from 0 -65536 on the NCSA server. However, the server administrator configures the server so that only one port number can be recognized. By default, the port number for a Web server is 80. Experimental services may sometimes be run at port 8080

GET Method in HTTP

HTML Hyperlink • <a href="relations/alumni">alumni</a> • A link is a connection from one Web resource to another • It has two ends, called anchors, and a direction • Starts at the "source" anchor and points to the "destination" anchor, which may be any Web resource (e. g. , an image, a video clip, a sound bite, a program, an HTML document)
 • Anchor text is the hyperlinked words on a web page")
Anchor test (锚文本) • Anchor text is the hyperlinked words on a web page - the words you click on when you click a link. Here‘s an example, reciprocal links, in which “reciprocal links” is the anchor text. 锚文本主要是为访问者提供指向网页内容的说 明。

Outline • Basic WWW Technologies – Web的基本概念 • Basic Crawling – 基本的爬取算法
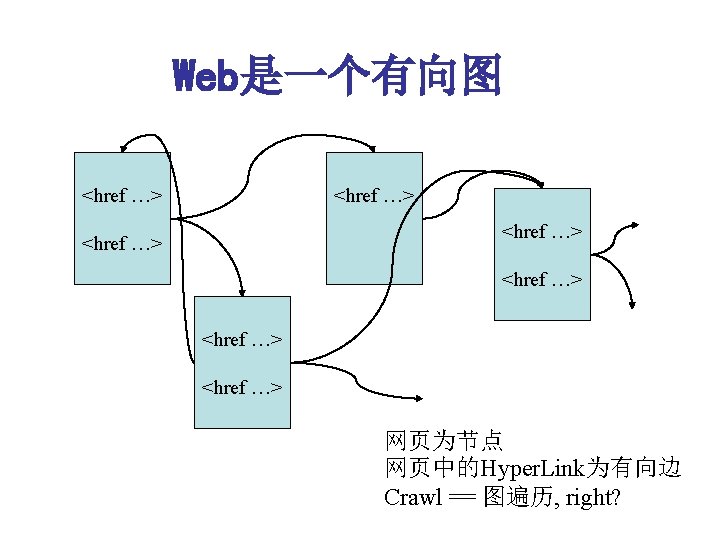

Completeness Observations Completeness is not guaranteed • 假设从一个page出发能到达web上的任何一个 page. • 实际情况并不一定这样 • How to make it better: – more seeds, more diverse seeds, – port scanner maybe help

常用算法 • Depth First Search • Width First Search

Depth-First Search 1 2 3 8 5 6 4 numbers = order in which nodes are visited 7 9 10
 Initialize COLLECTION <big file of URL-page pairs>//结果 存储 Initialize")
Depth-First Search PROCEDURE SPIDER(G, {SEEDS}) Initialize COLLECTION <big file of URL-page pairs>//结果 存储 Initialize VISITED <big hash-table>//已访问URL列表 For every ROOT in SEEDS Initialize STACK <stack data structure>//待爬取URL栈 Let STACK : = push(ROOT, STACK) While STACK is not empty, Do URLcurr : = pop(STACK) Until URLcurr is not in VISITED insert-hash(URLcurr, VISITED) PAGE : = look-up(URLcurr)//爬取页面 STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, //链接提取 push(URLi, STACK) Return COLLECTION

Width-first Search 1 2 5 numbers = order in which nodes are visited 4 3 6 7 10 8 9
 Initialize COLLECTION <big file of URL-page pairs>//结果 存储 Initialize")
Width-first Search PROCEDURE SPIDER(G, {SEEDS}) Initialize COLLECTION <big file of URL-page pairs>//结果 存储 Initialize VISITED <big hash-table>//已访问URL列表 For every ROOT in SEEDS Initialize QUEUE <queue data structure>//待爬取URL队 列 Let QUEUE : = En. Queue(ROOT, QUEUE) While QUEUE is not empty, Do URLcurr : = De. Queue(QUEUE) Until URLcurr is not in VISITED insert-hash(URLcurr, VISITED) PAGE : = look-up(URLcurr)//爬取页面 STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, //链接提取 En. Queue(URL, QUEUE) Return COLLECTION


Best first Algorithm Input: user’s query Q, and a list L of URLs, sim(Q, P)> , P L; Output: A page set S, where sim(Q, P)> ; P S; S=L; OPEN = L ; while OPEN != null do 1. Pick the best node B from OPEN. // measured by sim 2. search pages pointed by page B 3. For each page p do: a. If it has not been recorded: compute sim(p, Q), add it to S and Open if sim(p, Q)> , and record its parent B. done








- Slides: 28