Crawling the Web http net pku edu cnwbia

Crawling the Web http: //net. pku. edu. cn/~wbia 黄连恩 hle@net. pku. edu. cn 北京大学信息 程学院 09/09/2014

本次课大纲 n How to collect data from Web? n n Build a Crawler High Performance Web Crawler Distributed Crawling/Incremental Crawling State-of-art technology

Build a Crawler!

Refer to HTML 4. 01 Specification

GET Method in HTTP Refer to RFC 2616 HTTP Made Really Easy
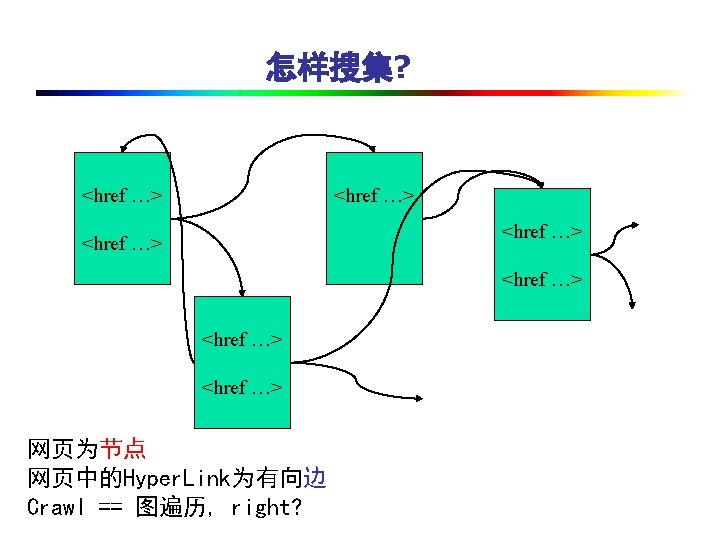

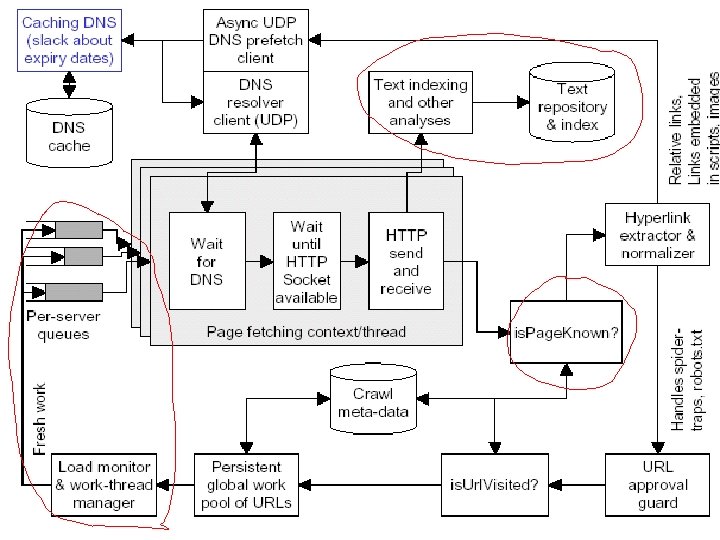
系统框图 Fetcher Pre. Processor Extractor Frontier Writer Post. Processor
 Let ROOT : = any URL from G")
Core Algorithms I PROCEDURE SPIDER 1(G) Let ROOT : = any URL from G Initialize STACK <stack data structure> Let STACK : = push(ROOT, STACK) Initialize COLLECTION <big file of URL-page pairs> While STACK is not empty, URLcurr : = pop(STACK) PAGE : = look-up(URLcurr) STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, push(URLi, STACK) Return COLLECTION
 • 重复搜集, Let ROOT : = any")
Review of Algorithm I PROCEDURE SPIDER 1(G) • 重复搜集, Let ROOT : = any URL from G Initialize STACK <stack data • 遇到回路会无限循环 structure> • G如果不连通呢? Let STACK : = push(ROOT, STACK) Initialize COLLECTION <big file of URL-page pairs> • G如果大到STACK容纳不下呢? While STACK is not empty, • 要控制搜集G的一部分呢? URLcurr : = pop(STACK) PAGE : = look-up(URLcurr) STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, push(URLi, STACK) Return COLLECTION
 Initialize COLLECTION <big file of")
A More Complete Correct Algorithm PROCEDURE SPIDER 4(G, {SEEDS}) Initialize COLLECTION <big file of URL-page pairs> STACK Initialize VISITED <big hash-table> For every ROOT in SEEDS 用disk-based heap结构实现 Initialize STACK <stack data structure> Let STACK : = push(ROOT, STACK) While STACK is not empty, Do URLcurr : = pop(STACK) Until not in in COLLECTION Until. URLcurr not VISITED curr is is insert-hash(URLcurr, VISITED) PAGE : = look-up(URLcurr) STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, push(URLi, STACK) Return COLLECTION





Robot exclusion • 检查 n • 在服务器文档根目录中的文件,robots. txt, 包含一个 路径前缀表,crawlers不应该跟进去抓文档,例如 #Alta. Vista Search User-agent: Alta. Vista Intranet V 2. 0 W 3 C Webreq Disallow: /Out-Of-Date #exclude some access-controlled areas User-agent: * Disallow: /Team Disallow: /Project Disallow: /Systems 限制只是对crawlers,一般浏览无妨 n “君子协定”(你的crawler可以不遵守)

Server traps n 防止系统异常 n n 病态HTML文件 n 例如,有的网页含有68 k. B null字符 误导Crawler的网站 n 用CGI程序产生无限个网页 n 用软目录创建的很深的路径 n n www. troutbums. com/Flyfactory/hatchline/hatchline/flyfactory/flyfactory/flyfa ctory/hatchline HTTP服务器中的路径重映射特征

Web Crawler need… n 快 Fast n n 可扩展性 Scalable n n Traps, errors, crash recovery 持续搜集 Continuous n n Do. S(Deny of Service Attack), robot. txt 健壮 Robust n n Parallel , distributed 友好性 Polite n n Bottleneck? Network utilization Batch or incremental 时新性Freshness

High Performance Web Crawler

系统框图 Fetcher Pre. Processor Extractor Frontier Writer Post. Processor

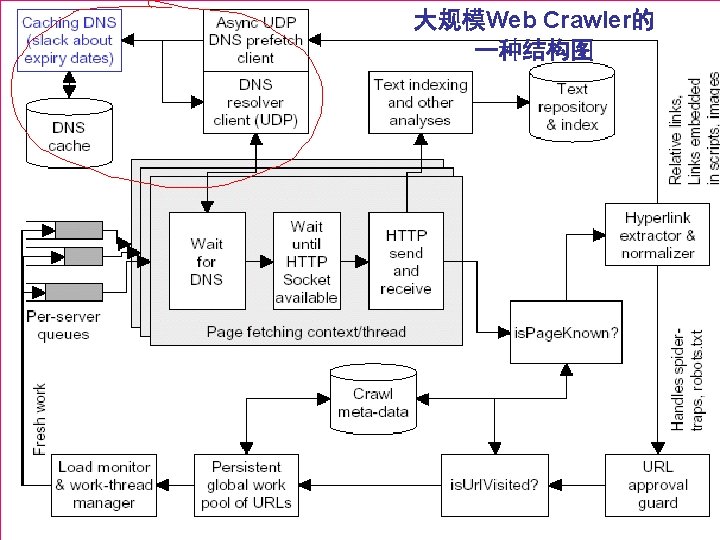
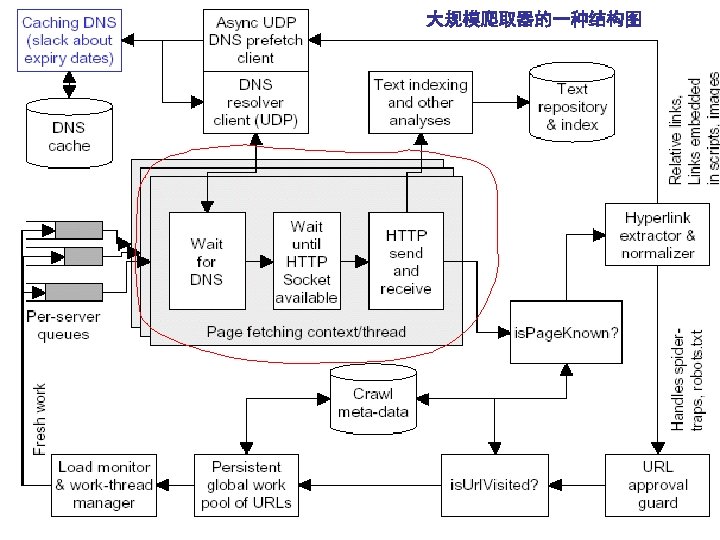
大规模Web Crawler的 一种结构图 Writer Fetcher Extractor Frontier Writer

DNS resolver n n n Typical DNS request are synchronized! DNS can take long time to resolve host names Host name may never resolve




 Dns. Lookup() Send Queue Cache polling/select send")
Asynchronous Concurrent DNS Client Prefetch Host. Name() Dns. Lookup() Send Queue Cache polling/select send recv DNS server

Page fetching n 获取一个网页需要多少时间? n n Problem: n n 局域网的延迟在 1 -10 ms,带宽为 10 -1000 Mbps, Internet 的延迟在 100 -500 ms,带宽为 0. 010 -2 Mbps 在一个网络往返时间RTT为 200 ms的广域网中,服务器 处理时间SPT为 100 ms,那么TCP上的事务时间就大约 500 ms(2 RTT+SPT) 网页的发送是分成一系列帧进行的,则发送1个网页的 时间量级在(13 KB/1500 B) * 500 ms ≈4 s ? network connection and transfer overheads Solutions: n Multiple concurrent fetches




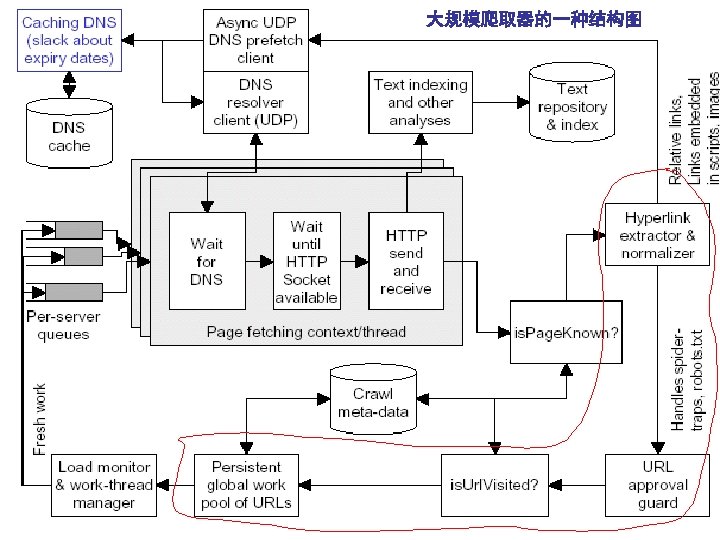


Is. URLVisisted: Bloom filter n n n Bloom filters are compact data structures for probabilistic representation of a set in order to support membership queries. 查找集合是否包含一个元素( 查找表) False Positive n 可由参数n(string number), k(hash function number), m(bit -array size)调节

Simple Example n Use a bloom filter of 16 bits n n n h 1(key) = key mod 16 h 2(key) = key mod 14 + 2 Insert numbers 27, 18, 29 and 28 1 1 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 n Check for 22: n n H 1(22) = 6, h 2(22) = 10 (not in filter) Check for 51 n H 1(51) = 3, h 2(51) = 11 (false positive)


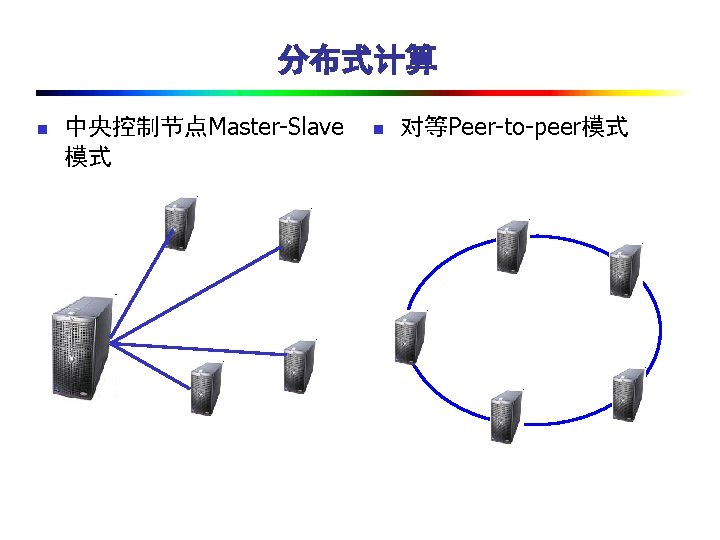
Distributed Crawling

 a value (e. g. , 32 -bit")
Hashing n 从一个值均匀分布的 hash 函数开始: n h(name) a value (e. g. , 32 -bit integer) h(x) values … 12 n 把 values 映射到 hash buckets n n 一般取模 mod (# buckets) 0 8 4 buckets { 0 1 2 3 把 items 放到buckets n 冲突,需要 chain解决冲突 overflow chain 45



Basic Ideas n 使用一个巨大的hash key空间 n n n SHA-1 hash: 20 B, or 160 bits 把它组织成 “circular ring” (在 2160 处回到 0) 我们把 objects’ keys (这里是URL) 和nodes’ IP addresses 都hash映射到一个hash key 空间 n n “www. pku. edu. cn” SHA-1 K 10 130. 140. 59. 2 SHA-1 N 10 48

Hashes a Key to its Successor k 10 k 120 Node ID N 10 k 112 k 11 N 100 Circular hash ID Space k 99 Key Hash k 30 N 32 k 33 k 40 N 80 k 70 k 52 k 65 N 60 49

Hashes a Key to its Successor k 10 k 120 Node ID N 10 k 112 k 11 N 100 Circular hash ID Space k 99 Key Hash k 30 N 32 k 33 k 40 N 80 k 70 k 52 k 65 N 60 N 80 is down… 50

Incremental Crawling


State-of-art Crawling Tech
")
Sitemaps: Above and Beyond the Crawl of Duty Sitemaps! Uri Schonfeld (Google and UCLA) Narayanan Shivakumar (Google) Copyright Uri Schonfeld, shuri. org April 2009

Dream of the Perfect Crawl 1. Users Have High Expectations: n n n 2. Search Engines Dream of the perfect crawl: n n 3. Coverage: Every page should be findable Freshness: Latest event, viral video, . . . Deep Web: ajax, flash, silverlight, . . Everything the users want …but efficient: n No 404 s n No duplicates Sitemaps to the rescue. . .

Sitemaps n http: //www. sitemaps. org

Conclusion and Future Work 1. 2. 3. 4. 5. 6. Large scale study, real data You cannot stop Discovery… yet. Presented metrics for freshness and coverage. Sitemaps evaluated for coverage and freshness. Presented Algorithm to combine Sitemaps & Discovery To Be Done 1. Good news: tons of future work 2. Duplicates not solved on web-server side either. 3. Better Pings. 4. Ranking Sitemaps URLs can be a challenge. Copyright Uri Schonfeld, shuri. org April 2009

IRLbot: Scaling to 6 Billion Pages and Beyond n n WWW 2008 Best Paper Award! In our recent experiment that lasted 41 days, IRLbot running on a single server successfully crawled 6. 3 billion valid HTML pages ($7. 6$ billion connection requests) and sustained an average download rate of 319 mb/s (1, 789 pages/s)

Challenges n We identified several bottlenecks in building an efficient large-scale crawler and presented our solution to these problems n n n Scalability n Low-overhead disk-based data structures Reputation and spam n Non-BFS crawling order Politeness n Real-time reputation to guide the crawling rate

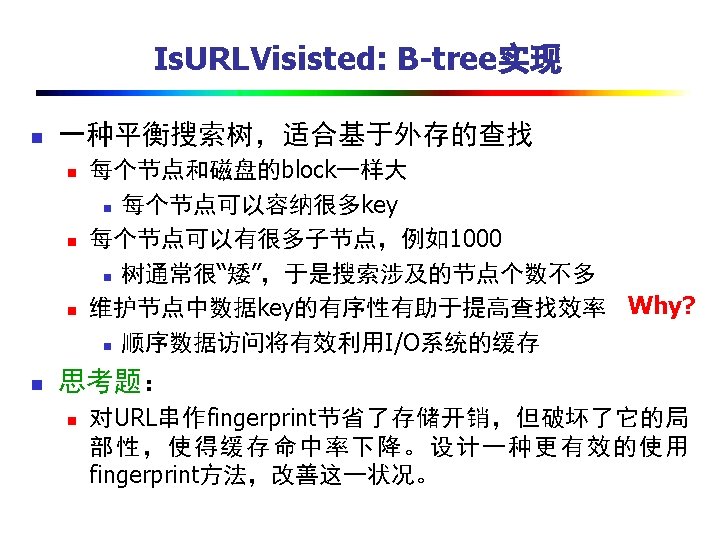
本次课小结 n Crawler面临的难题 n n 实现高效率的基本技术 n n Scalable, fast, polite, robust, continuous Cache Prefetch Concurrency n 多进程/多线程 n 异步I/O 有趣的技术 n n Bloom filter Consistent Hashing

Thank You! Q&A

- Slides: 62