CPU time Seconds Instructions Cycles Seconds x Program



 cslab@ntua 2017 -2018 Reg DMem Ifetch Reg ALU O")
 Instruction fetch 0 M u x")
 Instruction decode 0 M u x")
 Execution 0 M u x 1 IF/ID")
 Memory 0 M u x 1 IF/ID")
 Writeback 0 M u x 1 IF/ID")

 Instr 2 Instr 3")
 Instr 1 Instr 2 Stall")
 or r 8, r 1,")
























")





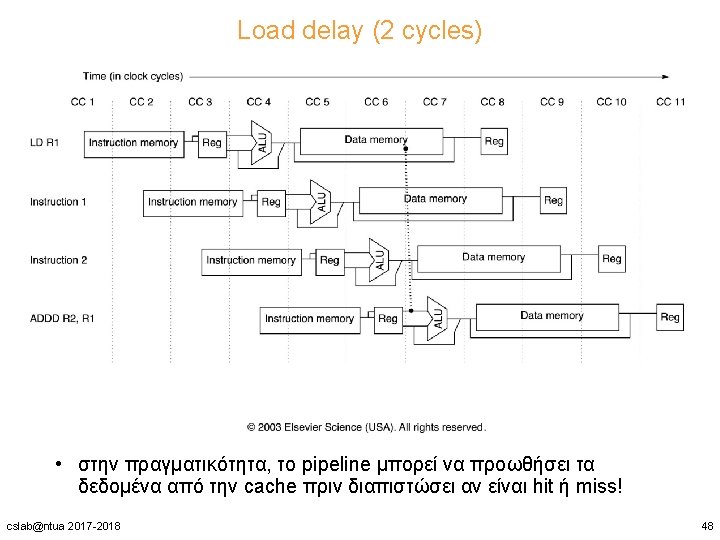
 cslab@ntua 2017 -2018 49")
- Slides: 49
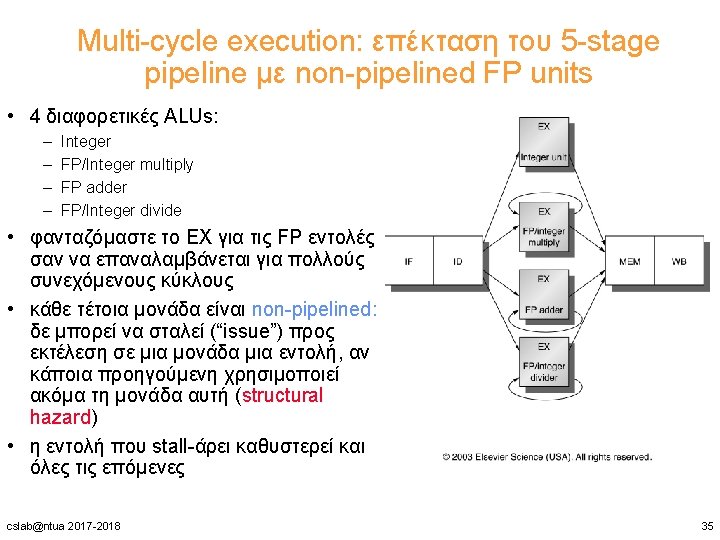
Παράγοντες που επηρεάζουν την επίδοση της CPU time = Seconds = Instructions Cycles Seconds ---------------- x -------Program Instruction Cycle Instr. count CPI Clock rate Program Χ Compiler Χ Χ Instruction Set Architecture (ISA) Οργάνωση X Χ Χ X Χ Τεχνολογία cslab@ntua 2017 -2018 Χ 2
5 -Stage Pipelined Datapath Instruction Fetch Execute Addr. Calc Instr. Decode Reg. Fetch Next SEQ PC Adder Zero? RS 1 Imm IR ← Mem[PC] RD RD RD MUX Sign Extend MEM/WB Data Memory EX/MEM MUX ALU MUX ID/EX Reg File IF/ID Memory Address RS 2 WB Data 4 Write Back MUX Next PC Memory Access PC ← PC + 4 cslab@ntua 2017 -2018 A ← Reg[IRrs] rslt ← B ← Reg[IRrt] A op. IRop B Mem[rslt] Reg[IRrd]←WB 3
Διάγραμμα χρονισμού Time (clock cycles) cslab@ntua 2017 -2018 Reg DMem Ifetch Reg ALU O r d e r Ifetch ALU I n s t r. Cycle 6 Cycle 7 ALU Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Reg Reg DMem Reg 4
Παράδειγμα για την εντολή lw: Instruction Fetch (IF) Instruction fetch 0 M u x 1 IF/ID ID/EX EX/MEM MEM/WB Add Add result 4 PC Address Instruction memory Instruction Shift left 2 Read register 1 Read data 1 Read register 2 Registers Read Write data 2 register Write data 0 M u x 1 Zero ALU result Address Data memory Write data 16 cslab@ntua 2017 -2018 Sign extend Read data 1 M u x 0 32 5
Παράδειγμα για την εντολή lw: Instruction Decode (ID) Instruction decode 0 M u x 1 IF/ID ID/EX EX/MEM MEM/WB Add Add result 4 PC Address Instruction memory Instruction Shift left 2 Read register 1 Read data 1 Read register 2 Registers Read Write data 2 register Write data 0 M u x 1 Zero ALU result Address Data memory Write data 16 cslab@ntua 2017 -2018 Sign extend Read data 1 M u x 0 32 6
Παράδειγμα για την εντολή lw: Execution (EX) Execution 0 M u x 1 IF/ID ID/EX EX/MEM MEM/WB Add Add result 4 PC Address Instruction memory Instruction Shift left 2 Read register 1 Read data 1 Read register 2 Registers Read Write data 2 register Write data 0 M u x 1 Zero ALU result Address Data memory Write data 16 cslab@ntua 2017 -2018 Sign extend Read data 1 M u x 0 32 7
Παράδειγμα για την εντολή lw: Memory (MEM) Memory 0 M u x 1 IF/ID ID/EX EX/MEM MEM/WB Add Add result 4 PC Address Instruction memory Instruction Shift left 2 Read register 1 Read data 1 Read register 2 Registers Read Write data 2 register Write data 0 M u x 1 Zero ALU result Address Data memory Write data 16 cslab@ntua 2017 -2018 Sign extend Read data 1 M u x 0 32 8
Παράδειγμα για την εντολή lw: Writeback (WB) Writeback 0 M u x 1 IF/ID ID/EX EX/MEM MEM/WB Add Add result 4 PC Address Instruction memory Instruction Shift left 2 Read register 1 Read data 1 Read register 2 Registers Read Write data 2 register Write data 0 M u x 1 Zero ALU result Address Data memory Write data 16 cslab@ntua 2017 -2018 Sign extend Read data 1 M u x 0 32 9
Παράδειγμα structural hazard: ένα διαθέσιμο memory port Time (clock cycles) Instr 2 Instr 3 Instr 4 cslab@ntua 2017 -2018 DMem Ifetch Reg ALU Instr 1 Reg ALU Ifetch ALU O r d e r Load ALU I n s t r. Cycle 6 Cycle 7 ALU Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Reg Reg DMem Reg 11
Παράδειγμα structural hazard: επίλυση με stall Time (clock cycles) Instr 1 Instr 2 Stall Instr 3 cslab@ntua 2017 -2018 Reg DMem Ifetch Reg ALU Ifetch Bubble Cycle 6 Cycle 7 Reg Bubble Ifetch Reg DMem Bubble Reg Bubble ALU O r d e r Load ALU I n s t r. ALU Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Bubble DMem Reg 12
Παράδειγμα data hazard στον r 1 Time (clock cycles) or r 8, r 1, r 9 xor r 10, r 11 cslab@ntua 2017 -2018 DMem Ifetch Reg ALU and r 6, r 1, r 7 Reg ALU O r d e r sub r 4, r 1, r 3 Ifetch WB ALU add r 1, r 2, r 3 MEM ALU I n s t r. ID/RF EX ALU IF Reg Reg DMem Reg 13
Προώθηση DMem Ifetch Reg ALU and r 6, r 1, r 7 Reg ALU sub r 4, r 1, r 3 Ifetch ALU O r d e r add r 1, r 2, r 3 ALU I n s t r. ALU Time (clock cycles) or r 8, r 1, r 9 xor r 10, r 11 Reg Reg DMem Reg • μειώνονται τα RAW hazards cslab@ntua 2017 -2018 18
Αλλαγές στο hardware για την υποστήριξη προώθησης Next. PC mux MEM/WR EX/MEM ALU mux ID/EX Registers Data Memory mux Immediate Προώθηση ΕΧ->ΕΧ, ΜΕΜ->ΕΧ cslab@ntua 2017 -2018 19
Προώθηση ΜΕΜ->ΜΕΜ or r 8, r 6, r 9 xor r 10, r 9, r 11 cslab@ntua 2017 -2018 DMem Ifetch Reg ALU sw r 4, 12(r 1) Reg ALU lw r 4, 0(r 1) Ifetch ALU O r d e r add r 1, r 2, r 3 ALU I n s t r. ALU Time (clock cycles) Reg Reg DMem Reg 20
Τα data hazards δεν εξαφανίζονται πλήρως με την προώθηση and r 6, r 1, r 7 or r 8, r 1, r 9 cslab@ntua 2017 -2018 Reg DMem Ifetch Reg Reg DMem ALU O r d e r sub r 4, r 1, r 6 Ifetch ALU lw r 1, 0(r 2) ALU I n s t r. ALU Time (clock cycles) Reg DMem Reg 21
Τα data hazards δεν εξαφανίζονται πλήρως με την προώθηση and r 6, r 1, r 7 or r 8, r 1, r 9 cslab@ntua 2017 -2018 Reg DMem Ifetch Reg Bubble DMem Ifetch Bubble Reg Bubble Ifetch Reg Reg DMem ALU O r d e r sub r 4, r 1, r 6 Ifetch ALU lw r 1, 0(r 2) ALU I n s t r. ALU Time (clock cycles) Reg DMem 22
Αναδιάταξη εντολών για την αποφυγή RAW hazards Πώς μπορούμε να παράγουμε γρηγορότερο κώδικα assembly για τις ακόλουθες πράξεις? a = b + c; d = e – f; Slow code: LW LW ADD SW LW LW SUB SW cslab@ntua 2017 -2018 Rb, b Rc, c Ra, Rb, Rc a, Ra Re, e Rf, f Rd, Re, Rf d, Rd Fast code: LW LW LW ADD LW SW SUB SW Rb, b Rc, c Re, e Ra, Rb, Rc Rf, f a, Ra Rd, Re, Rf d, Rd 23
36: xor r 10, r 11 cslab@ntua 2017 -2018 Ifetch Reg DMem Ifetch Reg ALU 18: or r 6, r 1, r 7 Reg ALU 14: and r 2, r 3, r 5 Ifetch ALU 10: beq r 1, r 3, 36 ALU Κίνδυνοι ελέγχου στις εντολές διακλάδωσης: stalls 2 σταδίων DMem Reg Reg DMem Reg 24
Τροποποιήσεις στο pipeline Instruction Fetch Next SEQ PC Write Back Adder Zero? RS 1 WB Data MUX Sign Extend RD MEM/WB Data Memory EX/MEM ALU MUX ID/EX Reg File IF/ID Memory Address RS 2 Imm cslab@ntua 2017 -2018 Memory Access MUX Next PC 4 Execute Addr. Calc Instr. Decode Reg. Fetch RD RD 26
4 εναλλακτικές προσεγγίσεις για την αντιμετώπιση των control hazards #4: Delayed Branches branch instruction sequential successor 1 sequential successor 2. . . . sequential successorn branch target if taken Branch delay μήκους n: οι εντολές εκτελούνται είτε το branch είναι Taken είτε όχι – delay ενός slot: επιτρέπει απόφαση και υπολογισμό διεύθυνσης-στόχου στο 5 -stage pipeline χωρίς stalls cslab@ntua 2017 -2018 28
Εναλλακτικά. . . Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls μέτρο της μέγιστης απόδοσης που μπορούμε να έχουμε με την εκάστοτε υλοποίηση του pipeline cslab@ntua 2017 -2018 32
Εναλλακτικά. . . Pipeline CPI = υπερβαθμωτή εκτέλεση Ideal pipeline CPI + register renaming δυναμική εκτέλεση loop unrolling static scheduling, software pipelining cslab@ntua 2017 -2018 προώθηση Structural Stalls + Data Hazard Stalls + Control Stalls πρόβλεψη διακλαδώσεων υποθετική εκτέλεση delayed branches, branch scheduling 33
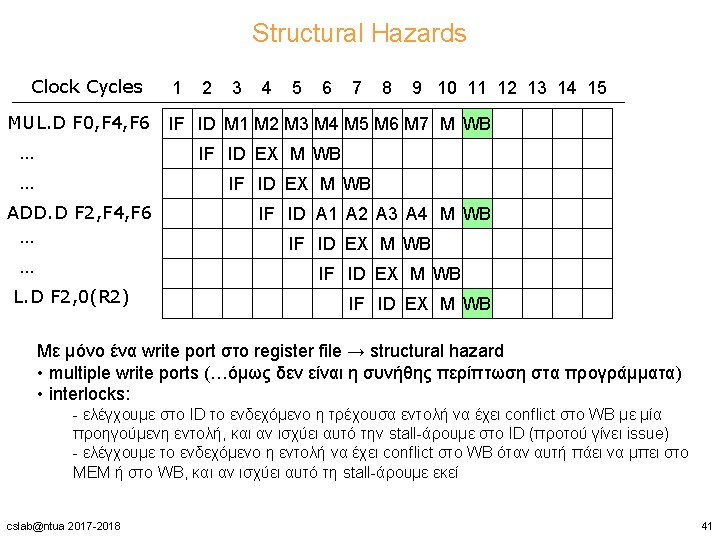
Παράδειγμα Clock Cycles MUL. D ADD. D L. D S. D cslab@ntua 2017 -2018 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 IF ID M 1 M 2 M 3 M 4 M 5 M 6 M 7 M WB IF ID A 1 A 2 A 3 A 4 M WB IF ID EX M WB 38
RAW hazards και αύξηση των stalls Clock Cycles L. D F 4, 0(R 2) MUL. D F 0, F 4, F 6 ADD. D F 2, F 0, F 8 S. D F 2, 0(R 2) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 IF ID EX M WB IF ID S M 1 M 2 M 3 M 4 M 5 M 6 M 7 M WB IF S ID S S S A 1 A 2 A 3 A 4 M WB IF S S S ID EX S S S M WB • full bypassing/forwarding • η S. D πρέπει να καθυστερήσει έναν κύκλο παραπάνω για να αποφύγουμε το conflict στο ΜΕΜ της ADD. D cslab@ntua 2017 -2018 40
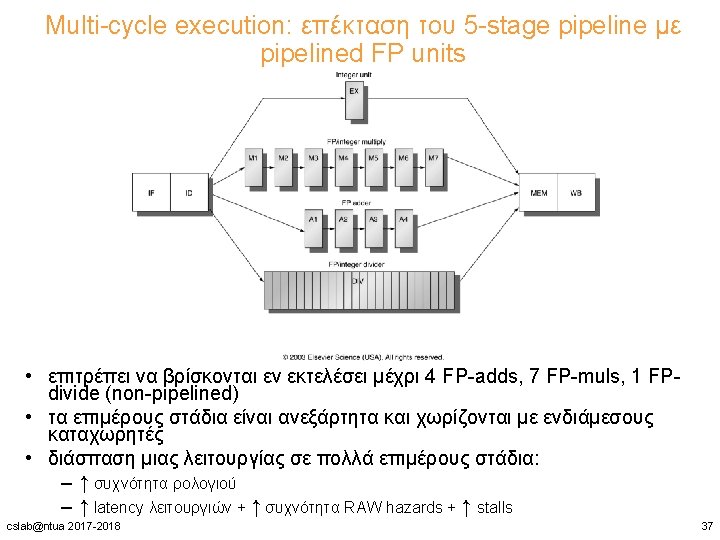
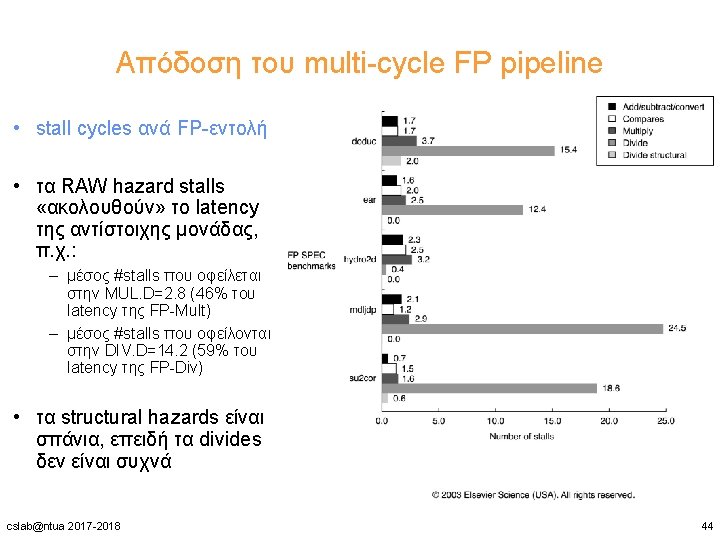
Απόδοση του multi-cycle FP pipeline • stalls ανά εντολή + breakdown • από 0. 65 μέχρι 1. 21 stalls ανά εντολή • κυριαρχούν τα RAW hazard stalls ( «FP result stalls» ) cslab@ntua 2017 -2018 45
Case-study: MIPS R 4000 Pipeline Instruction Memory RF Reg EX ALU IS IF DF DS Data Memory TC WB Reg Branch target and condition eval. • Deeper Pipeline (superpipelining): επιτρέπει υψηλότερα clock rates • Fully pipelined memory accesses (2 cycle delays για loads) • Predicted-Not-Taken πολιτική – Not-taken (fall-through) branch : 1 delay slot – Taken branch: 1 delay slot + 2 idle cycles cslab@ntua 2017 -2018 46
Case-study: MIPS R 4000 Pipeline IS IF Instruction Memory complete ICache access cslab@ntua 2017 -2018 decode, register read, hazard checking, ICache hit detection RF 1 st half of DCache access EX Reg ALU PC selection, initiation of ICache access effective address calculation, ALU operation, branchtarget computation, condition evaluation DF Dcache hit detection DS Data Memory complete DCache access TC WB Reg register write-back 47
Branch delay (3 cycles) cslab@ntua 2017 -2018 49