Correlation and Regression Correlation Correlation is a statistical











 and independent")





 is the average amount of change in")


- Is the percent of the variance in the dependent")

















. Ø Some")










 then it may")



- Slides: 54
Correlation and Regression
Correlation. Ø ‘Correlation’ is a statistical tool which measure the strength of linear relationship between two variables. Ø It can not measure strong non-linear relationship. Ø It can not measure Cause and Effect. Ø “Two variables are said to be in correlated if the change in one of the variables results in a change in the other variable”. Ø Types of Correlation ü There are two important types of correlation. ü (1) Positive and Negative correlation and ü (2) Linear and Non – Linear correlation.
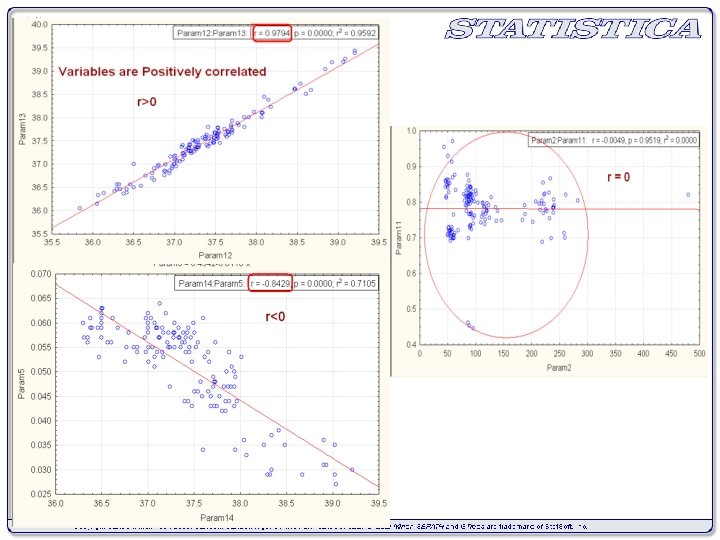
Ø Positive and Negative Correlation ü If the values of the two variables deviate in the same direction i. e. if an increase (or decrease) in the values of one variable results, on an average, in a corresponding increase (or decrease) in the values of the other variable the correlation is said to be positive. v Some examples of series of positive correlation are: ü Heights and weights; ü Household income and expenditure; ü Price and supply of commodities; ü Amount of rainfall and yield of crops. Ø Correlation between two variables is said to be negative or inverse if variables deviate in opposite direction v Some examples of series of negative correlation are: ü Volume and pressure of perfect gas; ü Current and resistance [keeping the voltage constant]. ü Price and demand of goods etc.
Ø The Coefficient of Correlation ü It is denoted by ‘r’ which measures the degree of association between the values of related variables given in the data set. ü -1≤ r ≤ 1 ü If r >0 variables are said to be positively correlated. ü If r<0 variables are said to be negatively correlated. ü For any data set if r = +1, they are said to be perfectly correlated positively ü if r = -1 they are said to be perfectly correlated negatively, and ü if r = 0 they are uncorrelated.
Correlation In Statistica. Ø Got to “Statistic” tab and “Basic statistic”. Ø Click “Correlation matrix” tab click ok. Ø If you want to get correlation only on two variables, go to the “Two variable list” and select those two variables which are required. Ø Click ok and then click on summary.
Ø If you want to get the correlation matrix for all variables, go to “Two variable list” tab and click on “select all” tab, click ok. Ø Click the summary , you will get correlation matrix.
Ø To get scatter plot – click on “Scatter plot of variables” and then select the variables and click ok. Ø You will get the scatter plot as it has came in the right side.
Ø To get another kind of Scatter plot click on “Graphs” option. Ø You will get a series of scatter plot for each and every pairs of variable. Ø The second plot is showing one of those.
Regression Ø Regression analysis, in general sense, means the estimation or prediction of the unknown value of one variable from the known value of the other variable. Ø If two variables are significantly correlated, and if there is some theoretical basis for doing so, it is possible to predict values of one variable from the other. This observation leads to a very important concept known as ‘Regression Analysis’. Ø It is specially used in business and economics to study the relationship between two or more variables that are related causally and for the estimation of demand supply graphs, cost functions, production and consumption functions and so on.
Ø Thus, the general purpose of multiple regression is to learn more about the relationship between several independent or predictor variables and a dependent or output variable. Ø Suppose that the Yield in a chemical process depends on Temperature and the Catalyst concentration, a multiple regression that describe this relationship is, Y=b 0+b 1*X 1+b 2*X 2+€ → (a) Where Y = Yield. X 1 = Temp: , X 2 = Catalyst cont: . This is multiple linear regression model with 2 regressors. Ø The term linear is used because equation (a) is a linear function of the unknown parameters bi’s.
Regression Models. § Depending on nature of relationship regression models are two types. Ø Linear regression model, including a. Simple-linear regression (one indep: var. ) b. Multiple-linear regression. Ø Non-Linear regression model, including a. Polynomial regression. b. Exponential regression , etc.
Assumption of Linear regression model. Ø The relationship between Y (dependent variable) and independent variables are linear. Ø The independent variables are mutually independent to each other. Ø The errors are uncorrelated to each other. Ø The error term has fixed variance. Ø The errors are Normally distributed.
Data set and Objective. Ø The current data set has been taken from a chemical process where we have two input or independent parameters , Temperature and Catalyst feed rate Response or output parameter : Viscosity of the yield. Ø 1. 2. 3. Objective. Establish the linear relation of dependent variable with independent variables. Estimate regression coefficients to find out which variable has significant effect on the response variable. Check the model adequacy with the help of assumptions.
Data set.
Assumption of Linearity. Ø First of all, as is evident in the name multiple linear regression, it is assumed that the relationship between variables is linear. Ø In practice this assumption can virtually never be confirmed; fortunately, multiple regression procedures are not greatly affected by minor deviations from this assumption. Ø However, as a rule it is prudent to always look at bivariate scatter plot of the variables of interest. Ø If curvature in the relationships is evident, one may consider either transforming the variables, or explicitly allowing for nonlinear components.
Scatter plot. Ø Go to “Graph” option and select “Scatter plot”. Ø Click on “variable” tab and select the variables in the above way. Ø Click ok and select the option “Multiple” and “Confidence”. This will help you to plot multiple graph in a single window. (If you have large number of variables then plot it separately)
Ø The scatter plot has established linear relationship of the dependent with independent variables. Ø Here Viscosity and Temp are linearly related to each other, but Viscosity and Catalyst concentration are not.
Parameter Estimation. Ø The regression coefficient (beta) is the average amount of change in the dependent (either in positive or negative direction, depending on the sign of ’s) when the independent changes one unit and other independents are held constant. Ø The b coefficient is the slope of the regression line. Ø Intercept (constant, α)- It is the value of dependent variable when all indep: are set to zero. Ø For any independent variable if the corresponding >0, then that variable is positively correlated with dependent variable, negatively otherwise. Ø OLS (ordinary least squares) is used to estimate the coefficients in such a way that the sum of the squared deviations of the distances of all the points to the line is minimized.
Ø The confidence interval of the regression coefficient. We can 95% confident that the real regression coefficient for the population lies within this intervals. Ø If the confidence interval includes 0, then there is no significant linear relationship between x and y. Ø The confidence interval of y – It indicates 95 times out of a hundred, the true mean of y will be within the confidence limits around the observed mean of n sampled. Ø SEE (Standard error of estimate) is the standard deviation of the residuals. In a good model, SEE will be markedly less than the standard deviation of the dependent variable. ü It can be used to compare the accuracy of different models, lesser the value better the model.
Ø Ø ü v v Ø F-test and P-value: Testing the Overall Significance of the Multiple Regression Model. It assume the null hypothesis, H 0: b 1 = b 2 =. . . = bk = 0 H 1: At least one bi does not equal 0. If H 0 is rejected (if p<. 05) we can conclude that, At least one bi differs from zero. The regression equation does a better job of predicting the actual values of y. t-test: Testing the Significance of a Single Regression Coefficient. ü Is the independent variable xi useful in predicting the actual values of y ? For the Individual t-test H 0: bi = 0 H 1: bi ≠ 0 ü If H 0 is rejected (if p<. 05) The related X has a significant contribution on the dependent variable,
Ø R^2 (coefficient of determination)- Is the percent of the variance in the dependent explained uniquely or jointly by the independents. Ø R-squared can also be interpreted as the proportionate reduction in error in estimating the dependent when knowing the independents. Ø Adjusted R-Square It is an adjustment of R-square when one has a large number of independents ü It is possible that R-square will become artificially high simply because some independent variable "explain" small parts of the variance of the dependent. ü If there is a huge difference between R-square and Adjusted R-square then we can assume that some unimportant independent variables are present in the data set. ü If inclusion of a variable reduces Adjusted R-square it will be identified as a nonsense parameter for the model.
Estimating coefficients. Ø Go to “Statistics” tab and select “Multiple Regression”. Ø Select the variables and click ok again click ok. Ø Now click “Summary regression results”.
Ø Left side table showing the model accuracy. Ø R-square- Describing the amount of variability that has been explained by indep: variables, here it is approx. 93%. Ø Adjusted R-square – Give an indication whethere is any insignificant factor or not. Ø Adj: R square should be close to Multiple R square, if it is very smaller than R square then we should go for stepwise regression. (Adjusted R square always < or = Multiple R square. )
Interpretation of Result. Ø Here R square and Adjusted R square very close to each other, which indicate a good model. Ø In regression analysis R square value will always increase with the inclusion of parameters , but Adjusted R square may not be, this indicate the presence of nuisance parameters in the model. Ø The p value for F test is significant (left table) indicate, there is at least one variable which has significant contribution to the model. Ø The p values for t-test are all significant (as p<. 05)(2 nd table) which indicate all these variables has significant effect on the response.
Multicollinearity. Ø Definition Multicollinearity refers to excessive correlation of the independent variables. Ø Ideally independent variable should be uncorrelated to each other (according to the assumption). Ø If the correlation is excessive (some use the rule of thumb of r >0. 90), standard errors of the beta coefficients become large, making it difficult or impossible to assess the relative importance of the predictor variables. Ø But multicollinearity does not violate OLS assumption, it still gives unbiased estimate of the coefficient.
Detecting Multicollinearity Ø Tolerance The regression of any independent variable on all the other independents, ignoring the dependent. As a rule of thumb, if Tolerance ≤ 0. 10, a problem with multicollinearity is indicated. Ø VIF (Variance-inflation factor) Is simply the reciprocal of tolerance. As a rule thumb, if VIF > 10 , a problem with multicollinearity is indicated. Ø C. I (condition indices) Another index for checking multicollinearity. As rule thumb , if C. I >30 serious multicollinearity is present in the data set.
v Some other indication of multicollinearity. Ø If none of the t-test for the individual coefficients is statistically significant, yet the overall F statistic is. It imply the fact that some coefficients are insignificant because of multicollinearity. Ø Check to see how stable coefficients are when different samples are used. For example, you might randomly divide your sample in two parts. If coefficients differ dramatically, multicollinearity may be a problem. Ø Correlation matrix can also be used to find out which independent variables are highly correlated (affected by multicollinearity)
How to perform in Statistica? Ø In the “Advanced” tab click on either “Partial correlation” or “Redundancy” tab. Ø You will get the result which contain Tolerance, Partial correlation, Semi partial correlation etc. Ø From the table it is clear that Tolerance > 0. 10 , so Multicollinearity is not a threat for this data set.
Example of VIF Ø The data set contains information about the physical and chemical properties of some molecules. Ø Dependent variablelog. P. Ø 24 numbers of indep: variables. Ø We will first find out VIF values and also check the correlation matrix.
Steps. Ø Go to Statistics tab select “Advanced linear non-linear model” and click “General linear model” , select “Multiple regression”. Ø Select variables and click ok, again click ok. Ø Click on “Matrix” tab , then select “Partial correlation”. Ø The circled variables are highly affected by multicollinearity (as VIF>10). Ø Now we can create correlation matrix to see which variables are correlated to each other.
Correlation matrix. Ø Go to Statistics tab, select “Basic statistics/Tables” then select “Correlation matrices”. Ø Click on “Two lists” and select variables. Ø Click ok and then click “ Summary correlation”.
Ø The Correlation Matrix will be obtained. Ø It is clear that large number of variables are highly correlated to each other and they are colored as red, like BO 1 -X and DN 3 etc.
Methods for Dealing with Multicollinearity. Ø a. b. c. Several techniques have been proposed for dealing with the problems of multicollinearity, these are Collecting additional data: The additional data should be collected in a manner designed to break up the multicollinearity in the existing data set. But this method is not always suitable for economic constraints or for sampling problem. Variable elimination : If any two or three variables are highly linearly dependent, eliminating one regressor may be helpful to reduce multicollinearity. This also may not provide satisfactory result, since the eliminating variable may have significant contribution to the predicting power. Stepwise regression: Most effective method for eliminating multicollinearity. This method will exclude those variables which has affected by co linearity step by step and try to maximize the model accuracy.
Stepwise Regression. Ø Stepwise multiple regression, also called statistical regression, is a way of computing OLS regression in stages. Ø First Step The independent best correlated with the dependent is included in the equation. Ø Second Step The remaining independent with the highest partial correlation with the dependent, controlling for the first independent, is entered. Ø This process is repeated, at each stage partialling for previously-entered independents, until the addition of a remaining independent does not increase R-squared by a significant amount (or until all variables are entered, of course). Ø Alternatively, the process can work backward, starting with all variables and eliminating independents one at a time until the elimination of one makes a significant difference in Rsquared.
Example of stepwise Regression. Ø Go to “Statistics” tab and select “Multiple Regression”. Ø Select variables , click ok. Ø Then click on “Advanced” tab and select the circled options. Ø Click ok. Ø Select the circled option. (2 nd figure)
Ø Click on “stepwise” tab and select the circled option. Ø Next click ok. Ø You will get the 2 nd window. Ø Now you have to click the tab “Next” until all important variables are included into the model. Ø Next click on “summary regression result” to get the model summary.
Residual Analysis. Ø Residuals are the difference between the observed values and those predicted by the regression equation. Residuals thus represent error, in most statistical procedures. Ø Residual Analysis is the most important part in Multiple regression for diagnostic checking of model assumptions. Ø Residual analysis is used for three main purposes: (1) to spot heteroscedasticity (ex. , increasing error as the observed Y value increases), (2) to spot outliers (influential cases), and (3) to identify other patterns of error (ex. , error associated with certain ranges of X variables).
Assumptions of Errors. Ø The following assumptions on the random errors are equivalent to the assumptions on the response variables, which are tested via Residual Analysis. (i) The random errors are independent. (ii) The random errors are normally distributed. (iii) The random errors have constant variance.
Assumption 3: The Errors are Uncorrelated to each other. (detection of Autocorrelation). Ø Some application of regression involve regressor and response variables that have a natural sequential order over time. Such data are called Time series data. Ø A characteristic of such data can be that neighboring observations tend to be somewhat alike. This tendency is called Autocorrelation. Ø Autocorrelation can also be arise in laboratory experiments , because of the sequence in which experimental runs are done or drift in instruments calibration. Ø Randomization reduce the possibility of Auto correlated result. Ø Parameter estimate may or may not be seriously affected by Autocorrelation , but autocorrelation will bias the estimation of variance, and any statistics estimated from variance like confidence intervals will be wrong.
Ø How to detect Autocorrelation? § Various statistical tests are available for detecting Auto correlation, among them Durbin-Watson test is widely used method. § It is denoted by “D”. If the D value lies between (1. 75 , 2. 25) residuals are uncorrelated. If D <1. 75 residuals are correlated, positively and If D>2. 25 residuals are correlated, negatively.
Ø Go to “Statistics” tab and select “Multiple regression”, select variables and click ok again click ok. Ø The 1 st window will come , click ok , you will get the 2 nd window. Ø Click on “Advanced” tab and then click on “Durbin-Watson statistic”.
Ø The first column of the spreadsheet shows the D statistic value which > 2. 25. Ø According to rule residuals are negatively correlated. Ø Second column shows the correlation value. Ø Here residuals are correlated but the magnitude is not so high, (<. 50) so we can take this into consideration. v Analysis done from 1 st dataset. (chemical process data).
Constant variance of residuals. Ø In linear regression analysis, one assumption of the fitted model is that the standard deviations of the error terms are constant and do not depend on the x-value. Ø Consequently, each probability distribution for y (response variable) has the same standard deviation regardless of the x-value (predictor). Ø This assumption is homoskedasticity. v How to check this assumption? ü One simple method is to plot the residual values against the fitted (predicted). ü If this plot shows a systematic pattern then it is fine. ü If it shows abnormal or curvature pattern there should be problem.
How to manage abnormal condition? ü If the graph shows abnormality , some techniques are there to manage such condition. Ø The usual approach to deal with inequality of variance is to apply suitable transformation to either independent variables or response variable. (Generally transformation of the response are employed stabilize variance). Ø We can also use method of weighted least square instead of ordinary least square. Ø A curved plot may indicate nonlinearity, this could mean that other regressor variables are needed in the model, for example a squared term may be necessary. Ø A plot of residual against predicted may also reveal one or more unusually large residuals these points are of course potential outlier. we can exclude those points from analysis.
Ø Go to statistics tab and select “Multiple regression”. Ø Select variables and click ok again click ok. Ø You will get the 1 st window, click on “Residuals/assumptions/pr ediction” tab and then click on “perform residual analysis”. Ø You will get the 2 nd window, click on “scatter plot” tab and click on “predicted v/s residuals”.
Ø The above graph showing the predicted v/s residuals scatter plot. Ø It is clear that few of points after midpoints are going upward an downward, which means at that points there are some tendency of higher residuals positively or negatively. Ø In other word that affected points are not predicted properly.
Normality of Residuals. Ø In regression analysis last assumption is normality of Ø Ø Ø residuals. Small departure from normality assumption do not affect the model greatly, but gross non normality is potentially more serious as the t or F test, and confidence intervals depends on normality assumption. A very simple method of checking the normality assumption is to construct “Normal probability plot” of the residuals. Small sample size (n<=16) often produce normal plot that substantially deviate from linearity. For large sample size (n>=32) the plots are much well behaved. Usually at least 20 points or observation are required to get stable normal probability plot.
Normal probability plot. Ø From Multiple regression go to residuals tab and select “perform residual analysis”. Ø Then click on “probability plot” and select “Normal plot of residuals”.
Ø The normal plot shows almost good fitting of normality. Ø Small amount of deviations are there from the linearity , that could be overcome probably if we add some new experimental points to the data set. (current data contains only 16 observations). v Analysis done from 1 st dataset (chemical process data).
Detecting outlier. Ø If any data include some extreme values (outlier) then it may causes serious problem while checking the assumptions of regression analysis. Ø Few classical techniques are there for detecting outliers, like Box-Whiskers plot. Ø Here we use some residual techniques for detecting outliers after creating the regression model. Ø One popular method is to check “Standard residual values”. Ø If any value goes beyond ( -3. 5 to 3. 5), that particular point will be considered as an outlier.
Ø From Multiple regression , select variables click ok again click ok. Ø 1 st window will appear, select “Residual/assumption/pr ediction” then click “Perform residual analysis”. Ø 2 nd window will appear select “Outliers” and then activate “standard residuals” and click on “case wise plot of outliers”.
Ø The above output will come. Ø Here just check the 5 th column (highlighted) , in this case all points are within (-3 to +3). Ø So no possible outliers are there. Ø In the extreme left the case points have demonstrated.
Thank you Krishnendu Kundu Statsoft. India. Email- kkundu@statsoftindia. com Mobile - +919873119520.