Correlation and Regression Correlation and Regression Used when















 Arm Span (cm) 171 173 195 193 180 188 182 185")







 of 13 adult male tuataras and the size")







 is fixed and measured")

















 Source of Variation Sum of Squares Regression SSR")






, while accounting for variability")



- Slides: 63
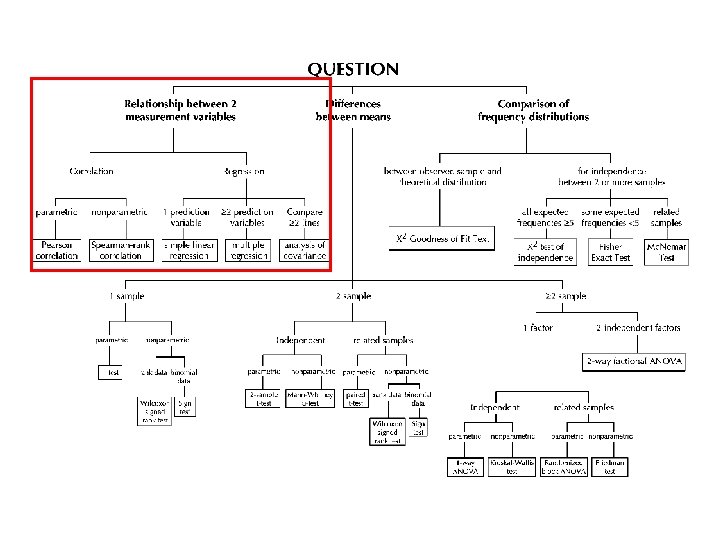
Correlation and Regression
Correlation and Regression • Used when we are interested in the relationship between two variables. • NOT the differences between means or medians of different groups.
Correlation and Regression • Used when we are interested in the relationship between two variables. • NOT the differences between means or medians of different groups. The reverse is also true… so in your paper, you should not have written: “There was a correlation between number of pupae and presence of an interspecific competitor. ” Rather, the correct way would be: “There was a difference between the mean number of pupae produced between treatments with and without an interspecific competitor. ”
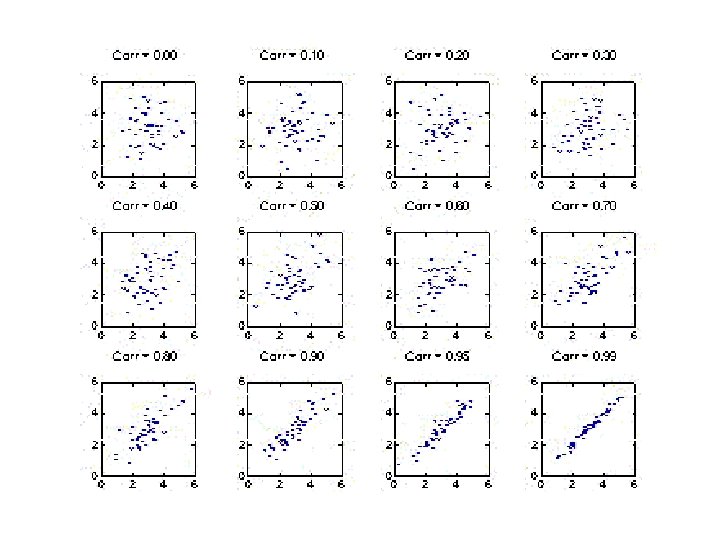
Correlation • This is used to: - describe the strength of a relationship between two variables…. This is the “r value” and it can vary from -1. 0 to 1. 0
Correlation • This is used to: - describe the strength of a relationship between two variables…. This is the “r value” and it can vary from -1. 0 to 1. 0 - determine the probability that two UNRELATED variables would produce a relationship this strong, just by chance. This is the “p value”.
IF N = 62, then rcrit = 0. 250 for p = 0. 05, rcrit = 0. 325 for p = 0. 01
Correlation • Important Note: – Correlation does not imply causation - the variables are related, but one does not cause the second.
“spurious” correlation
Correlation • Important Note: – Correlation does not imply causation - the variables are related, but one does not cause the second. – Often, the variables are both dependent variables in the experiment… such as mean mass of flies and number of offspring. - so it is incorrect to think of one variable as ‘causing’ the other…. As number increases, amount of food per individual declines, and flies grow to a smaller size. Or, as flies grow, small ones need less and so more small ones can survive together than large ones.
Correlation • Parametric test - the Pearson Correlation coefficient. – If the data is normally distributed, then you can use a parametric test to determine the correlation coefficient - the Pearson correlation coefficient.
negative NOTE: no lines drawn through points!
Pearson’s Correlation • Assumptions of the Test – Random sample from the populations – Both variables are approximately normally distributed – Measurement of both variables is on an interval or ratio scale – The relationship between the 2 variables, if it exists, is linear. • Thus, before doing any correlation, plot the relationship to see if its linear!
Pearson’s Correlation • How to calculate the Pearson’s correlation coefficient n = sample size
Testing r • • Calculate t using above formula Compare to tabled t-value with n-2 df Reject null if calculated value > table value But SPSS will do all this for you, so you don’t need to!
Example • The heights and arm spans of 10 adult males were measured in cm. Is there a correlation between these two measurements?
Example Height (cm) Arm Span (cm) 171 173 195 193 180 188 182 185 190 186 175 178 177 182 178 182 198 202
Step 1 – plot the data
Example • Step 2 – Calculate the correlation coefficient - r = 0. 932 • Step 3 – Test the significance of the relationship - p = 0. 0001
Nonparametric correlation • Spearman’s test • This is the most commonly used test when one of the assumptions of the parametric test cannot be met usually because it is non-normal, non-linear, or uses ordinal data. • The only assumptions of the Spearman’s r test is that the data is randomly collected and that the scale of measurement is at least ordinal.
Spearman’s test • Like most non-parametric tests, the data are first ranked from smallest to largest – in this case, each column is ranked independently of the other. • Then (1) subtract each rank from the other, (2) square the difference, (3) sum the values, and (4) plug into the following formula to calculate the Spearman correlation coefficient.
Spearman’s test • Calculating Spearman’s correlation coefficient
Testing r • The null hypothesis for a Spearman’s correlation test is also that: – = 0; i. e. , H 0: = 0; HA: ≠ 0 • When we reject the null hypothesis we can accept the alternative hypothesis that there is a correlation, or relationship, between the two variables.
Testing r • • Calculate t using above formula Compare to tabled t-value with n-2 df Reject null if calculated value > table value But SPSS will do all this for you, so you don’t need to!
Example • The mass (in grams) of 13 adult male tuataras and the size of their territories (in square meters) was measured. Are territory size and the size of the adult male tuatara related?
Example Observation number Mass Territory size 1 510 6. 9 2 773 20. 6 3 840 17. 2 4 505 6. 7 5 765 20 6 780 24. 1 7 235 1. 5 8 790 13. 8 9 440 1. 7 10 435 2. 1 11 815 20. 2 12 460 3. 0 13 697 10. 3
Step 1 – plot the data Note - not very linear
number Mass m. RANK Territory t. RANK d d 2 1 510 6 6. 9 6 0 0 2 773 10 20. 6 12 2 4 3 840 13 17. 2 9 4 16 4 505 5 6. 7 5 0 0 5 765 8 20 11 3 9 6 780 9 24. 1 13 4 16 7 235 1 1. 5 1 0 0 8 790 11 13. 8 8 3 9 9 440 3 1. 7 2 1 1 10 435 2 2. 1 3 1 1 11 815 12 20. 2 10 2 4 12 460 4 3. 0 4 0 0 13 697 7 10. 3 7 0 0 = rs = 1 - 6(60) 13(168) = 0. 835
Example • Step 2 – Calculate the correlation coefficient • Step 3 – Test the significance of the relationship = 0. 835, p = 0. 001 = 5. 03
Linear Regression • Here we are testing a causal relationship between the two variables. • We are hypothesizing a functional relationship between the two variables that allows us to predict a value of the dependent variable, y, corresponding to a given value of the independent variable, x.
Regression • Unlike correlation, regression does imply causality • An independent and a dependent variable can be identified in this situation. – This is most often seen in experiments, where you experimentally assign the independent variable, and measure the response as the dependent variable. • Thus, the independent variable is not normally distributed (indeed, it has no variance associated with it!) - as it is usually selected by the investigator.
Linear Regression • For a linear regression, this can be written as: – – y = + x (or y = mx + b) where y = population mean value of y at any value of x = the population (y) intercept, and = population slope. • You can use this equation to make predictions although of course these are usually estimated by sample statistics rather than population parameters.
Linear Regression • Assumptions – 1. The independent variable (X) is fixed and measured without error – no variance. – 2. For any value of the independent variable (X), the dependent variable (Y) is normally distributed, and the population mean of these values of y, y is: • y = + x
Linear Regression • Assumptions – 3. For any value of x, any particular value of y is: • yi = + x + e • Where e, the residual, is the amount by which any observed value of y differs from the mean value of y (analogous to “random error”) • Residuals will follow a standard normal distribution
Linear Regression • Assumptions – 4. The variances of the y variable for all values of x are equal – 5. Observations are independent – each individual is measured only once.
OK Y X
Not OK Y X
Estimating the Regression Function and Line • A regression line always passes through the point: “mean x, mean y”.
Example - Juniper pythons measured single, randomly selected snakes at different temperatures (one snake per temp). Temperature (˚C) Heart Rate 2 5 4 11 6 11 8 14 10 22 12 23 14 32 16 29 18 32 Mean (x) = 10 Mean (y) = 19. 88
Example
Example Mean x = 10; Mean y = 19. 88 How much each value of y (yi) deviates from the mean of y… y – yi • The horizontal line represents a regression line for y when x (temperature) is not considered. • Residuals are very large!
Estimating the Regression Function and Line • To measure total error, you want to sum the residuals… but they will cancel out… so you must square the differences, then sum. • Now we have the TOTAL SUM OF SQUARES (SST) • The sum of squares of the residuals is thus: T • Thus, you see a lot of variance in y when x is not taken into account. How much of the variance in y can be attributed to the relationship with x?
Example Mean x = 10; Mean y = 19. 88 The “line of best fit” minimizes the residual sum of squares. The best fit line represents a regression line for y when x (temperature) is considered. Now the residuals are very small – in fact, the smallest sum possible.
Estimating the Regression Function and Line • This “line of best fit” minimizes the y sum of squares, and accounts for how x, the independent variable, influences y, the dependent variable. • The difference between the observed values and this “line of best fit” are the residuals – the “error” left over when the relationship is included.
Estimating the Regression Function and Line • The sum of squares of these regression residuals is now: • This is equivalent to the ERROR SS = (SSe); it is the variance “left over” after the realtionship with x has been included.
Estimating the Regression Function and Line • How do we get this best fit line? • Based on the principles we just went over, you can calculate the slope and the intercept of the best fit line.
Estimating the Regression Function and Line
Testing the Significance of the Regression Line • In a regression, you test the null hypothesis – Hq: = 0; HA: ≠ 0 • This is done using an ANOVA procedure. • To do this, you calculate sums of squares, their corresponding degrees of freedom, mean squares, and finally an F value (just like an ANOVA!)
Sums of Squares • SSt - this is the value for sums of squares for y when x is not considered (the total sums of squares) • SSe - this is the value for the sums of squares of the residuals - in other words, it represents the variance in y that is still present even when x is considered (the error sums of squares) • SSr – this is the variation in y accounted for by the relationship with x. It can be calculated two ways: - by subtraction (SSt – SSe) - directly using formula
Sums of Squares
Regression ANOVA Table (see p. 120) Source of Variation Sum of Squares Regression SSR df 1 MS SSR Error SSE n-2 SSE/n-2 Total SST n-1 SST/n-1 F MSR/MSE
Testing the Significance of the Regression Line • Interpret exactly as for an ANOVA
Coefficient of determination • The coefficient of determination, or r 2, tells you what proportion of the variance in y is explained by its dependence on x. • r 2 = SSR/SST • e. g. , if r 2 = 0. 98, then 98% of the variance in y is dependent on x - or 2% of the variance is unexplained.
Example • Suppose you want to describe the effects of temperature on development time in Drosophila. • You let flies lay eggs (on mushrooms in 30 vials) for one day • You select 3 temperature treatments (20, 25, 30 o. C) and randomly assign 10 vials to each treatment. • You count the number of flies that emerge each day. From these data, you compute two variables, number of flies and mean number of days to develop. • Number of flies is not a dependent variable, because this did not vary as a consequence of temperature – eggs were laid before vials were placed in the temperature treatments. But, you know that the number of flies – and competitive stress – might cause a change in developmental rate. So, it is a potential correlate.
OUTPUT – Linear Regression
OUTPUT: Multiple Regression – Abundance and Temp
Multiple regression – Stepwise Source SS df Total Abundance Temp Regression Residual 274. 855 152. 535 95. 048 247. 855 27. 271 29 1 1 2 27 MS F P
ANCOVA: Comparing means between treatments (NOT looking for linear relationship), while accounting for variability due to correlated variables. ANOVA ALONE:
ANCOVA: Comparing means between treatments, while accounting for variability due to correlated variables. ANCOVA: Analysis of Covariance
Diffs in PUT mean male mass between treat 1 vs. 3
Diffs in PUT mean male mass between treat 1 vs. 3