Corestateless Fair Queueing Egy sklzhat architectra fair svszlessg












 és méretben is változatlan")
: Kiszolgálás fifo sorrendben Bufferelés egyszerű drop-tail módszerrel RED (Random")



: • 1 TCP folyam + 1.")





- Slides: 24
Core-stateless Fair Queueing Egy skálázható architectúra fair sávszélesség elosztás közelítésére nagysebességű hálózatokon
Bevezetés Hálózati torlódás okai lehetnek: hosztoktól nagy forgalom érkezik, a csomópontok képtelenek megbirkózni vele. várakozó sor alakul ki egy ponton, kevés a memória az összes beérkező üzenet befogadásához lassú processzor, adminisztratív feladatok lassú elvégzése miatt nem kerülnek be az egyébként üresen várakozó memóriába. kis vonalkapacitás Következmény: Torlódás alakul ki, majd csomagvesztés, idővel a teljes hálózat összeomlik. A torlódás globális jelenség, vagyis a hálózat egészére vonatkozó módszert kell találni az átbocsátóképesség növelésének érdekében.
Bevezetés Az fair sávszélesség kiosztásnak több előnye is van: Megvédik a jól viselkedő folyamokat a hibásaktól Lehetővé teszi több különböző torlódáskezelő eljárás együttes használatát Mostanáig a fair kiosztásra: Fair queueing - folyamonkénti ütemezéses módszer Flow Random Early Drop (FRED) - folyamonkénti eldobásos módszer Tulajdonságaik: Állapotkezelés (folyamonkénti) Buffer kezelés És/vagy folyamonkénti csomag ütemezés Ezek miatt komplexek, nem implementálhatóak költséghatékonyan Tegyük fel: 1) A fair kiosztásos módszer fontos szerepet töltenek be a torlódáskezelésben 2) A komplexitásuk a legnagyobb akadály az alkalmazhatósgukhoz.
Core-stateless fair queueing ‘edge’ : folyamonkénti állapot tárolás. Megbecsülik a beérkező folyamok rangját és ez alapján cimkét helyeznek el a csomag header-jébe. ‘core’ : nem tárolnak folyamonkénti állapotot. FIFO ütemezés. A cimkék és a router összesített forgalmi becslése alapján valószínűsített eldobási algoritmussal működnek. Egy ilyen felépítést hívunk „Core-stateless fair queueing”-nak amire igaz: Jelentősen csökkenti az implementálási komplexitást Még mindig korrekt sávszélesség kiosztást biztosít
Algoritmusok A – Fluid model Vegyük a folyamot most egy összefüggő bitfolyamnak. Nincs bufferelés. Legyenek: C – kimenő link sebesség t - idő ri(t) – érkezési sebesség (minden folyamra pontosan ismertnek tekintjük) α(t) – minden folyamra azonos kimenő sebesség (fair elosztási sebesség) a max-min elosztási módszer alapján minden folyam min(ri(t), α(t)) sebességet kap. A(t) = összes beérkezési sebesség. Ha A(t) > C akkor α(t) egyedi megoldása az egyenletnek itt ha akkor minden továbbítva lesz, egyébként csak α(t). Ha A(t) <= C akkor nem dobunk el semmit és Ez egyszerű valószínűségi továbbító algoritmus lesz ami fair elosztást ér el. Minden bejövő folyam eséllyel lesz eldobva.
Algoritmusok B - packet A következő feladat hogy az előző algoritmust kiterjesszük olyanná ami közelebb áll a valósághoz: Csomagokban vannak az adatok Van bufferelés A beérkező sebességet nem ismerjük előre Még mindig a beérkezéskor eldobó sémát alkalmazunk annyi különbséggel, hogy most csomagokkal tesszük. Mivel a sebesség becslés magában foglalja a csomag méretet, az eldobási valószínűség nem függ tőle, csak a bejövő és a fair elosztási sebességtől. Ezt a kettőt még ki kell számolni
Beérkezési sebesség becslése Az edge routereken egy folyam sebességének becslésére exponenciális mozgóátlag számítást használunk. az i folyam k-adik csomagjának érkezési ideje az i folyam k-adik csomagjának hossza Minden i folyam sebességére a becslés képlete: Ahol és K egy konstans
Fair elosztási sebesség becslése A sebesség amivel az algoritmus elfogadja a csomagokat [ elosztási sebesség jelenlegi becslésének függvénye [ ]. Ez a függvény függ attól, hogy a link túlterhelt-e: Ha A(t) >C – torlódás - akkor az megoldása Ha A(t)<= C - nincs torlódás - akkor ] a fair
Fair elosztási sebesség becslése Ha ismerjük a beérkező sebességeket, Ki tudnánk számolni közvetlenül a képletből is, de hogy elkerüljük az állapot tárolást, csak aggregált adatokra támaszkodva számítunk. Legyenek: - a becsült fair elosztási sebesség - a becsült összesített beérkező sebesség - a becsült elfogadott sebesség T - csomagérkezési időköz Az utóbbi kettőt minden csomag beérkezésekor frissítjük exponenciális átlag számítással Hogy kiszűrjük a kerekítésből származó becslési pontatlanságokat, az időt Kc időintervallumokra osztjuk és -t csak ezek végén frissítjük a link terheltségétől függően
Buffer kezelés A fair elosztási sebesség becslésének célja az elfogadott sebesség és a sávszélesség közelítése, mi van ha ez a sebesség eléri a sávszélességet? Okok: becslési pontatlanságok Az frissítések közötti töltési különbségek az algoritmus valószínűségi természete Normál esetben a buffer el tudja tárolni a csomagokat, de néha el kell dobni őket. Mivel a drop-tail ellenkezik az algoritmus céljaival és néha beszámíthatatlan tulajdonságai vannak, így ennek a hatásait limitálni kell. Bevezetünk egyszerű heurisztikát: Minden buffer túlcsordulásnál leveszünk egy kis (előre fixen meghatározott) százalékot az ból. Nem többet mint 25%, hogy elkerüljük a túlkorrigálást. Feltesszük, hogy a link ami ‘nem zsúfolttá’ válik az ellenőrzéskor, a buffer egy előre meghatározott határértékéig az is marad.
Címke újraírás A cimkékben lévő becsült sebesség pontatlanná válhat (például mert a csomag belefutott egy túlterhelt linkbe a szigeten belül) minden routeren finomítani kell
Súlyozott CSFQ Az algoritmus kiterjeszthető úgy, hogy folyamonként súlyozható legyen. Legyen az i folyam súlya. Ekkor ha A(t) > C az Az eldobási valószínűség pedig így módosul A folyékony modellben ez azt jelenti, hogy a értéke ugyanaz lesz minden folyamra. A cimkékbe pedig kerül a sima r i(t) helyett. Fontos, hogy csak olyan szigeteket tudunk kezelni az algoritmusunkkal melyeken belül egy folyamnak minden routeren ugyanaz a súlya, de még ezzel a megkötéssel is értékes módszer.
Implementálási komplexitás Core routereken: időben (figyelembe véve a folyamok számát) és méretben is változatlan komplexitású. Edge routereken: Besorolás egy folyamba Frissíteni a fair elosztási sebesség becslését Újrabecsülni a folyam sebességét Megcimkézni a csomagot bár ezeket minden csomagra meg kell csinálnia, a besorolás kivételével mind könnyen implementálhatóak ma már. A besorolás algoritmusai viszont ma is aktív kutatás alatt állnak, de ha az edge routerek nem nagy sebességű gerinc linkeken vannak akkor nem okoznak akkora gondot.
Szimulációk FIFO(First In First Out): Kiszolgálás fifo sorrendben Bufferelés egyszerű drop-tail módszerrel RED (Random Early Detection): Kiszolgálás Fifo sorrendben Bufferelés valószínűségi eldobás két határértékkel. (Első alatt nem dob semmit, a második felett mindent, a kettő közt a telitettséggel lineárisan nő az eldobás esélye. ) FRED (Fair Random Early Drop): Kiszolgálás: fair queueing Állapot tárolás minden folyamhoz aminek legalább egy csomagja van a bufferben Bufferelés: az eldobás nem csak a buffer telitettségétől függ, hanem az állapottól is Eldobáskor preferálja azokat amiknek: 1. 2. Sok csomagja lett eldobva eddig A sora hosszabb mint az átlagos Két verziója van (FRED-1, FRED-2), a különbség csak annyi, hogy a második mindig biztosít egy minimális mennyiségű helyet minden folyamnak a bufferben. Mindig azt vesszük amelyik épp jobb. DRR (Deficit Round Robin): Kiszolgálás: fair queueing Bufferelés: mikor a buffer tele a leghosszabb sorból dob el csomagot A Weighted Fair Queueing (WFQ) egy hatékony implementálása
Paraméterek Minden kimenő link késleltetési ideje: 1 ms Buffer: 64 KB CSFQ buffer határ: 16 KB RED, FRED első határ: 16 KB RED, FRED második határ: 32 KB Folyam sebesség becsléshez konstans: K = 100 ms Fair elosztási sebesség becsléshez konstans: K = 200 ms Az első router az útvonalon edge, az összes többi core.
Egy torlódott link Teszt 1: 32 CBR folyam ahol minden i folyam (i + 1)es adatmennyiséget küld. 10 mp időintervallum. Eredmény: FIFO, RED, FRED-1: nem ért el fair elosztást DRR: kiemelkedően hatékony CSFQ, FRED-2: nem tökéletes, de eléggé fair elosztást ért el
Egy torlódott link Teszt 2: • 1 CBR folyam ami 10 Mbps el küld + 30 TCP folyam. • 10 mp időintervallum. Eredmény: • Csak a DRR és a CSFQ volt képes hatékonyan beépíteni a CBR folyamot. • FRED: a CBR közel 6 x annyit sávszélességet (1, 8 Mbps) kapott mint ami fair • FIFI, RED: rossz teljesítmény közel 8 Mbps-t adott a CBR-nek
Egy torlódott link Teszt 3 (30 darab teszt): • 1 TCP folyam + 1. . 30 CBR folyam. Minden CBR a fair kétszeresével küld. • 10 mp időintervallum. Eredmény: • A DRR 22 CBR-ig jó, utána folyamatosan romló teljesítményt ad. • A CSFQ jobban teljesít mint a DRR ha sok a folyam. • A CSFQ végig hasonló vagy jobb teljesítményt ad mint a FRED.
Több torlódott link • CBR 0 kivételével az összes CBR 2 Mbps –el küld így az összes link torlódik. • Majd megpróbálunk az így torlódott routereken átküldeni 1 -1 CBR illetve TCP folyamot amik a saját fair elosztási sebességükön (0. 909 Mbps) adnak.
Több torlódott link Teszt 1: • 1 CBR folyam. Eredmény: • CSFQ, FRED elég jól teljesít de elmaradnak a DRR-től • FIFO, RED minél több torlódott linken megy át annál rosszabb.
Több torlódott link Teszt 2: • 1 TCP folyam. Eredmény: • CSFQ, DRR: elég hatékonynak bizonyulnak. • FRED: jelentősen rosszabb náluk de még mindig jobb mint FIFO, RED • Folyamok különböző end-to-end torlódás kezelő algoritmusokkal mindig különböző átviteli sebességet érnek el, még ha a
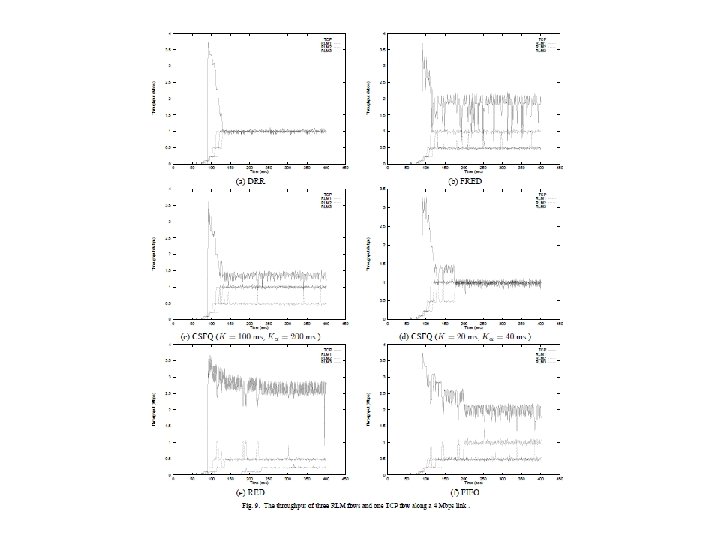
Egyéb tesztek ON-OFF folyamok: DRR, CSFQ, FRED megint jól elosztotta a sávszélességet. TCP folyamok - 0. 1 ms késleltetési idő ( web forgalomhoz hasonló) átlagos idő és eltérés RLM (Receiver-driven Layered Multicast) folyamok
Kiértékelés Ø A legtöbb feltétel mellett elfogadható fair sávszélesség elosztás közelítést ér el. Ø A jelenleg leginkább használt (FIFO, RED) módszereket messze felülmúlja. Ø Sőt minden helyzetben a FRED-hez hasonló eredményt ér el, miközben jelentősen fairebben osztja a sávszélességet. Ø Még bőven fejleszthető és javítható (pl: a bufferkezelőalgoritmusa, szeretnék közelíteni a RED eljáráséhoz)