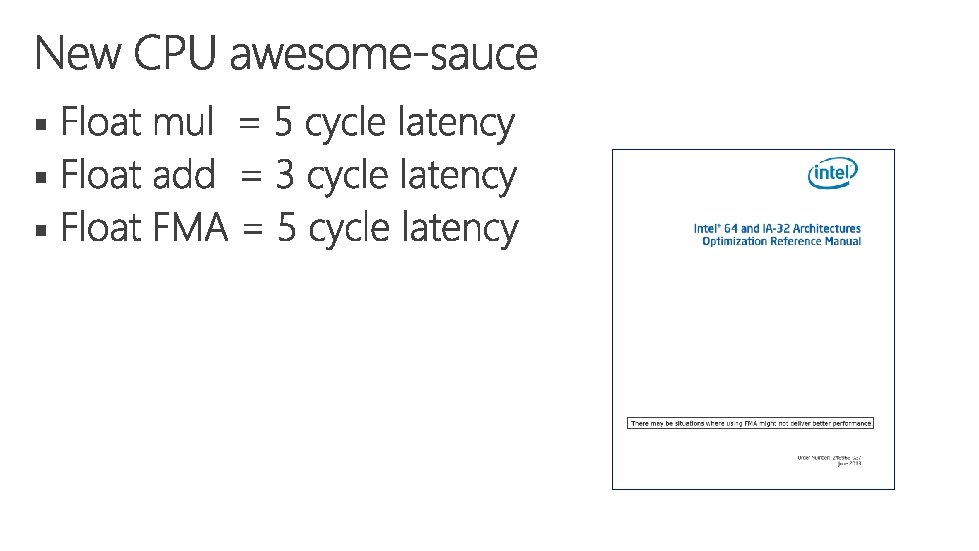
Cool one Fused multiply accumulate FMA Using FMA


 Using FMA everywhere hurts performance")
![//. . . stuff. . . x[0] = y[0]; // 128 b copy x[1]](https://slidetodoc.com/presentation_image_h/07a2c10fb64e8cd96c25b0aad3375f16/image-4.jpg "//. . . stuff. . . x[0] = y[0]; // 128 b copy x[1]")


 AMD Athlon XP (2001) Intel Pentium 4 (2001) AMD Athlon")








![Mult = 5 cycles Add = 3 cycles FMA = 5 cycles A[5] B[5]](https://slidetodoc.com/presentation_image_h/07a2c10fb64e8cd96c25b0aad3375f16/image-19.jpg "Mult = 5 cycles Add = 3 cycles FMA = 5 cycles A[5] B[5]")



![§ for (i=0; i<1000; i++) A[i] = B[i] + C[i]; autovec for (i=0; i<1000;](https://slidetodoc.com/presentation_image_h/07a2c10fb64e8cd96c25b0aad3375f16/image-23.jpg "§ for (i=0; i<1000; i++) A[i] = B[i] + C[i]; autovec for (i=0; i<1000;")









 { for (int i = 0; i<10000; i++) func 2(); }")


 AMD Athlon XP (2001) Intel Pentium 4 (2001) AMD Athlon")






- Slides: 44
Cool one: Fused multiply accumulate (FMA) Using FMA everywhere hurts performance
//. . . stuff. . . x[0] = y[0]; // 128 b copy x[1] = y[1]; // 128 b copy //. . . stuff. . . “optimized” //. . . stuff. . . x = y; // 256 b copy //. . . stuff. . . This may cause huge slowdowns on some chips
What?
Intel Pentium 3 (1999) AMD Athlon XP (2001) Intel Pentium 4 (2001) AMD Athlon 64 (2003) Intel Sandy Bridge (2011) AMD Bulldozer (2011) Intel Haswell (2013) Future AMD Chip (? ) Some 128 bit SIMD instructions FP 256 bit SIMD instructions /arch: SSE 2 /arch: AVX 2 Visual C++ ? Visual Studio. NET 2003 Visual Studio 2010 Visual Studio 2013 Update 2 (optimization support) New hotness!
1. 2.
#1
§ _mm_fmadd_ss, _mm_fmsub_ss, _mm_fnmadd_ss, _mm_fnmsub_ss, _mm_fmadd_sd, _mm_fmsub_sd, _mm_fnmadd_sd, _mm_fnmsub_sd, _mm_fmadd_ps, _mm_fmsub_ps, _mm_fnmadd_ps, _mm_fnmsub_ps, _mm_fmadd_pd, _mm_fmsub_pd, _mm_fnmadd_pd, _mm_fnmsub_pd, _mm 256_fmadd_ps, _mm 256_fmsub_ps, _mm 256_fnmadd_ps, _mm 256_fnmsub_ps, _mm 256_fmadd_pd, _mm 256_fmsub_pd, _mm 256_fnmadd_pd, _mm 256_fnmsub_pd /arch: AVX 2
Mult = 5 cycles Add = 3 cycles FMA = 5 cycles A B C 5 cycles C 3 cycles res
Mult = 5 cycles Add = 3 cycles FMA = 5 cycles A B C C D 5 cycles A B 3 cycles res D 5 cycles res
Mult = 5 cycles Add = 3 cycles FMA = 5 cycles A[5] B[5] A[6] B[6] dp A[5] B[5] t 1 A[6] B[6] 5 cycles 3 cycles . . . 5 cycles . . . t 2
#2
Highly optimized CPU code isn’t CPU code.
§ for (i=0; i<1000; i++) A[i] = B[i] + C[i]; autovec for (i=0; i<1000; i+=4) xmm 1 = vmovups B[i] xmm 2 = vaddps xmm 1, C[i] A[i] = vmovups xmm 2 § for (i=0; i<1000; i++) A[i] = B[i] + C[i]; autovec for (i=0; i<1000; i+=8) ymm 1 = vmovups B[i] ymm 2 = vaddps ymm 1, C[i] A[i] = vmovups ymm 2
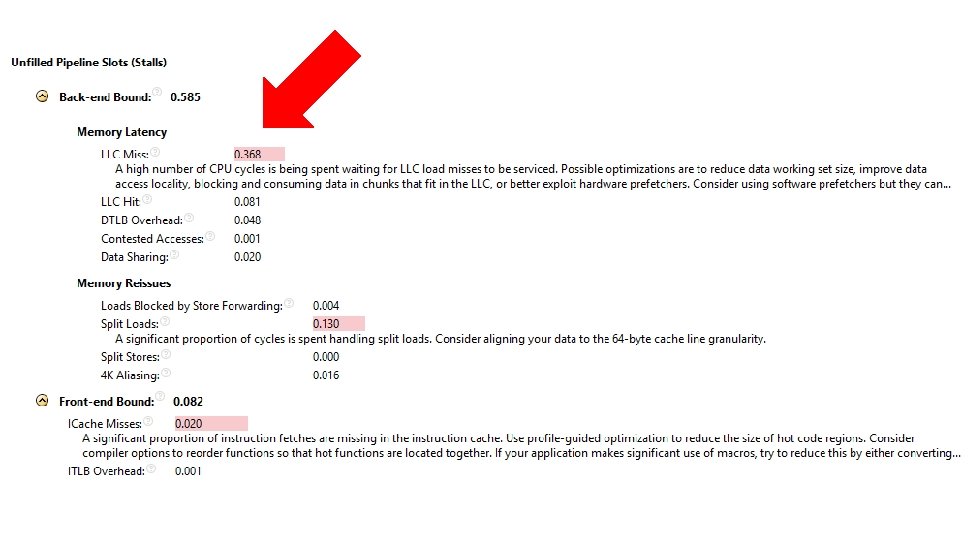
32 -bit float scalar CPU: 20 ms Mem: 20 ms 128 -bit SIMD Total: 40 ms Memory Bound 256 -bit SIMD Mem: 20 ms CPU: 80 ms CPU: 10 ms Mem: 20 ms Total: 30 ms Total: 100 ms 2. 5 x speedup 1. 3 x optimized CPU Highly speedup code isn’t CPU code.
Windows task manager won’t help you here
#3
§ Courtesy of http: //eigen. tuxfamily. org/ § § §
8. 5 ms enh yay 6. 4 ms this sucks 10 ms
struct My. Data { Vector 4 D v 1; // 4 floats Vector 4 D v 2; // 4 floats }; My. Data x; My. Data y; void func 2() { //. . . unrelated stuff. . . func 3(); //. . . unrelated stuff. . . x. v 1 = y. v 1; // 128 -bit copy x. v 2 = y. v 2; // 128 -bit copy x = y; // 256 -bit copy } This caused the 60% slowdown on Haswell
§ bugs deathly potholes
void func 1() { for (int i = 0; i<10000; i++) func 2(); } void func 2() { //. . . unrelated stuff. . . func 3(); //. . . unrelated stuff. . . x = y; // 256 -bit copy } void func 3() { //. . . unrelated stuff. . . . = x. v 1; // 128 -bit load from x } vmovups YMMWORD PTR [rbx], ymm 0 mov rcx, QWORD PTR __$Array. Pad$[rsp] xor rcx, rsp call __security_check_cookie add rsp, 80 ; 00000050 H pop rbx ret 0 push rbx sub rsp, 80 ; 00000050 H mov rax, QWORD PTR __security_cookie xor rax, rsp mov QWORD PTR __$Array. Pad$[rsp], rax mov rbx, r 8 mov r 8, rdx mov rdx, rcx lea rcx, QWORD PTR $T 1[rsp] mov rax, rsp mov QWORD PTR [rax+8], rbx mov QWORD PTR [rax+16], rsi push rdi sub rsp, 144 ; 00000090 H vmovaps XMMWORD PTR [rax-24], xmm 6 vmovaps XMMWORD PTR [rax-40], xmm 7 vmovaps XMMWORD PTR [rax-56], xmm 8 mov rsi, r 8 mov rdi, rdx mov rbx, rcx vmovaps XMMWORD PTR [rax-72], xmm 9 vmovaps XMMWORD PTR [rax-88], xmm 10 vmovaps XMMWORD PTR [rax-104], xmm 11 vmovaps XMMWORD PTR [rax-120], xmm 12 vmovdqu xmm 12, XMMWORD PTR __xmm@00000000 test cl, 15 je SHORT $LN 14@run lea rdx, OFFSET FLAT: ? ? _C@_1 FM@KGHGDLJC@ lea rcx, OFFSET FLAT: ? ? _C@_1 BIM@JPMPBING@ mov r 8 d, 78 ; 0000004 e. H call _wassert $LN 14@run: vmovupd xmm 11, XMMWORD PTR [rsi] vmovupd xmm 10, XMMWORD PTR [rsi+16]
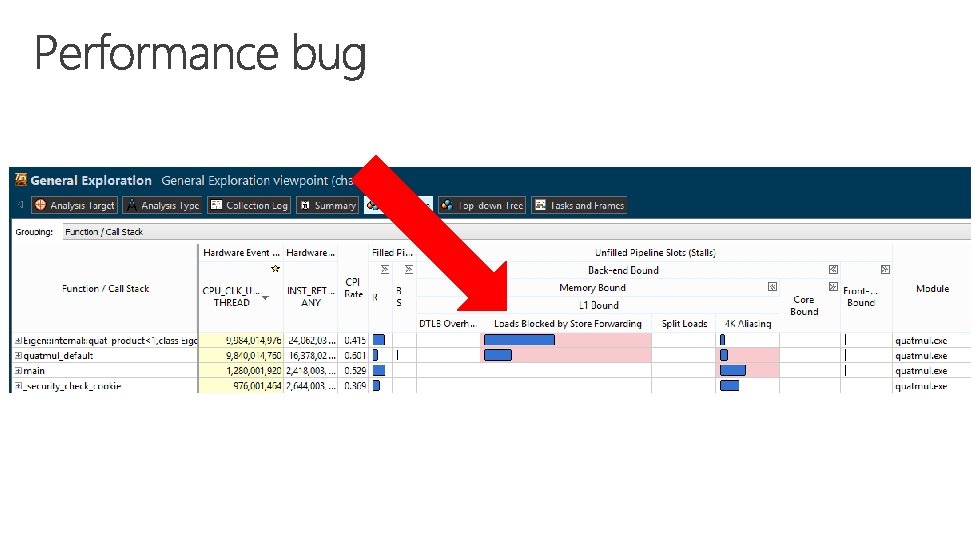
§ § The performance landscape is changing. Get to know your profiler.
Recap
Intel Pentium 3 (1999) AMD Athlon XP (2001) Intel Pentium 4 (2001) AMD Athlon 64 (2003) Intel Sandy Bridge (2011) AMD Bulldozer (2011) Intel Haswell (2013) Future AMD Chip (? ) Some 128 bit SIMD instructions FP 256 bit SIMD instructions /arch: SSE 2 /arch: AVX 2 Visual C++ ? Visual Studio. NET 2003 Visual Studio 2010 Visual Studio 2013 Update 2 (optimization support)
1. 2. 3.
Partner Program SPECIAL OFFERS for MSDN Ultimate subscribers Go to http: //msdn. Microsoft. com/specialoffers
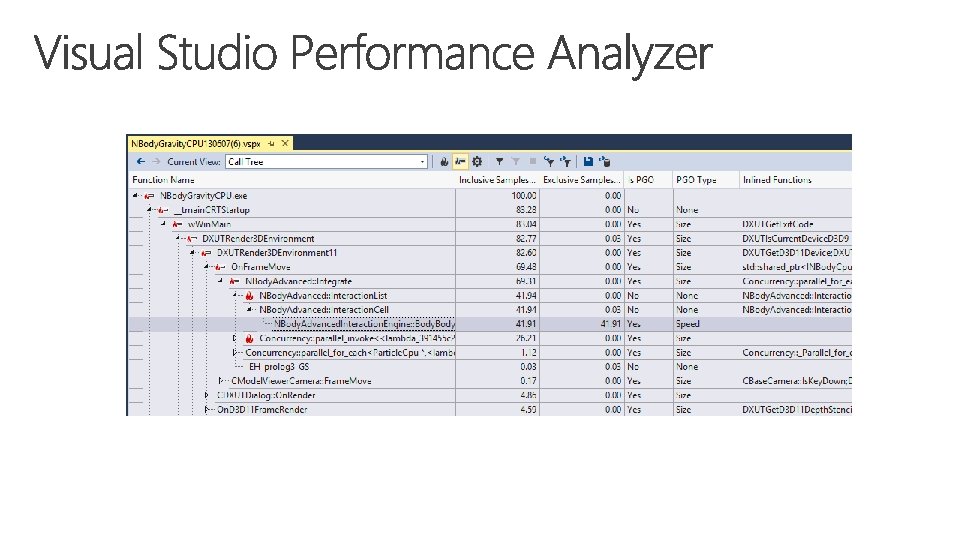
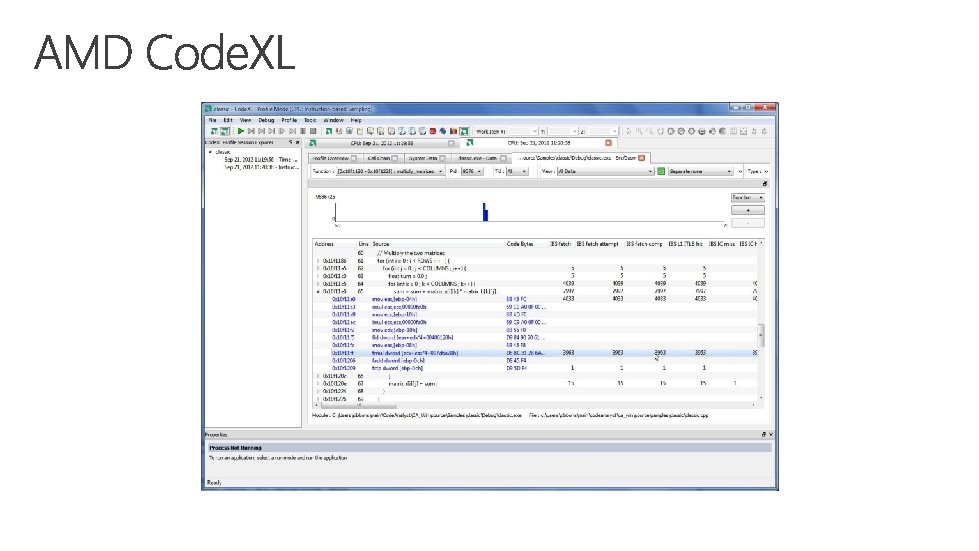
Profile your code
Profile your code