Contingency tables Brian Healy Ph D Types of

Contingency tables Brian Healy, Ph. D

Types of analysis-independent samples Outcome Explanatory Analysis Continuous Dichotomous Continuous Categorical Continuous Dichotomous Continuous t-test, Wilcoxon test ANOVA, linear regression Correlation, linear regression Chi-square test, logistic regression Logistic regression Time to event Dichotomous Log-rank test

Example n MS is known to have a genetic component n Several single nucleotide polymorphisms have been associated with susceptibility to MS n Question: Do patients with susceptibility SNPs experience more sustained progression than patients without susceptibility SNPs?

Data Initially, we will focus on presence vs. absence of SNPs n Among our 190 GA treated patients, 74 had the SNP and 116 did not n – 12 patients with the SNP experienced sustained progression – 13 patients without the SNP experienced sustained progression

Another way to look at the data n Rather than investigating two proportions, we can look at a 2 x 2 table of the same data SNP+ SNP- Total Prog 12 13 25 No prog 62 103 165 Total 74 116 190

Question n In our analysis, we assume that the margins are set n If there was no relationship between the two variables, what would we expect the values in the table be?

Example n As an example, use this table SNP+ Prog No prog Total 50*100/200 =25 50 SNP- Total 150*100/200= 75 100 150*100/200 =75 100 150 200

Expected table n Expected table for our analysis SNP+ Prog No prog Total SNP- Total 25*74/190= 9. 73 25*116/190 =15. 3 25 165*74/190 =64. 3 116*165/ 190=100. 7 165 74 116 190 How different is our observed data compared to the expected table?

Does our data show an effect? n To test for an association between the outcome and the predictor, we would like to know if our observed table was different from the expected table n How could we investigate if our table was different?

Chi-square distribution n This statistic follows a chi-square distribution with 1 degree of freedom n Assume x is a normal random variable with mean=0 and variance=1 – x 2 has a chi-square distribution with 1 degree of freedom

Chi-square distribution Area=0. 05 X 2=3. 84

Critical information for c 2 n For 1 degree of freedom, cut-off for a=0. 05 is 3. 84 – For normal distribution, this is 1. 96 – Note 1. 962=3. 84 n Inherently, two-sided since it is squared
 2) 3) 4) 5) 6) 7) H 0:")
Hypothesis test with c 2 1) 2) 3) 4) 5) 6) 7) H 0: No association between SNP and progression Dichotomous outcome, dichotomous predictor c 2 test Test statistic: c 2=0. 99 p-value=0. 32 Since the p-value is greater than 0. 05, we fail to reject the null hypothesis We conclude that there is no significant association between SNP and progression

p-value c 2 statistic

Hypothesis test comparison Yesterday, we completed this same test using a comparison of proportions n Let’s compare the results n Method Test statistic p-value Test of proportions c 2 test z=0. 996 p=0. 32 c 2=0. 992 p=0. 32 We get the same result!!!

Question: Continuity correction n What is a continuity correction and when should I use it? – Continuity correction subtracts ½ from the numerator of the c 2 statistic – Designed to improve performance of normal approximation – Use default in STATA (or other stat package), but know which you are using – Less important today since exact tests are easily used

Question: Why 1 degree of freedom? n We used a c 2 distribution with 1 degree of freedom, but there are 4 numbers. Why? – For our analysis, we assume that the margins are fixed. – If we pick one number in the table, the rest of the numbers are known SNP+ Prog No Prog Total SNP- 3 22 71 94 74 116 Total 25 165 190

Question: Normal approximation n We are using a normal approximation, but yesterday we talked about this being less than perfect. When can we use this test? – Rule of thumb: All cells larger than 5 – Large samples n What should I do if I do not have large samples? – Fisher’s exact test

Fisher’s exact test n n Remember that a p-value is the probability of the observed value or something more extreme Fisher’s exact test looks at a table and determines how many tables are as extreme or more extreme than the observed table under the null hypothesis of no association Same concept as exact test from Wilcoxon test Easy to compute this in STATA
 2) 3) 4) 5) 6) 7) H 0:")
Hypothesis test with exact test 1) 2) 3) 4) 5) 6) 7) H 0: No association between SNP and progression Dichotomous outcome, dichotomous predictor Exact test Test statistic: NA p-value=0. 38 Since the p-value is greater than 0. 05, we fail to reject the null hypothesis We conclude that there is no significant association between SNP and progression

Two-sided p-value

Results n Our results were very similar to the other tests in part because we have a large sample size – Normal approximation ok n In small samples, larger differences are possible

Types of studies n In a cohort study, people are enrolled based on exposure status so we can somewhat control how many exposed and unexposed people we have n In a case-control study, people are enrolled based on disease status so that we ensure that we have both diseased and non-diseased people

Measures of association n Risk difference – – – n Do these added together equal 1? Why? Under the null, what is the risk difference? Relative risk (risk ratio) – Under the null, what is the relative risk?

Exposure Disease Y N Total Y a b n 1 N c d n 2 Total m 1 m 2 N n P(Disease+|Exposure+)= a/m 1=p 1 – What is another name for this quantity? – Prevalence in patients with exposure P(Disease+|Exposure-)= b/m 2=p 2 n RD=a/m 1 – b/m 2 n Difference between proportions n

Confidence interval for RD n Several confidence intervals are available for the RD – Asymptotic normal distribution – Confidence interval

Exposure Disease Y N Total Y a b n 1 N c d n 2 Total m 1 m 2 N n Estimate of RR:

Confidence interval for RR n To construct a confidence interval we use a normal approximation n In addition, the CI is based on a log transformation of the RR – log(RR)=ln(RR) – I will use ln and log to represent the natural logarithm n Quick math: eln(RR)=RR
 n Why do we use the ln(RR)? – It is generally easier to")
ln(RR) n Why do we use the ln(RR)? – It is generally easier to deal with subtraction rather than division – ln(RR)=ln(p 1/p 2)=ln(p 1)-ln(p 2) n We can estimate the standard error for the ln(RR) using the following formula

Confidence interval n Now that we have an estimate of the variance, we can create a confidence interval for ln(RR) using our standard normal approximation n To create a confidence interval for RR, we transform this confidence interval

Estimated proportions in two groups Given the confidence interval, would you reject the null hypothesis? Why? p-value from chisquare test

Interpretation of RD n The estimated risk difference is 0. 05. n The 95% confidence interval for the risk difference is (-0. 052, 0. 152) – The interpretation of this is that the risk of progression for patients with the susceptibility allele is 5% higher than for patients without the allele – Is there a significant difference between the allele groups? n What was the confidence interval for the difference between the proportions that we investigated two classes ago? – 95% CI: (-0. 052, 0. 152)

Interpretation of RR n The estimated relative risk is 1. 45. – The interpretation of this is that the risk of progression for patients with the susceptibility allele is 1. 45 times higher than for patients without the allele n The 95% confidence interval for the risk difference is (0. 70, 3. 00) – Is there a significant difference between the allele groups?

RD and RR n Now that we know how to estimate these measures, can we estimate these with any study design? – Not directly – In a cohort study, the probabilities of interest, P(Disease|Exposure), are estimated – In a case-control study, the probabilities cannot be estimated directly so more information is required
 and P(Exposure| Disease) can be shown")
Bayes theorem-technical n The relationship between the P(Disease|Exposure) and P(Exposure| Disease) can be shown using Bayes theorem n Therefore, if we knew P(D+), we can estimate P(D+|E+) from a case control study – P(D+) is prevalence – Usually we do not know this so we can’t directly estimate the relative risk or risk difference

Odds ratio n Odds: n Odds ratio: – Under the null, what is the OR?

Exposure Disease Y N Total Y a b n 1 N c d n 2 Total m 1 m 2 N This is the estimate of the odds ratio from a cohort study

Exposure Disease Y N Total Y a b n 1 N c d n 2 Total m 1 m 2 N This is the estimate of the odds ratio from a case-control study

Amazing!! n Estimated odds ratio from each kind of study ends up being the same thing!!! n Therefore, we can complete a case control study and get an estimate that we really care about, which is the effect of the exposure on the disease n This relationship is why the odds ratio is so commonly

Confidence interval for OR n In order to calculate a confidence interval for the OR, we will investigate Woolf’s approximation – Other approximations and exact intervals are available in STATA (Exact is default) n Woolf’s approximation focuses in a log transformation of the OR like for the RR – log(OR)=ln(OR) n Quick math: eln(OR)=OR

n Woolf’s approximation gives us n Using our normal approximation, we can create a confidence interval for ln(OR) using n The confidence interval for OR

Example n In yesterday’s class, we discussed a study in which we wanted to estimate the effect of a SNP on disease progression – What type of study was this? – Cohort study because we followed people forward over time n Let’s estimate the odds ratio and confidence interval for this study

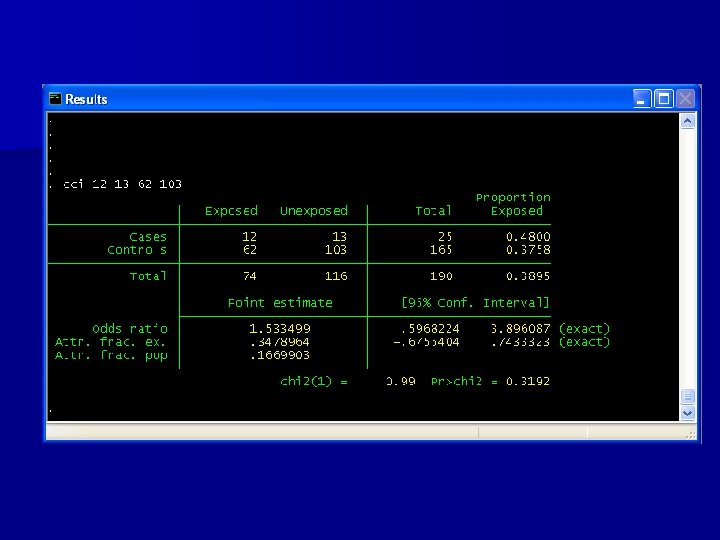
CI for OR Prog No prog SNP+ 12 62 SNP 13 103 Total 25 165 Total 74 116 190 Based on this table, the estimated OR=(12*103)/(13*62)=1. 53 n 95% CI: (0. 66, 3. 57) n Should we reject the null hypothesis of OR=1? n

Interpretation of OR n The estimated odds ratio is 1. 53. – The interpretation of this is that the ODDS of progression for patients with the susceptibility allele is 1. 53 times higher than the ODDS for patients without the allele n The 95% confidence interval for the risk difference is (0. 66, 3. 57) – Is there a significant association between SNP and disease?
")
Estimated OR Estimated CI (Woolf)

OR vs. RR Although the odds ratio is interesting, the relative risk is more intuitive n If we have a rare disease, which is often the case for a case-control study, n n Therefore, in these cases, the odds ratio is also an estimate of the relative risk n In other cases, odds ratio provides valid estimate of relative risk (see other courses)
 2) 3) 4) 5) 6) 7) H 0: No")
Hypothesis test with CI 1) 2) 3) 4) 5) 6) 7) H 0: No association between SNP and progression (RD=0) Dichotomous outcome, dichotomous predictor Risk difference 95% confidence interval Test statistic: Estimated RD=0. 50 95% CI: (-0. 052, 0. 152) p-value>0. 05 Since the p-value is greater than 0. 05, we fail to reject the null hypothesis We conclude that there is no significant association between SNP and progression
 2) 3) 4) 5) 6) 7) H 0: No")
Hypothesis test with CI 1) 2) 3) 4) 5) 6) 7) H 0: No association between SNP and progression (RR=1) Dichotomous outcome, dichotomous predictor Risk difference 95% confidence interval Test statistic: Estimated RR=1. 45 95% CI: (0. 70, 3. 00) p-value>0. 05 Since the p-value is greater than 0. 05, we fail to reject the null hypothesis We conclude that there is no significant association between SNP and progression
 2) 3) 4) 5) 6) 7) H 0: No")
Hypothesis test with CI 1) 2) 3) 4) 5) 6) 7) H 0: No association between SNP and progression (OR=1) Dichotomous outcome, dichotomous predictor Risk difference 95% confidence interval Test statistic: Estimated OR=1. 53 95% CI: (0. 66, 3. 57) p-value>0. 05 Since the p-value is greater than 0. 05, we fail to reject the null hypothesis We conclude that there is no significant association between SNP and progression
- Slides: 50